Introduction
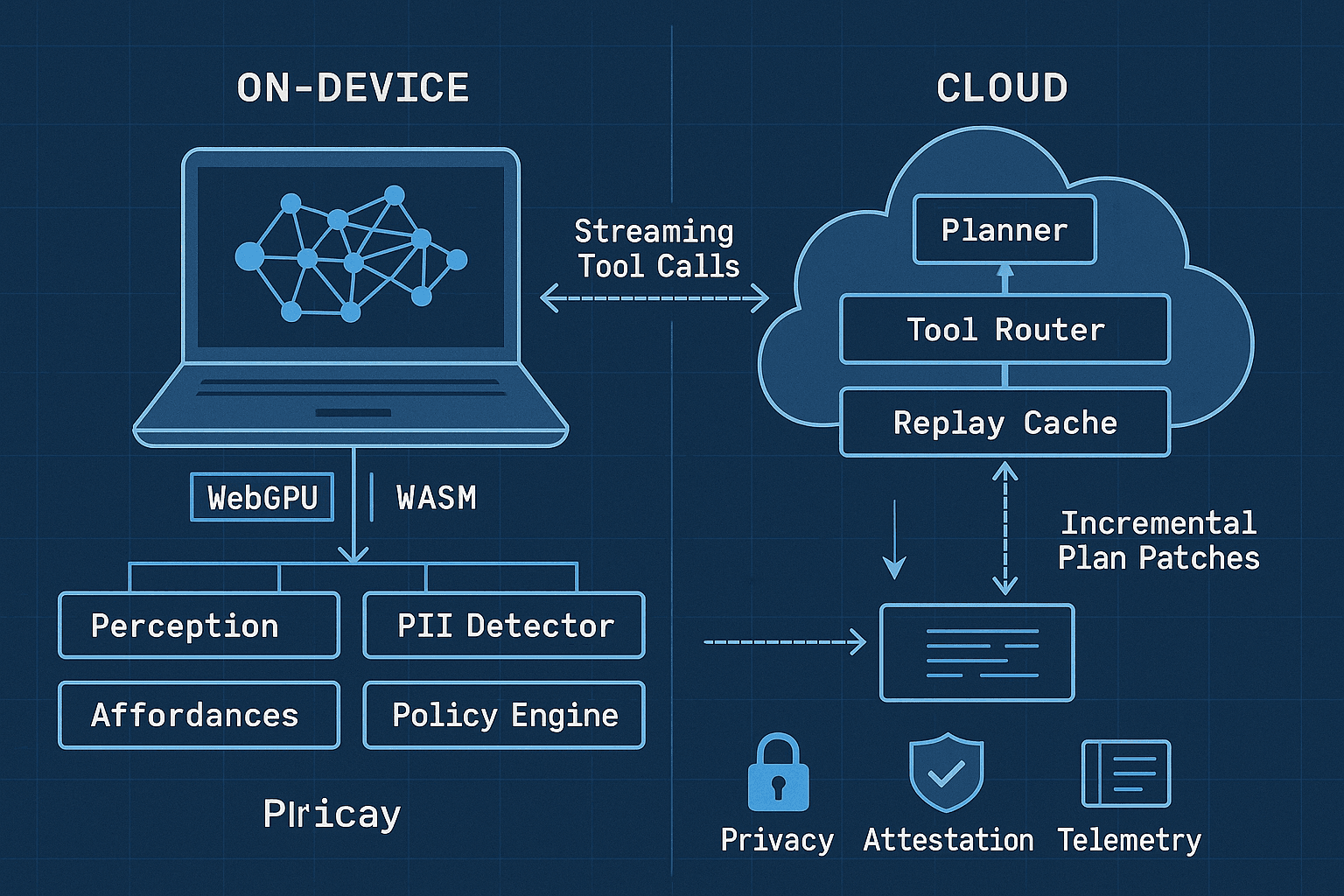
Agentic browsers are moving from novelty demos to production tools. They navigate sites, fill forms, scrape structured data, and execute workflows end-to-end—often faster and more reliably than manual RPA scripts. The challenge is doing this safely and responsively, without monopolizing compute or leaking sensitive data. A hybrid approach—on-device perception and affordances, with cloud-assisted planning—offers the best of both worlds.
