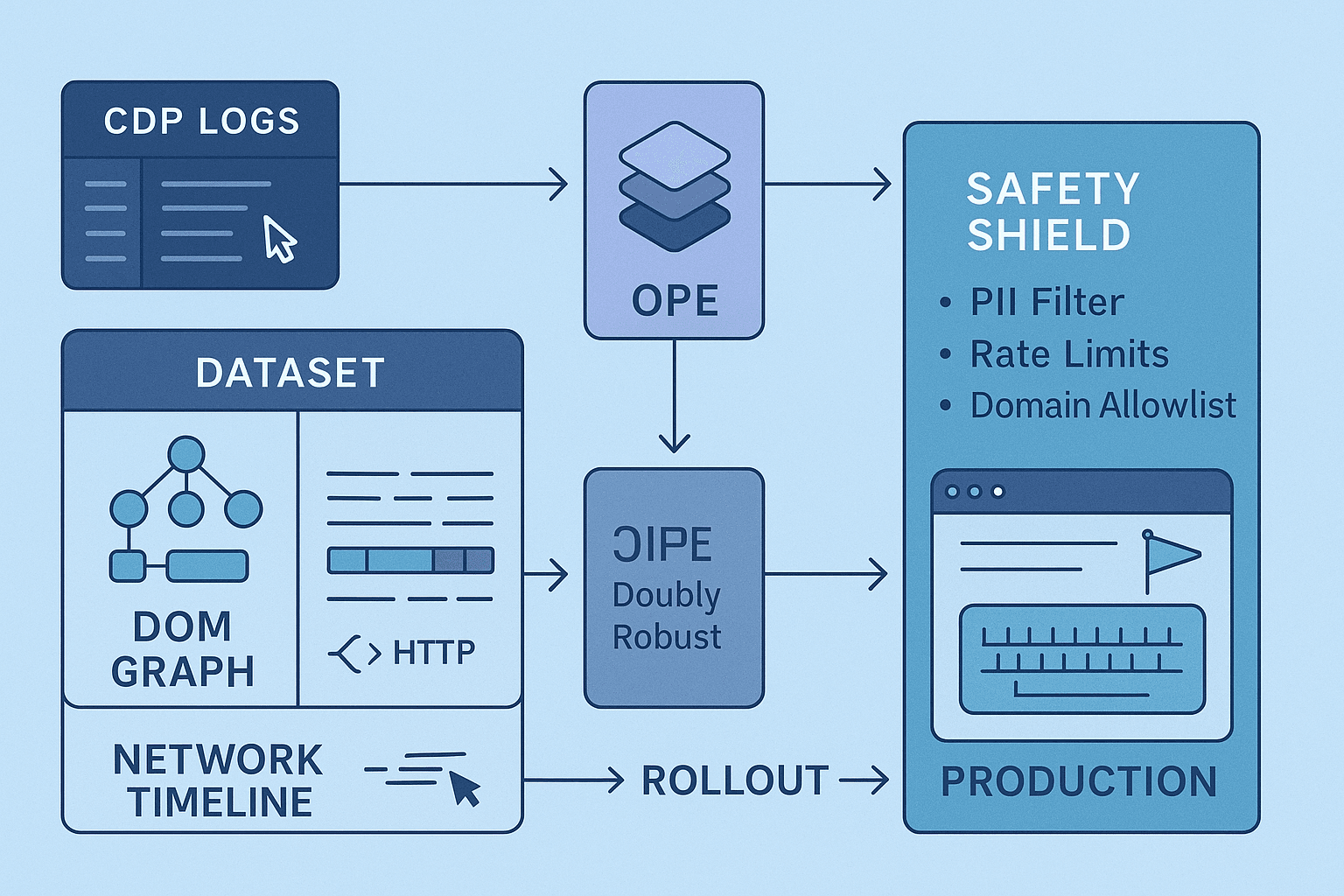
If you want to build a browser agent that actually ships, offline reinforcement learning (RL) is your most disciplined path from demo to deployment. The web is adversarial, stochastic, and riddled with safety and compliance landmines. Pure online exploration is a non-starter for anything customer-facing. Instead, batch RL over human interaction logs—plus principled counterfactual policy evaluation (OPE)—lets you learn from what’s already happened and quantify risk before a single autonomous click reaches production.
This article is a practical blueprint: instrument Chrome DevTools Protocol (CDP) logs, DOM events, and network traces; define a stable state/action schema; learn behavior policies from human clickstreams; evaluate candidate policies with doubly robust OPE; mitigate DOM drift; and wrap the whole thing in safety constraints and gating that make SREs and compliance happy. I’ll be opinionated where it matters: prefer conservative algorithms, insist on robust selectors and accessibility-first state, and treat OPE as a hard gate, not a dashboard curiosity.
Table of contents
- Why offline RL for browser agents
- Instrumentation: CDP logs, DOM events, network traces
- State schema: what the agent knows
- Action schema: what the agent can do
- From human clickstreams to datasets
- Rewards and success signals
- Behavior policy estimation for OPE
- Offline RL algorithms that actually work
- Counterfactual policy evaluation (DR, WDR, FQE)
- DOM drift and representation robustness
- Safety constraints and promotion gating
- Code snippets: Playwright/Node logging, dataset schema, DR OPE
- Metrics and rollout strategy
- References and benchmarks
- Opinionated end-to-end blueprint
Why offline RL for browser agents
Browser tasks are long-horizon, partially observable, and loaded with irreversible actions (purchases, deletions, PII entry). Random exploration is unacceptable. Supervised imitation from demonstrations works to a point (especially for short scripts), but small covariate shifts—layout tweaks, dynamic content, network timing—cause cascading errors. Offline RL provides:
- Credit assignment across long sequences via value learning.
