Label, Train & Deploy Browser Agents.
Track browser agent performance over time, surface failure modes quickly, and iterate infinitely against sandboxed web apps to build confidence without spamming live websites.
Request Early AccessBrowser agents fail. You have no idea why.
Building browser agents without visibility, training data, or benchmarks means shipping blind and improving by luck.
Failures are opaque
Are your browser agents getting stuck on captchas or silently failing on page loads? Without action-level tracing across browser sessions you're debugging blind, guessing at prompts, and hoping the next run works.
No training data
No way to capture what your agent actually did, label which actions were correct, or build datasets from real sessions. You're improving by instinct, not evidence.
Improvement is unmeasurable
You change the prompt. Is the agent better? Worse? There's no baseline. No version history. No way to A/B test GPT-4 against Claude on the same browser workflow. "V2 feels worse" is not a metric.
Built by the team behind Debugg.ai — 800+ users, 10,000+ agent tests/week
The missing layer between automation and production
Works with Playwright, Puppeteer, Selenium, browser-use, or any browser automation framework
Framework-agnostic. Works with your existing automation stack.
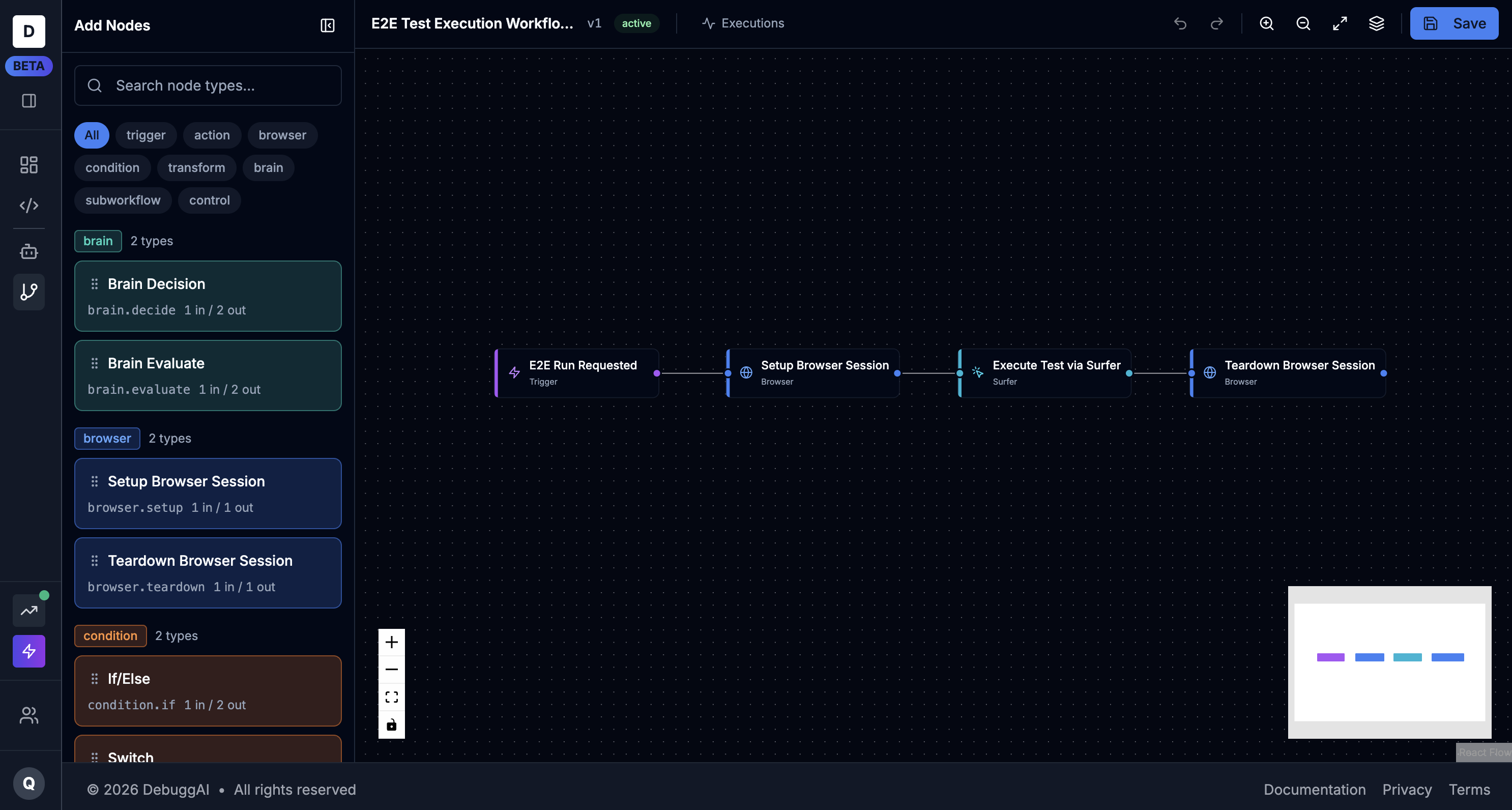
How it works
Design your browser agent
Build your agent visually in the Surfs workflow builder, or bring your own — browser-use, Playwright, Puppeteer, anything. No lock-in, no rewriting.