This article lays out a split-brain pipeline for agentic browsing:
- On-device WebGPU/WASM models handle fast, privacy-preserving perception tasks: DOM summarization, clickable affordance detection, form semantics, and low-latency PII detection/redaction.
- A cloud LLM handles hard planning and long-horizon strategy, using streamed tool calls and incremental plan patches.
- Plans are cached, diffed, and patched as the page evolves, avoiding full recomputation.
- A policy engine mediates data exfiltration, tool privileges, and escalation. Escalations are gated by user consent and accompanied by attested telemetry to build trust and enforce accountability.
We’ll cover architecture, concrete implementation patterns, code snippets, performance tradeoffs, and a pragmatic threat model. The audience is technical; assume familiarity with LLM function-calling, WebGPU, and browser extension APIs.
Why Hybrid? Latency, Privacy, and Cost
- Latency: On-device inference is sub-50 ms for compact models and avoids network round trips. This matters for tight perception/action loops (e.g., confirm a button label changed before the next click).
- Privacy: PII detection and redaction must run locally. A cloud planner only sees minimal, policy-approved context, not raw pages or credentials.
- Cost: Heavy planning can be bursty; pay for it when necessary. Keep the hot path on-device to reduce tokens and calls.
- Robustness: Offline or flaky networks should still permit basic UI understanding and stateful retries later.
System Overview: Split-Brain Agentic Browser
Components
- Orchestrator (content script + worker): Coordinates perception, planning, tool invocation, and policy checks.
- On-device perception model (WebGPU/WASM): Extracts affordances (clickables, forms), summaries, and state features. Also runs PII detector/redactor.
- Cloud planner (LLM microservice): Builds or patches high-level plans, streams tool calls, and returns partial updates.
- Tool layer: Executes safe browser actions (click, type, select, scroll, waitFor, download), plus HTTP, GraphQL, or app-specific APIs.
- Plan cache: IndexedDB cache keyed by URL + DOM signature + intent. Supports patching and replay.
- Policy engine: Declarative rules to gate data flow and tool privileges. Generates consent prompts and redacts context.
- Telemetry & attestation: Structured logs, device-bound signing, and consent receipts.
Informal data flow
- User issues intent (e.g., "Download latest invoice from Acme").
- On-device model perceives current page -> affordance graph + summary + PII map.
- Orchestrator checks policy. If low-risk, ask cloud planner for a plan, streaming function calls.
- Tool layer executes calls with retries and safety checks.
- Plan cache stores the plan and deltas keyed by page signature.
- If the planner requests sensitive context, orchestrator enforces policy-gated escalation with consent and attested telemetry.
Split of responsibilities
- On-device: Low-latency, local context extraction; stable element targeting; PII detection; incremental DOM delta features; heuristic micro-steps; safety guards.
- Cloud: Task decomposition, robust recovery, cross-site strategies, schema induction, long-horizon constraints, and advanced tool routing.
On-Device Inference Stack: WebGPU + WASM
WebGPU gives efficient tensor ops (matmul, attention) with lower overhead than WebGL. Three practical pathways exist today:
- Transformers.js with WebGPU backend: Great for small text encoders/decoders and embeddings.
- ONNX Runtime Web (ORT-web) with WebGPU EP: Load quantized ONNX models, including small sequence models and classifiers.
- MLC/TVM WebLLM: In-browser LLMs for small chat models; supports int4 quantization and caching compiled kernels.
Model selection
- Affordance encoder (tiny transformer, ~30–100M params int4): Produces element embeddings + classification for clickability, role, and risk.
- DOM summarizer (small encoder-decoder or extractive summarizer): Creates ~512–1024 token summaries describing tasks and landmarks.
