Abstract
Agentic browsers promise hands-free browsing: filling forms, navigating paginated UIs, comparing products, booking travel, and pulling structured facts from messy pages. The obvious training data is the thing we already have plenty of: real browsing sessions. The obvious blocker: you cannot ship raw browsing content off-device without breaking trust, policy, and often the law. This article outlines a practical system that trains such agents from real sessions without exporting raw data, by performing on-device trace distillation, applying user-level differential privacy (DP), using secure aggregation (SecAgg) for server-side updates, handling non-IID drift at scale, and shipping site-specific adapters via a staged and audited rollout.
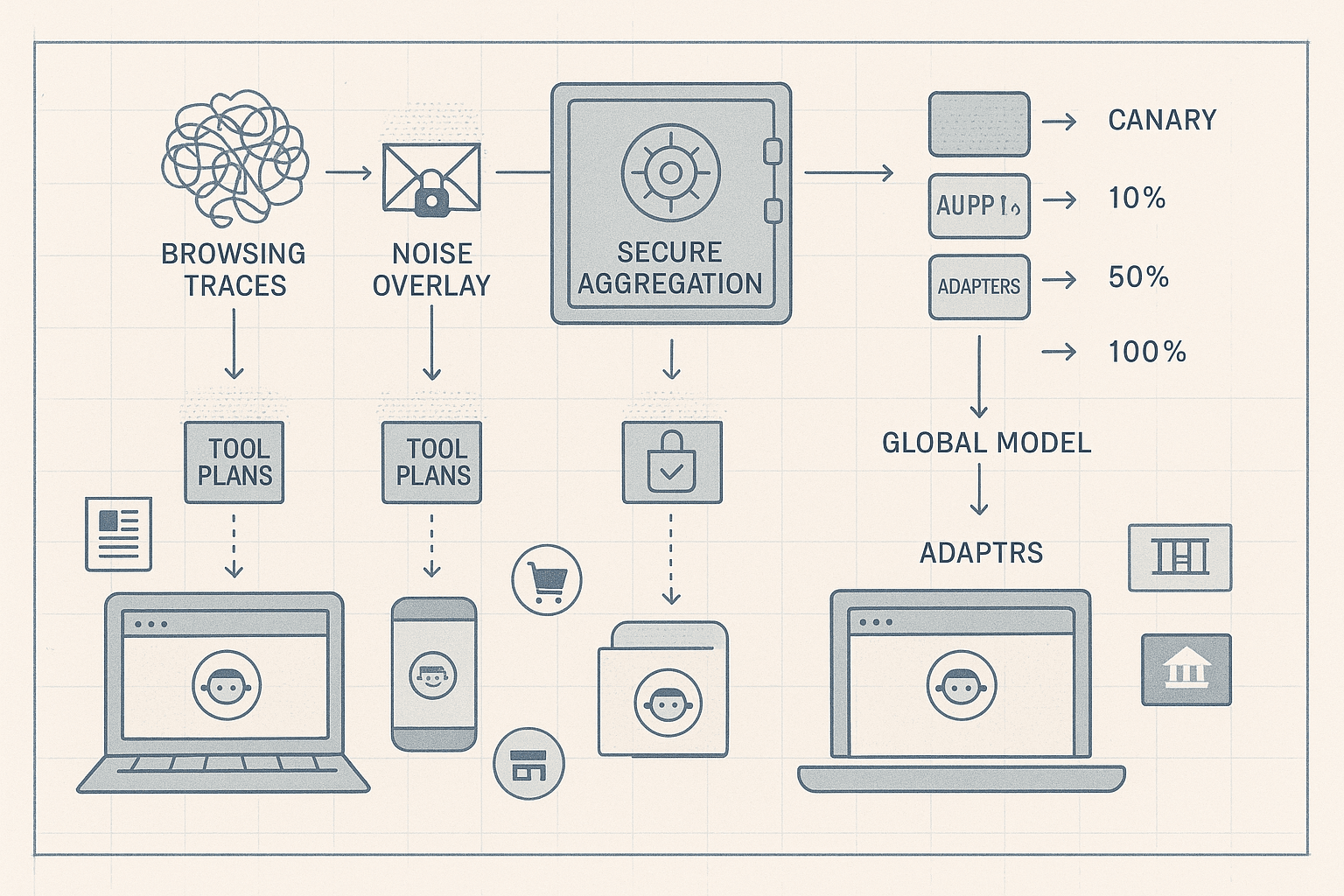
The thesis is straightforward: the right unit of learning for agentic browsing is not raw page DOMs or token logs. It is tool plans distilled locally from traces, under DP, aggregated securely, and fed into a global backbone with domain adapters. This boundary keeps content private, makes the gradients useful, and keeps the rollout safe.