Run against sandboxed apps
Clone, build, or point Surfs at any web app and run your agent against it in a fully isolated environment. Iterate freely without touching live websites.
Fine-tune on real data
Every sandboxed session generates labeled training data from actual agent runs. Use it to fine-tune existing models or train agents that get measurably better.
Version and deploy
Every agent change is versioned. Benchmark new versions against old ones before shipping. Deploy with confidence when the data backs it up.
Track and monitor
Continuously monitor live agent sessions for failure modes, performance degradation, and regressions. Know when something breaks before your users do.
Automatically surface failure patterns
Action-level tracing across every browser session so you know exactly where agents get stuck, what triggers navigation failures, and how often they recur — without manually scrubbing through session recordings.

Safe, scalable training data
Deploy any web app into a sandboxed environment and run your agents against it as many times as you need — no risk of spamming live websites, no side effects, no limits on iteration.
Everything isolated for you
Connect your GitHub repo and we handle the rest — cloning, building, sandboxing, and running your agents. All automated, all isolated, all generating real training signal.
Fine-tune and train on real data
Every sandboxed session generates labeled training data from actual agent runs. Use it to fine-tune existing models or custom train agents that get measurably better over time.
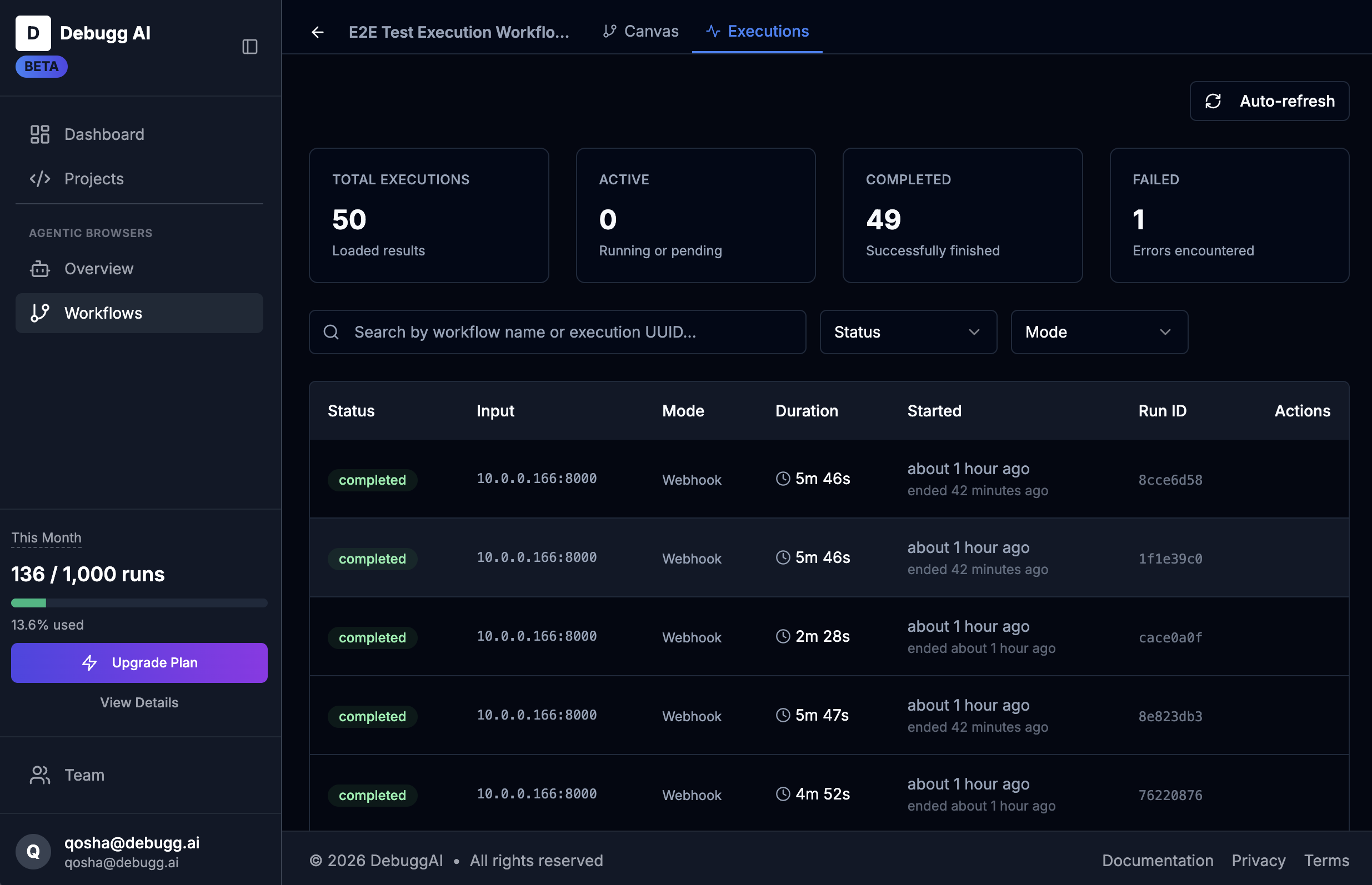
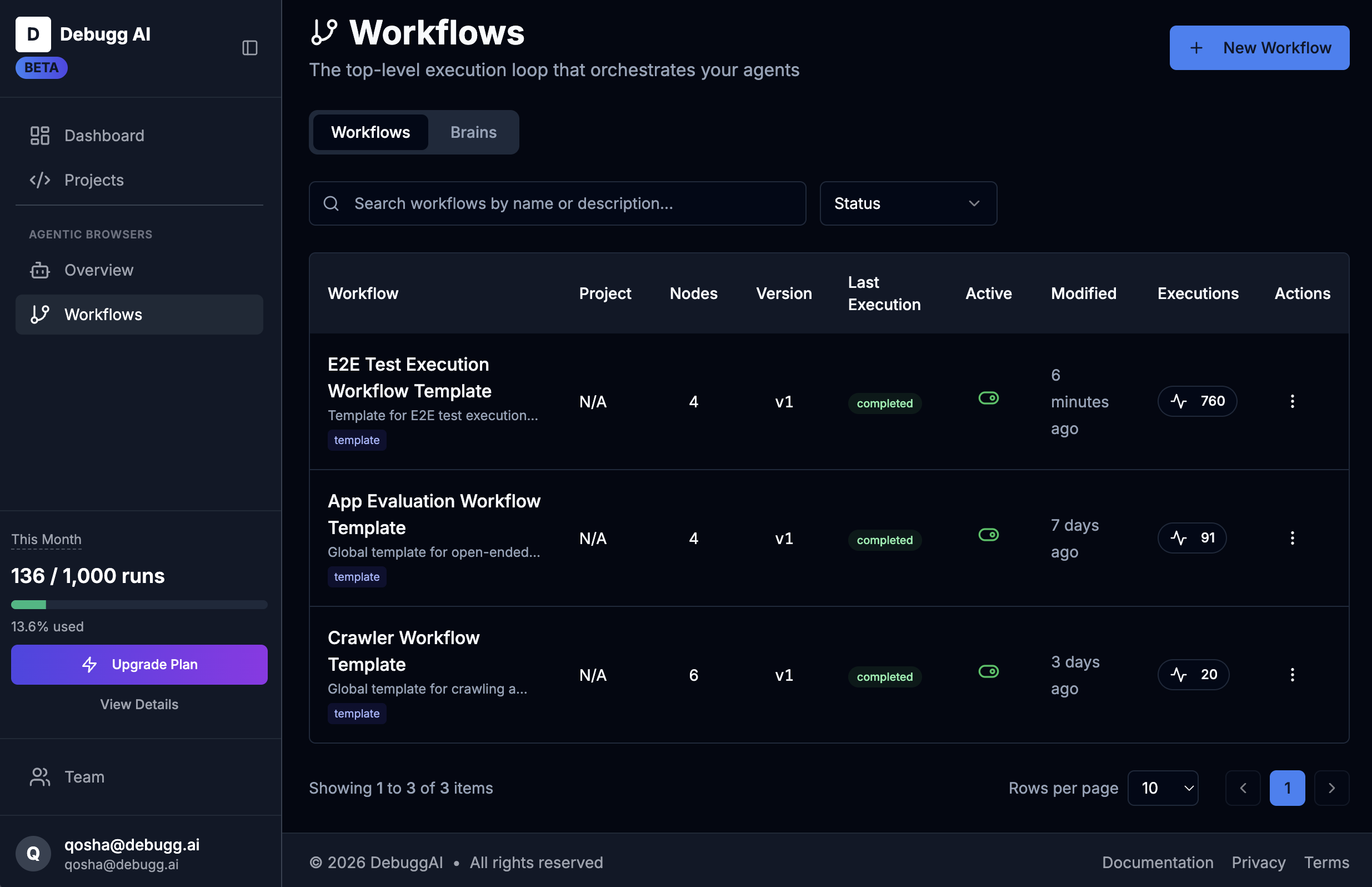
Benchmark and track improvements
Every agent deployment is versioned. Every prompt change is measured against a baseline. Run GPT-4 and Claude head-to-head on the same browser workflow and know with certainty which one wins.