- PII detector (regex+tiny classifier): Hybrid to keep FP/FN low; use lexicons for email, phone, addresses, but ML to catch context ("invoice number").
Memory budget and performance
- Aim for <300 MB GPU memory to avoid eviction on integrated GPUs. Int4 quantization with groupwise scales helps.
- Pin models in a dedicated worker and prewarm kernels on extension load.
- Expect ~2–10 ms for element classification over 500–1500 nodes with batching; ~20–40 ms for summarization under 1k tokens.
Code: Affordance extraction with ORT-web + WebGPU
javascript// content-script-worker.js import { InferenceSession, Tensor } from 'onnxruntime-web/webgpu'; let session; export async function initAffordanceModel(modelUrl) { session = await InferenceSession.create(modelUrl, { executionProviders: ['webgpu'] }); } export async function extractAffordances(domFeatures) { // domFeatures: Float32Array of shape [N, D] featurizing DOM nodes (role, a11y, bbox, styles, text hash, etc.) const input = new Tensor('float32', domFeatures, [1, domFeatures.length / 128, 128]); const outputs = await session.run({ input }); // outputs.logits shape: [1, N, C] with classes: clickable, input, risky, nav, etc. const logits = outputs.logits.data; return postProcess(logits); }
The featurizer should combine cheap heuristics with embeddings. You can hash text to avoid sending raw content across threads, then map top-k hashes to token IDs only when local policy allows.
DOM featurization hints
- Accessibility tree fields: role, name, describedby, aria attributes.
- Layout: bounding boxes, z-index, overlap ratio, visibility.
- Text: BPE hash or minhash of innerText; length bins; font weight; contrast.
- Linkage: parent role, sibling types, distance to nav landmarks.
- Historical success: element selectors used previously (for plan patching).
Perception outputs
- Affordance graph: nodes (element IDs) with probabilities and roles; edges for containment and likely workflows (e.g., search box -> search button).
- Page summary: a concise description with named landmarks and candidate actions.
- Risk map: PII entities and confidence (kept local unless redacted).
Speculative Planning and a Minimal Plan DSL
A key idea: plan when idle. Even before the user confirms an intent, generate skeleton plans keyed by the URL + DOM signature. On intent, patch the plan with user-specific parameters.
Define a compact PlanScript DSL that’s safe to interpret in the browser:
yamlversion: 1 meta: site: "https://acme.com/billing" page_sig: "sha256:9d2a..." intent: "download_latest_statement" steps: - find: { role: "button", text_like: "Sign in" } action: click guards: [ { present: { role: "textbox", name_like: "Email" } } ] - fill: { query: { role: "textbox", name_like: "Email" }, value: "$USER_EMAIL" } - fill: { query: { role: "textbox", name_like: "Password" }, value: "$SECRET:ACME_PASSWORD" } - click: { query: { role: "button", text_like: "Log in" } } - wait_for: { url_like: "/dashboard" } - navigate: { query: { role: "link", text_like: "Statements" } } - click: { query: { role: "button", text_like: "Download" }, variant: "latest" } - expect_download: { mime_like: "application/pdf" }
Guidelines
- Queries are over the affordance graph (not raw selectors); fallback to deterministic selectors only after element resolution.
- Guards are cheap predicates executed locally to ensure safety before performing irreversible actions.
- Secrets are referenced symbolically; resolution happens via the policy engine.
Streaming Tool Calls from the Cloud Planner
The planner produces a plan incrementally and may emit tool calls (function calls) mid-stream. Use WebSocket or SSE. Each tool call is idempotent, carries a causal step ID, and returns structured results.