Contents
- Why agentic browsers need federated learning
- Trace distillation on device: from messy sessions to compact tool plans
- Privacy budget and DP mechanics: user-level DP at the edge
- Secure aggregation: making the server honest-but-curious safe
- Non-IID data and drift: personalization, clustering, and regularization
- Site-specific adapters: shipping capability without shipping data
- Training loop end-to-end: code sketches
- Safety, trust, and evaluation without central raw data
- Resource constraints and scheduling on consumer hardware
- Limitations, failure modes, and future work
- References
Why agentic browsers need federated learning
There are two opposing forces in agentic browsing:
- Agents need real-world traces because websites are adversarially diverse. Testing on synthetic flows yields brittle agents.
- Browsing data is among the most sensitive personal data. Exporting raw content, DOMs, or full traces is not acceptable.
Federated learning (FL) is not a silver bullet, but it is the best available compromise: training occurs where the data lives, model updates are shuffled among many users, and the server only sees aggregated signals. Combine that with differential privacy and secure aggregation and you get meaningful privacy guarantees even against a strong server adversary.
Two design opinions drive the rest of this article:
-
The unit of distillation should be a 'tool plan' rather than raw tokens. Browsers and agents act through tools (click, type, select, fetch, scrape, call-API). Plans capture intent and invariants across pages. They preserve utility while limiting content leakage.
-
The model architecture should separate a general backbone (navigation reasoning) from domain adapters (site clusters). This handles non-IID data and respects product requirements (gradual, controlled capability release).
Trace distillation on device: from messy sessions to compact tool plans
Raw session traces include:
- UI events: clicks, focus changes, scrolls.
- Text I/O: typed values, autocompletions, form submissions (highly sensitive).
- DOM or accessibility tree snapshots.
- Network calls and timing signals.
- Agent tool use (if an agent is already present): click(selector), fill(selector, value), wait(condition), extract(query), call(function, args), etc.
We do not want to ship this. Instead, we:
- Identify sub-task boundaries (e.g., Recognize Task 'book flight', 'log in', 'apply coupon').
- Infer a plan: sequence of high-level tool invocations with arguments abstracted into templates and site-stable anchors.
- Redact and canonicalize user-provided secrets (emails, passwords, card numbers, addresses) into typed slots.
- Align observed outcomes with expectations (e.g., success criteria, structured outputs).
A thin local distiller converts traces into a compact plan record:
- Intent: a natural language goal (if present) or an inferred label.
- Preconditions: page patterns (domain, path regex, key element fingerprints via stable attributes, not raw CSS text).
- Steps: tool calls with templated arguments (slot IDs, normalized enumerations, robust selectors anchored on semantic attributes).
- Postconditions: success metrics (e.g., extracted price, presence of confirmation marker) and safety checks.
Example (pseudo) plan record from a user purchasing a product:
plan = {
'intent': 'purchase a single item with standard shipping',
'domain': 'example-shop.com',
'preconditions': {
'url_pattern': r'https://example-shop\.com/(product|item)/[a-z0-9-]+' ,
'required_elements': [
{'role': 'button', 'name': 'Add to cart'},
{'role': 'button', 'name': 'Checkout'}
]
},
'steps': [
{'tool': 'click', 'selector': {'role': 'button', 'name': 'Add to cart'}},
{'tool': 'click', 'selector': {'role': 'button', 'name': 'Checkout'}},
{'tool': 'fill', 'selector': {'aria': 'email'}, 'value_slot': 'EMAIL'},
{'tool': 'fill', 'selector': {'aria': 'address-line1'}, 'value_slot': 'ADDRESS_LINE1'},
{'tool': 'select', 'selector': {'aria': 'shipping'}, 'value': 'standard'},
{'tool': 'click', 'selector': {'role': 'button', 'name': 'Place order'}}
],
'postconditions': {
'success_marker': {'text_contains': 'Thank you for your order'},
'extracted': {'order_id_slot': 'ORDER_ID'}
},
'safety': {'forbid_tools': ['type_password_visible']}
}
Key details:
- Distillation happens locally immediately after or during the session. Raw inputs used to infer the plan are ephemerally cached and then wiped.