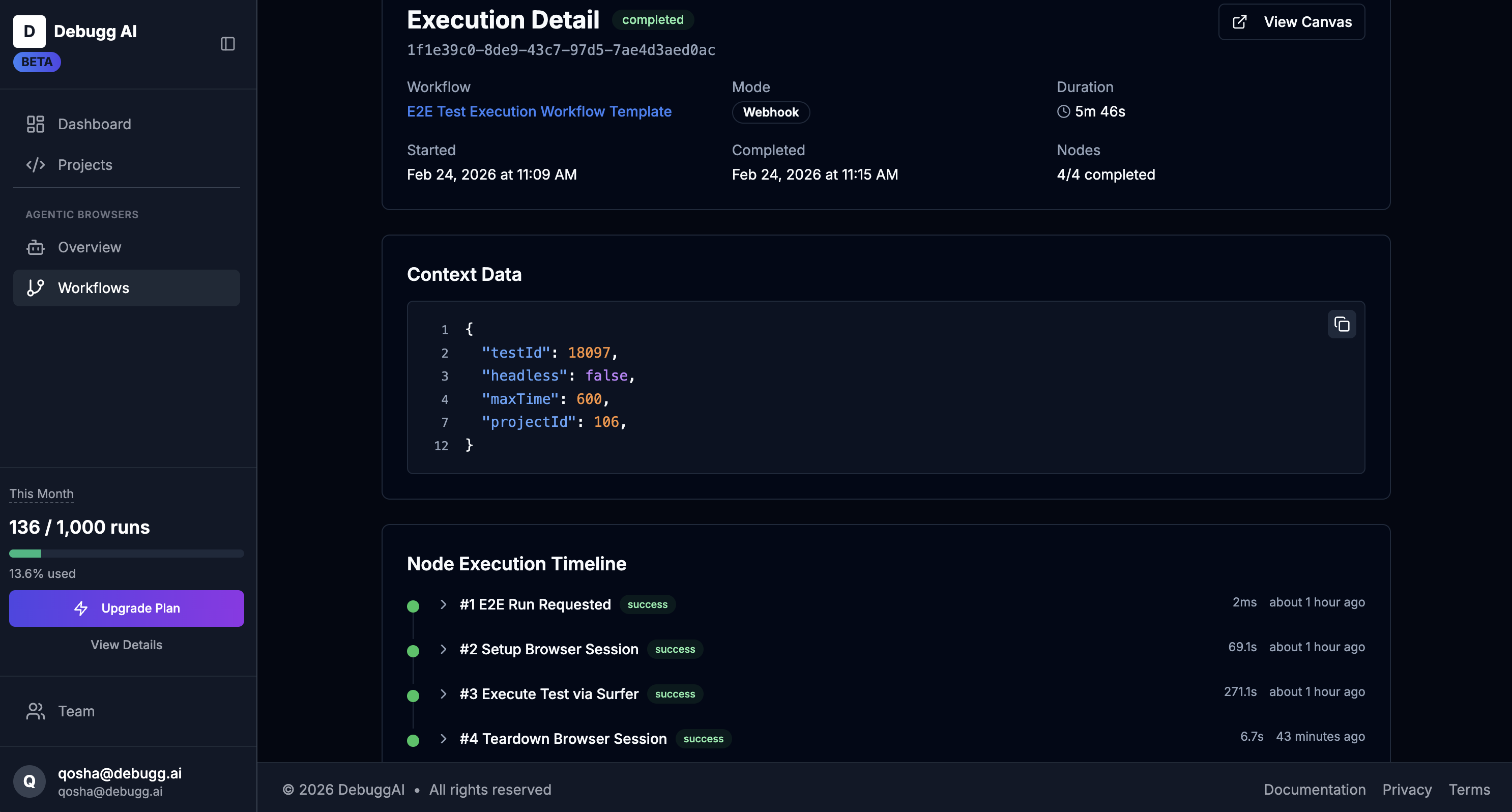
Version and deploy with confidence
Every agent change is versioned. Benchmark new versions against old ones before shipping. Deploy when the data backs it up — not when it feels right.
Start building browser agents
with confidence
Label, train, and deploy production-ready browser agents.
Request Early Access