Minimal tool schema
json{ "tools": [ { "name": "query_affordances", "description": "Search the local affordance graph using a structured query.", "parameters": { "type": "object", "properties": { "role": { "type": "string" }, "text_like": { "type": "string" }, "name_like": { "type": "string" } }, "additionalProperties": false } }, { "name": "act", "description": "Execute a safe browser action (click, fill, wait_for, navigate).", "parameters": { "type": "object", "properties": { "action": { "enum": ["click", "fill", "wait_for", "navigate"] }, "query": { "type": "object" }, "value": { "type": "string" } }, "required": ["action", "query"], "additionalProperties": false } } ] }
Client-side stream handling (pseudo-code)
javascriptconst ws = new WebSocket(CLOUD_PLANNER_URL); ws.onmessage = async (evt) => { const msg = JSON.parse(evt.data); switch (msg.type) { case 'plan_patch': applyPlanPatch(msg.patch); // JSON-Patch over PlanScript break; case 'tool_call': if (!policy.permitTool(msg.tool, msg.args)) return deny(msg.id, 'policy'); const result = await runTool(msg.tool, msg.args); // local, not sent unless allowed const redacted = policy.redact(result); ws.send(JSON.stringify({ type: 'tool_result', id: msg.id, result: redacted })); break; case 'escalation_request': await handleEscalation(msg.request); // consent + attested telemetry break; } };
Plan Caching, DOM Signatures, and Patching
Cache plans in IndexedDB by a composite key:
- site origin
- normalized URL path (query stripped unless whitelisted)
- DOM signature = stable hash based on:
- accessibility landmarks (roles and order)
- top-k text tokens (minhash) for headings/navigation
- structure sketch (e.g., coarse XPath histogram)
Example schema
javascript// idb: plans[origin][path][intent][dom_sig] = { plan, createdAt, successStats }
On navigation or DOM mutation, compute a new signature and fetch the nearest neighbor plan using LSH. When mismatched, request a plan_patch from the cloud, sending only:
- anonymized affordance graph schema (counts and roles)
- hashed text tokens
- previous plan IDs
Patch format: JSON Patch (RFC 6902) with PlanScript-specific operations. Example patch
json[ { "op": "replace", "path": "/steps/2/fill/query/name_like", "value": "User ID" }, { "op": "add", "path": "/steps/6", "value": { "wait_for": { "role": "status", "text_like": "Processing" } } } ]
Cache invalidation rules
- Evict by LRU and by stale successStats.
- Invalidate on major layout churn (Jaccard distance over roles > 0.4) or auth state transitions.
- Prefer patching over regeneration to keep token costs low.
Policy-Gated Escalation and Attested Telemetry
Policy is the safety boundary. It must be explicit, testable, and explainable. Define a JSON policy language or reuse Rego (OPA). Focus on:
- Data classification: What data classes (PII, credentials, health, finance) exist in page context?
- Tool privileges: Which actions are allowed given the data class and site trust level?
- Escalation: Under what conditions can redacted context be sent to the cloud? What consent UX is required?
Example policy (JSON)
json{ "version": 1, "domains": { "acme.com": { "trust": "high", "allow": ["click", "fill", "wait_for", "navigate"], "deny": ["download_raw_dom"], "redact": ["password", "ssn", "credit_card"], "escalation_rules": [ { "condition": { "needs_cloud_planning": true, "contains_pii": true }, "requires": ["user_consent", "attested_telemetry"], "context": ["affordance_schema", "hashed_tokens", "plan_id"] } ] } }, "defaults": { "trust": "unknown", "allow": ["query_affordances"], "deny": ["act_fill_secret"], "redact": ["all_pii"], "escalation_rules": [ { "condition": { "needs_cloud_planning": true }, "requires": ["user_consent"] } ] } }
Enforcement loop
- Classify page context locally (PII detector + heuristics).
- Resolve the site’s policy block and merge with defaults.
- For each planner request, evaluate allow/deny. If deny, return a policy error token.
- If escalation is needed, show a consent sheet with a structured summary of what will be shared.
- Attach attested telemetry to the escalation record.
Attested telemetry in practice
Fully trustworthy attestation in a pure web context is limited. Still, we can raise the bar:
- Supply-chain proofs: Subresource Integrity (SRI) for models and WASM; signed manifests; transparency logs.
- Device-bound keys: Use WebAuthn to generate a device-bound key; sign telemetry digests locally. The RP ID should be your domain; include a nonce and policy snapshot hash.