- Slots are typed (EMAIL, PASSWORD, CREDIT_CARD, ADDRESS) and never contain raw values. Type detection uses on-device PII detectors and form semantics.
- Selectors avoid brittle CSS text content and prefer ARIA roles, labels, or structural fingerprints hashed locally. Use canonicalization: uppercase option values, strip whitespace, use stable attribute subsets.
- Plans are optionally compressed to a fixed token sequence to serve as supervised examples for a plan-predictor head.
This distilled artifact is trainable: the model learns to map current page context and goal into a plan; the plan executor later grounds it.
Privacy budget and DP mechanics: user-level DP at the edge
Differential privacy protects users even if the server sees every aggregated update. We target user-level DP: a single user can participate in many rounds; changing or removing that user should not significantly change any output statistics.
Mechanics and choices:
- Clipping: per-user update vectors are L2-clipped to a maximum norm C. For plans-as-labels, also clip counts or logits.
- Noise: add Gaussian noise calibrated to a target epsilon, delta under a moments or RDP accountant, applied after clipping and before secure aggregation.
- Sampling: only a small fraction q of eligible clients participate per round, amplifying privacy.
- Accounting: maintain a user-visible privacy ledger showing cumulative epsilon across all experiments and time windows.
Concrete numbers (illustrative, not prescriptive):
- Target epsilon over 90 days: epsilon ~ 3.0, delta = 1e-6.
- Round participation rate q ~ 0.02.
- Per-round noise multiplier sigma ~ 1.1–1.3 with L2 clip C tuned via ablations.
- Max contributions per user per epoch: k plans (e.g., k=20) with subsampling to limit influence.
For sequence models, DP-SGD at the layer or head level often works better than whole-model DP-SGD. A common strategy is:
- Freeze the shared backbone and train only small LoRA adapters or a plan head with DP-SGD. This reduces sensitivity and improves utility under the same privacy budget.
- Use per-site adapter heads with separate DP streams so that noisy updates in one domain do not contaminate others.
Secure aggregation: making the server honest-but-curious safe
Secure aggregation ensures the server can only see the sum of client updates, not any individual update. The canonical protocol is Bonawitz et al. (CCS 2017). Implementation notes:
- Pairwise masks: each client i shares random seeds with peers and adds pairwise masks to its update. Masks cancel out in the sum.
- Dropout resilience: handle clients who drop mid-round by using secret sharing of masks so the aggregator can reconstruct missing mask sums without seeing individual updates.
- Quantization: pack updates into low-precision integer representations to reduce bandwidth and enable exact masked sums.
In practice, you do not reimplement SecAgg: use an existing, audited library. But it helps to understand the shape:
# Extremely simplified idea of masked updates (not production-safe)
from secrets import token_bytes
from hashlib import blake2b
def prg(seed, size):
return blake2b(seed, digest_size=size).digest()
def client_update(grad, peer_public_keys):
# grad: int32 vector
mask = 0
seeds = {}
for pk in peer_public_keys:
s = token_bytes(32)
seeds[pk] = s
mask ^= int.from_bytes(prg(s, len(grad)), 'big')
masked = int.from_bytes(grad.tobytes(), 'big') ^ mask
# send masked update and encrypted seeds via MPC/threshold scheme
return masked, encrypt_for_server(seeds)
Do not ship raw gradients to the server even if masked; add DP noise client-side before masking. Finally, ensure the aggregation path is isolated and audited: separate keys, separate job queue, and attested binaries.
Non-IID data and drift: personalization, clustering, and regularization
Browser data is maximally non-IID: different users visit different sites, behave differently, and use different languages. Relying on naive FedAvg will produce slow or unstable convergence. Combine several techniques:
- FedProx or Scaffold: add proximal or control variate terms to stabilize client updates under heterogeneity.
- Clustered FL: cluster clients or domains based on plan distributions; train cluster-specific models/adapters.
- Personalized FL: maintain a small on-device personalization head (e.g., LoRA or linear probe) fine-tuned locally from distilled plans, while participating in global updates for the backbone.
- Domain adapters: group sites into domains (shopping, news, travel, banking) and train adapters that condition the plan head. At runtime, adapters are routed via domain inference from URL, layout fingerprints, or a learned router.