- Platform claims (optional): On mobile apps or desktop helpers, use OS attestation (Android Key Attestation, iOS DeviceCheck) to bind keys to hardware-backed stores.
- Consent receipts: Store a signed receipt in IndexedDB and in your backend, linking plan_id, policy hash, and redaction summary.
Telemetry payload example
json{ "plan_id": "pln_7f3...", "policy_hash": "sha256:1a2b...", "context_summary": { "affordances": { "buttons": 12, "inputs": 5, "links": 27 }, "hashed_tokens": ["t:ab12", "t:09ff", "t:77ac"], "pii_classes": ["email", "password"] }, "consent": { "granted": true, "timestamp": 1739549501 }, "signature": { "alg": "ES256", "x5c": ["webauthn-attested-cert-..."], "sig": "MEUCIG..." } }
Security and Privacy Considerations
Threat model highlights
- Exfiltration: Planner solicits sensitive DOM data. Mitigation: local PII redaction, hashed tokens, policy rules, user consent, telemetry.
- Prompt injection: Malicious pages alter perceived goal. Mitigation: anchor intent to user instruction; treat page text as untrusted; train local classifier for injection patterns ("ignore previous instructions").
- Selector hijacking: Dynamic IDs or duplicate text cause misclicks. Mitigation: multi-signal target resolution (role + text + position + history), guarded actions, and post-action verification.
- CSRF-like behaviors: Agent triggers side effects on a third-party origin. Mitigation: origin-scoped allowlist and escalating to user for non-idempotent operations.
- Replay and TOCTOU: Using stale plans on changed pages. Mitigation: DOM signatures and guards; re-validate before irreversible steps.
Privacy techniques
- Local-only PII detection with hybrid rules (regex + ML). Keep raw text local; share only token hashes under policy.
- Secret handling: Secrets resolved by the policy engine and typed into fields using OS autofill APIs if possible.
- Minimization: Cloud planner receives the least context needed to plan (affordance schema, hashed tokens, prior plan). Raw screenshots and DOM dumps are forbidden by default.
Tooling the Agent: Safe Browser Actions
Expose a minimal, deterministic action set with postconditions and timeouts. Each action should:
- Execute against resolved element handles derived from the affordance graph.
- Validate a postcondition (e.g., URL changed, element detached, text appeared) locally.
- Return structured results with evidence (before/after features) for planner feedback.
Example action wrapper
javascriptasync function click(query, { timeout = 3000 } = {}) { const target = await resolveQuery(query); // Uses affordance graph + heuristics if (!target || !isVisible(target)) throw new Error('not_found'); target.click(); const ok = await waitFor(() => targetDetachedOrStateChanged(target), timeout); return { ok, evidence: summarizeChange() }; }
Speculative Plans: Prefetching the Future
Idle time is abundant. Use it to precompute:
- Login flows for known domains.
- Navigation maps: which link text leads to which path.
- Form schemas: field role/name/value constraints.
Cache these as PlanScript templates. When the user initiates an intent, patch with parameters (account number, date range). This can cut median time-to-action by 30–60% on enterprise dashboards.
Plan consistency mechanisms
- Version plans with semantic slots (e.g., "$DATE_RANGE").
- Use a value binder that selects slots from local context or prompts the user.
- Keep a "plan health" score updated by execution success; prefer plans with higher success under the current DOM signature cluster.
Execution: Streaming, Backpressure, and Recovery
- Streaming: Planner emits a first viable step quickly, not a perfect plan. The orchestrator can begin executing while the planner refines later steps.
- Backpressure: If tools lag (e.g., waiting for network), pause planner stream or queue tool calls with max concurrency.
- Recovery: On failure, prefer local rewrites (retry with alternate selector) before asking for a cloud patch. Emit compact failure summaries for the planner to incorporate.
Performance Engineering on WebGPU/WASM
- Kernel caching: Warm up model sessions on load; pin them in a dedicated worker to avoid JIT churn.
- Quantization: Int4/Int8 with per-channel scales. ORT-web supports int8 QLinear ops; TVM/MLC supports int4; test numerics.
- Batching: Process DOM nodes in chunks (e.g., 256) and stream partial affordances to keep UI responsive.
- Memory reuse: Preallocate tensors and reuse; avoid frequent shape changes that trigger recompiles.
- Fallbacks: If WebGPU is unavailable, degrade to WASM SIMD; shave model sizes accordingly.
- Thermal/battery: Monitor navigator.deviceMemory and performance.timing; throttle on laptops on battery or mobile.
From Extension to App: Deployment Options
- Browser extension: Content script + service worker. Pros: broad reach. Cons: cross-origin iframe limits; injection surface.
- Native helper: Ship a companion app to host heavier on-device models with better GPU/NNAPI access; communicate via Native Messaging.
- Managed browser: For enterprise, embed the agent in a controlled Chromium build (Kiosk/CEF) with tighter policy hooks.
Evaluation: What to Measure
- Task success rate (TSR): end-to-end success across a task suite.
- Mean time-to-first-action (TTFA) and task completion time (TCT).
- Plan patch rate: fraction of runs needing cloud patch vs cached plan sufficiency.
- Privacy events: number of escalations; consent rates; data minimized (bytes/token count) sent to cloud.
- Selector stability: misclick rate; guard-triggered aborts.
- Cost: tokens per task; cloud calls per hour.
Build a public benchmark of common workflows (login, dashboard navigation, report export) across 20–50 sites with A/B between pure-cloud vs hybrid.
Worked Example: "Download the Latest Statement" Flow
- Initial state: User at https://acme.com.
- On-device model detects "Sign in" affordance; PII detector flags login fields.
- Orchestrator loads a cached PlanScript template for Acme Billing.
- Policy denies sending raw DOM; planner is asked to patch the plan with only the affordance schema and hashed tokens.
- Planner streams tool calls: click Sign in, fill email, fill password, click login, navigate to Statements, click Download.
- Each act step is guarded (e.g., wait_for URL or status text). If the "Statements" link is missing, orchestrator asks for a patch; planner returns an alternate path via "Billing" -> "Documents".
- Escalation: Not needed because context remained minimized. If the planner had requested a screenshot, the policy would have required consent + attested telemetry.
Developer Ergonomics and Testing
- Determinism: Ensure your tool wrappers are idempotent and safe to retry.
- Simulation: Build a headless replay harness that feeds recorded DOM signatures and affordance graphs to your planner to regression test patches.
- Policy unit tests: Evaluate typical and adversarial cases (e.g., page asks to export address book). Include golden files of redaction and consent receipts.
- Observability: Log structured traces locally; export anonymized aggregates (with consent). Consider OpenTelemetry schemas for spans like plan_load, tool_call, guard_check, escalation.
Alternatives and Tradeoffs
- Pure-cloud browsing (headless browser in the cloud): Simpler reasoning, but higher latency, cost, and privacy risks; brittle against MFA and device binding.
- Pure on-device: Great privacy and latency, but limited by model size and context length; long-horizon planning can degrade.
- Hybrid split-brain: More moving parts and policy complexity, but best balance for real users on the open web.
Open Questions and Future Work
- Better UI models: Specialized small models for UI understanding (e.g., Screen parsing) that compile cleanly to WebGPU with int4.
- Formal policy verification: Use SMT or Datalog proofs to ensure no policy path leaks raw PII without consent.
- Federated fine-tuning: Distill planner strategies into on-device models without collecting raw data; use DP-SGD.
- Standardizing attestation: Web-origin attestation primitives for privacy-preserving device assertions.
- Plan markets: Share signed, de-identified PlanScript templates across users to bootstrap success on long-tail sites.
Implementation Checklist
- Choose on-device runtime (ORT-web or Transformers.js) and quantized models for affordances and PII.
- Implement DOM featurizer and affordance graph extraction.