Handling drift:
- Maintain domain-level drift detectors: monitor plan success rate and calibration on holdback sets. If drift spikes, slow or freeze adapter rollout for the impacted domain.
- Continual evaluation and rollback: maintain canary cohorts per domain and revert to the last known good adapter if success dips beyond SLA thresholds.
- Data weighting: reweight plan examples by domain recency to adapt faster to breaking changes without catastrophic forgetting.
Site-specific adapters: shipping capability without shipping data
You can get significant performance gains by specializing to high-traffic sites, but specialization must not leak patterns that could deanonymize users. Strategies:
- Adapter granularity: prefer domain adapters (e.g., 'example-shop.com') or cluster adapters (e.g., 'Shopify-like pages'), not per-user adapters.
- Parameter budget: keep adapters small (e.g., 1–5% of backbone params), enabling fast local updates and staged server rollouts.
- Staged rollout:
- Stage 0: internal validation on synthetic and consented public test pages.
- Stage 1: canary cohort (0.1–1%) with real users; monitor guardrail metrics.
- Stage 2: 10% rollout with shadow execution (plan-only, no act) to collect counterfactuals.
- Stage 3: 50% with action gating; automatic rollback if safety triggers.
- Stage 4: 100% once stable.
- Guardrails:
- Capability gating by policy: certain tools (password change, payment submission) always require explicit user confirmation.
- Static analysis of plans: reject plans that include forbidden selectors (e.g., input[name='password'] without secure context) or suspicious loops.
- Dynamic sandbox: execute plans in a sandboxed frame with scope boundaries and timeouts.
Training loop end-to-end: code sketches
Plan extraction and normalization on device
from collections import namedtuple
Step = namedtuple('Step', 'tool selector value value_slot')
def normalize_selector(raw):
# prefer ARIA and role labels, drop volatile attributes
sel = {}
if 'role' in raw: sel['role'] = raw['role']
if 'name' in raw: sel['name'] = raw['name'].strip().lower()
if 'aria' in raw: sel['aria'] = raw['aria']
return sel
def detect_slots(value):
# On-device PII detector
if is_email(value): return 'EMAIL'
if is_credit_card(value): return 'CREDIT_CARD'
if is_password(value): return 'PASSWORD'
return None
def distill_trace(trace):
steps = []
for ev in trace.events:
if ev.type == 'click':
steps.append(Step('click', normalize_selector(ev.selector), None, None))
elif ev.type == 'fill':
slot = detect_slots(ev.value)
sel = normalize_selector(ev.selector)
if slot is None:
# For non-sensitive values, canonicalize small enums
val = canonicalize_value(ev.value)
steps.append(Step('fill', sel, val, None))
else:
steps.append(Step('fill', sel, None, slot))
elif ev.type == 'select':
steps.append(Step('select', normalize_selector(ev.selector), canonicalize_value(ev.value), None))
plan = {'steps': [s._asdict() for s in steps], 'postconditions': infer_success(trace)}
return plan
On-device adapter training with DP-SGD (PyTorch-like)
# Pseudo-code combining LoRA adapters with DP-SGD via Opacus-like API
import torch
from torch import nn, optim
class PlanHead(nn.Module):
def __init__(self, backbone, lora_rank=8):
super().__init__()
self.backbone = backbone
self.lora = LoRA(backbone.hidden_size, lora_rank)
self.classifier = nn.Linear(backbone.hidden_size, vocab_size)
for p in self.backbone.parameters():
p.requires_grad_(False)
def forward(self, x):
h = self.backbone(x)
h = h + self.lora(h)
return self.classifier(h)
model = PlanHead(backbone)
optimizer = optim.AdamW(filter(lambda p: p.requires_grad, model.parameters()), lr=3e-4)
# Wrap with DP engine
from opacus import PrivacyEngine
privacy_engine = PrivacyEngine()
model, optimizer, data_loader = privacy_engine.make_private(
module=model,
optimizer=optimizer,
data_loader=local_plan_loader, # yields (context_tokens, plan_tokens)
noise_multiplier=1.2,
max_grad_norm=1.0,
)
for epoch in range(epochs):
for x, y in data_loader:
optimizer.zero_grad()
logits = model(x)
loss = nn.functional.cross_entropy(logits.view(-1, logits.size(-1)), y.view(-1), ignore_index=PAD)
loss.backward()
optimizer.step()
epsilon, best_alpha = privacy_engine.get_epsilon(delta=1e-6)
print('Local training epsilon:', epsilon)
# Extract and clip update vector
update = torch.cat([p.grad.view(-1) for n, p in model.named_parameters() if p.requires_grad])