- Define PlanScript DSL and JSON Patch format.
- Build tool layer with guards, idempotency, and evidence return.
- Add IndexedDB plan cache with DOM signatures and LSH lookup.
- Implement streaming planner protocol (WS/SSE) with function calls.
- Integrate policy engine; write domain policies; unit test redaction.
- Add consent UX and attested telemetry via WebAuthn.
- Instrument metrics and traces; build a reproducible benchmark.
Appendix: Minimal Orchestrator Skeleton
javascriptclass AgentOrchestrator { constructor({ plannerUrl, policy, modelUrls }) { this.policy = policy; this.planner = new WebSocket(plannerUrl); this.cache = new PlanCache(); this.models = initModels(modelUrls); this.bindPlanner(); } bindPlanner() { this.planner.onmessage = (e) => this.handleMsg(JSON.parse(e.data)); } async perceive() { const dom = await featurizeDOM(); const afford = await this.models.affordances(dom.features); const pii = await this.models.pii(dom.textSketches); return { afford, pii, domSig: dom.signature }; } async plan(intent) { const { afford, pii, domSig } = await this.perceive(); const cached = await this.cache.get(window.location, intent, domSig); if (cached) return cached; const ctx = minimizeContext({ afford, pii }); if (!this.policy.permitPlanning(ctx)) throw new Error('policy_denied'); this.planner.send(JSON.stringify({ type: 'plan_request', intent, ctx })); return new Promise((resolve) => { this.planResolve = resolve; }); } async handleMsg(msg) { if (msg.type === 'plan_patch') { this.currentPlan = applyPatch(this.currentPlan || emptyPlan(), msg.patch); if (this.planResolve) this.planResolve(this.currentPlan); } if (msg.type === 'tool_call') { if (!this.policy.permitTool(msg.tool, msg.args)) return this.replyTool(msg.id, { error: 'policy' }); const res = await runTool(msg.tool, msg.args); this.replyTool(msg.id, this.policy.redact(res)); } if (msg.type === 'escalation_request') { const ok = await escalateWithConsentAndAttestation(msg.request, this.policy); this.planner.send(JSON.stringify({ type: 'escalation_result', ok })); } } replyTool(id, result) { this.planner.send(JSON.stringify({ type: 'tool_result', id, result })); } }
Appendix: Consent + Attestation Sketch
javascriptasync function escalateWithConsentAndAttestation(request, policy) { const summary = policy.summarize(request); const granted = await showConsentUI(summary); if (!granted) return false; const payload = { plan_id: request.plan_id, policy_hash: policy.hash(), context_summary: request.context_summary, consent: { granted: true, ts: Date.now() } }; const signed = await webauthnSign(payload); // Use WebAuthn get with challenge = hash(payload) await sendTelemetry({ ...payload, signature: signed }); return true; }
References and Pointers
- ONNX Runtime Web (WebGPU EP): Efficient in-browser inference for quantized models.
- Transformers.js: In-browser transformers with WebGPU backend.
- MLC LLM / TVM Unity: WebLLM and int4 quantized kernels for the web.
- JSON Patch (RFC 6902): Standard for patching structured plans.
- WebAuthn: Hardware-bound keys and signatures for attested telemetry basics.
- Open Policy Agent (OPA) and Rego: Mature policy engine, adaptable to browser-side evaluation via WASM.
Conclusion
A split-brain agentic browser—on-device perception and affordances with WebGPU/WASM, cloud LLM for long-horizon planning—delivers low-latency interaction, strong privacy by default, and sustainable costs. The key is not just model choice, but disciplined interfaces: a minimal, safe tool layer; a plan DSL that can be cached and patched; and a policy engine that keeps sensitive data local, escalating with user consent and attested telemetry when needed.
This architecture scales from hobby automations to enterprise-grade workflows. It embraces the web’s messiness with speculative planning, robust patching, and transparent governance. Most importantly, it makes agents feel fast and trustworthy—because the hot path stays on your device, and the cloud is used only when it truly adds value.