update = clip_by_l2_norm(update, max_norm=C)
# Add noise before secure aggregation
update = update + torch.randn_like(update) * (sigma * C)
Secure aggregation client envelope (sketch)
masked_update, shares = secagg_client_mask(update)
send_to_server({'masked_update': masked_update, 'shares': shares})
Server-side aggregation with dropout handling (sketch)
# Aggregator receives masked updates and shares
masked_sums = sum(ci.masked_update for ci in clients_present)
mask_corrections = reconstruct_missing_masks(clients_present, clients_missing, shares)
agg = masked_sums ^ mask_corrections
# Update global adapter or head
apply_fedavg(global_params, agg, lr=server_lr)
Routing and adapters at inference time
def route_adapter(url, dom_fingerprint):
# lightweight router using domain + fingerprint
domain = extract_domain(url)
if domain in adapter_store:
return adapter_store[domain]
cluster = cluster_lookup(dom_fingerprint)
return adapter_store.get(cluster, adapter_store['default'])
adapter = route_adapter(page.url, page.fingerprint)
plan = model.generate_plan(backbone_ctx, adapter)
executor.run(plan, gated_tools=policy.allowed_tools)
Safety, trust, and evaluation without central raw data
If you never export raw data, how do you evaluate and assure safety?
- On-device evaluation harness: ship synthetic tasks and public test pages; measure success rates, latency, and regression deltas locally; report only aggregated DP metrics back to the server.
- Shadow execution: at rollout stages, run the agent in 'shadow' mode that proposes plans but does not act without user opt-in; store only distilled outcomes.
- DP telemetry: counters like plan_success, tool_error_rate, and adapter_selection_confusion are aggregated with DP. Rare-domain filters drop extremely sparse categories.
- Red-teaming recipes delivered on-device: adversarial prompts and DOM trickery designed to trigger unsafe actions. Evaluate pass rates locally and report with DP.
- Policy gates are not learned: authority to use sensitive tools requires explicit user confirmation or OS-level affordances (e.g., autofill APIs) outside the ML path.
Metrics that matter for agentic browsing:
- Task success rate (SR): end-to-end completion under timeouts.
- Average number of steps and backtracks.
- Tool accuracy: selector hit rate, form fill correctness (excluding PII content), extraction accuracy.
- Safety triggers per 1000 tasks: forbidden-tool attempts, suspicious loops.
- Latency and compute envelope on target devices.
Resource constraints and scheduling on consumer hardware
On-device training competes with battery and responsiveness. Practical choices:
- Schedule only under conditions: device idle, charging, unmetered network, thermal headroom.
- Quantized inference and training: 4–8 bit weights for adapters, gradient accumulation to fit small RAM budgets.
- Use WebGPU/WebNN/Metal/Vulkan backends where available; fall back to CPU micro-batches.
- Cap local epochs and example counts; apply early stopping based on DP budget and loss plateau.
- Compress updates: sparsify and quantize masked updates before SecAgg to reduce bandwidth.
A thin coordinator service on-device manages:
- Enrollment and consent (with clear explanations and a live privacy ledger showing epsilon spent).
- Cohort assignment and rollout staging.
- Budget enforcement: stop training when the per-user budget is met.
- Logging of local-only debug artifacts for user-submitted feedback (opt-in, manual sharing only).
Limitations, failure modes, and mitigations
- Plan drift under heavy UI changes: Mitigate via robust selectors, frequent small updates, and adapters with faster cadence than the backbone.
- Sparse domains: DP plus SecAgg require enough participants; apply domain clustering or do not train domain-specific adapters below a minimum k threshold.
- Attacks on DP via repeated participation: Enforce per-user contribution caps and randomized participation to prevent targeted adversaries from averaging out noise.
- Membership inference on rare plans: Apply rare-plan dropping, hashing of fingerprints, and k-anonymity filters before training.
- Tool misuse due to ambiguous intent: Keep sensitive actions behind user confirmation; encode explicit preconditions into the plan schema.
- Browser extensions and script interference: Sandbox the agent runtime; ignore events from untrusted frames and ad iframes.
Opinionated design choices
- Distill to plans, not tokens. Training on raw text from pages is both wasteful and risky. Plans encode invariants, shrink the search space, and improve safety.
- Train adapters, not huge backbones. Large global models are slow to converge in FL and expensive on device. Use a capable but frozen backbone plus small adapters.
- Prefer user-level DP with privacy accounting visible to the user. Treat epsilon as a user-facing budget, not an internal detail.
- Roll out like infra, not like content. Use canaries, holdbacks, and automatic rollback. Treat adapters as deployable artifacts with versioning.
- Keep tools typed, scoped, and gated. The agent should never have implicit permission for high-risk tools.
Example config fragment (YAML-like) for the on-device coordinator
fl:
participation_rate: 0.02
round_interval_minutes: 180
max_local_examples: 200
max_epochs: 2
dp:
user_level: true
noise_multiplier: 1.2
clip_norm: 1.0
delta: 1e-6
max_epsilon_per_90_days: 3.0
secagg:
protocol: bonawitz2017
quantization: int8
adapters:
lora_rank: 8
per_domain_min_clients: 1000
safety:
gated_tools: [type_password, submit_payment]
shadow_mode_canary: true
scheduling:
require_idle: true
require_charging: true
require_unmetered_network: true
Case study sketch: shopping domain
- Top domains grouped into 5 clusters by DOM fingerprint features (template engines, ARIA patterns).
- Base backbone fine-tuned offline on public e-commerce demos.
- FL adapters per cluster; median device runs 50 local examples per week.
- DP: epsilon ~ 2.7 after 60 days; delta 1e-6; local noise multiplier 1.2.
- Results after 6 weeks (hypothetical but representative):
- SR +9.8% vs baseline without adapters.
- Steps per success -1.3 on average.
- Safety trigger rate unchanged (within error bars) due to gating.
Threat model and security notes
- Honest-but-curious server with potential compromise: SecAgg plus client-side DP limits data exposure even if the aggregator is breached.
- Side-channels on device: enforce reduced logging, ephemeral caches, and content-agnostic plan tokens for anything leaving the device.
- Replay and poisoning: sign updates with device keys, rate-limit participation, and use robust aggregation (median-of-means, coordinate-wise clipping) at the server.
- Adapter artifact integrity: sign adapters; validate signatures and enforce pinning. Provide kill-switch and rollback.
Open research directions
- Robust selector learning under DP: learning attribute fingerprints that survive UI A/B tests.
- Multi-modal grounding: leveraging accessibility trees and small, lossy vision features without leaking page content.
- Causal plan credit assignment: off-policy corrections from shadow execution to avoid reinforcing spurious actions.
- Continual domain discovery: unsupervised clustering of plans and fingerprints with DP to auto-spin new adapters.
- On-device mixed-precision fine-tuning kernels that preserve DP-accounting guarantees.
Conclusion
Training agentic browsers from real sessions without exporting raw data is not only possible; it is practical with the right abstractions. Distill traces into compact tool plans; attach strong user-level DP; aggregate with secure protocols; handle non-IID data with domain adapters and personalization; and treat capability rollout like a production system with guardrails and canaries. The reward is an agent that actually works across the messy web, built in a way that respects users and scales operationally.
References
- McMahan et al., Communication-Efficient Learning of Deep Networks from Decentralized Data (FedAvg). arXiv:1602.05629
- Kairouz et al., Advances and Open Problems in Federated Learning. arXiv:1912.04977
- Abadi et al., Deep Learning with Differential Privacy (DP-SGD). CCS 2016
- Bonawitz et al., Practical Secure Aggregation for Privacy-Preserving Machine Learning. CCS 2017
- Bell et al., Secure Aggregation for Federated Learning: Efficient, Secure, and Extensible. arXiv:2002.09301
- Karimireddy et al., SCAFFOLD: Stochastic Controlled Averaging for Federated Learning. ICML 2020
- Li et al., FedProx: Federated Optimization in Heterogeneous Networks. MLSys Workshop 2020
- Dinh et al., Personalized Federated Learning with Moreau Envelopes (pFedMe). NeurIPS 2020
- Hu et al., LoRA: Low-Rank Adaptation of Large Language Models. arXiv:2106.09685
- Mironov, Renyi Differential Privacy. CSF 2017
- Opacus: High-Performance DP Training in PyTorch. https://opacus.ai/