- Better tolerance to covariate shift than pure imitation, when paired with conservative objectives (e.g., CQL) and action constraints.
- A principled way to compare and select policies via OPE, including confidence intervals and guardrails.
If you have human clickstreams, HARs, and DOM snapshots, you have fuel for a rigorous offline RL pipeline.
Instrumentation: CDP logs, DOM events, network traces
You need the fullest possible picture of what users did and what the browser returned at each step.
Log these at a minimum:
- DOM state: serialized snapshots or diffs, accessibility tree (AX), element attributes (id, class, role, aria-*), bounding boxes, visibility.
- User events: click, dblclick, keydown/keypress, input, change, focus/blur, wheel/scroll. For clicks, capture both CSS/XPath selector and screen coordinates.
- Navigation: URL, referrer, redirects, history length, hash changes, timestamped.
- Network: request/response pairs with method, URL, status, timing, response size, content-type, and selected response bodies (structured/PII-safe). HAR-like structure is ideal.
- Console/runtime: console.error/warn, uncaught exceptions, CSP violations.
- Screenshots (optional): downsampled and/or element crops, primarily for visual locator fallback and debugging.
Sampling strategy and PII safety:
- Redact secrets: strip input values for password, credit card, SSN-like regex matches, JWTs, and cookies. Keep lengths and types to preserve learning signal.
- Hash or tokenize stable IDs (user IDs, emails) to prevent leaking PII.
- Throttle content archiving; capture full response bodies only for structured domains you own and have consent to log. Consider on-the-fly JSONSchema filtering.
- Log at deterministic cadence for state (e.g., after each DOM mutation batch, or on every action boundary) to simplify alignment.
Example: Playwright + CDP logging in Node.js
tsimport { chromium } from 'playwright'; async function recordSession(url: string) { const browser = await chromium.launch({ headless: false }); const context = await browser.newContext({ viewport: { width: 1440, height: 900 }, recordHar: { path: 'session.har', mode: 'full' }, }); const page = await context.newPage(); // CDP session for low-level events const client = await context.newCDPSession(page); await client.send('Network.enable'); await client.send('DOM.enable'); await client.send('Log.enable'); await client.send('Runtime.enable'); const events: any[] = []; function now() { return new Date().toISOString(); } // Network tracing client.on('Network.requestWillBeSent', (e) => { events.push({ t: now(), type: 'net:req', e }); }); client.on('Network.responseReceived', (e) => { events.push({ t: now(), type: 'net:res', e: { ...e, body: undefined } }); }); // DOM mutations (batched snapshot via Playwright) async function snapshotDOM(label: string) { const dom = await page.evaluate(() => { const walker = document.createTreeWalker(document, NodeFilter.SHOW_ELEMENT); const nodes: any[] = []; let n: any; while ((n = walker.nextNode())) { const el = n as HTMLElement; const rect = el.getBoundingClientRect(); nodes.push({ tag: el.tagName.toLowerCase(), id: el.id || null, cls: el.className || null, role: el.getAttribute('role') || null, aria: Object.fromEntries([...el.attributes].filter(a => a.name.startsWith('aria-')).map(a => [a.name, a.value])), text: (el as any).innerText?.slice(0, 80) || null, rect: { x: rect.x, y: rect.y, w: rect.width, h: rect.height }, visible: !!(el.offsetWidth || el.offsetHeight || el.getClientRects().length), }); } return { url: location.href, title: document.title, nodes }; }); events.push({ t: now(), type: 'dom:snapshot', label, dom }); } // User actions instrumentation const actionLog: any[] = []; await page.exposeFunction('logClientEvent', (payload: any) => { actionLog.push({ t: now(), ...payload }); }); await page.addInitScript(() => { function selectorFor(el: Element): string { // Simple robust selector: prefer role/name, fallback to CSS const ariaLabel = (el as HTMLElement).getAttribute('aria-label'); const role = (el as HTMLElement).getAttribute('role'); if (role && ariaLabel) return `[role="${role}"][aria-label="${ariaLabel}"]`; let path = ''; while (el && el.nodeType === 1 && path.length < 512) { let sel = el.nodeName.toLowerCase(); if ((el as HTMLElement).id) { sel += `#${(el as HTMLElement).id}`; el = el.parentElement!; path = sel + (path ? '>' + path : ''); continue; } const cls = (el as HTMLElement).className?.split?.(/\s+/).filter(Boolean) || []; if (cls.length) sel += '.' + cls.slice(0, 2).join('.'); const sibs = el.parentElement ? Array.from(el.parentElement.children).filter(c => c.nodeName === el.nodeName) : []; if (sibs.length > 1 && el.parentElement) sel += `:nth-of-type(${sibs.indexOf(el) + 1})`; path = sel + (path ? '>' + path : ''); el = el.parentElement!; } return path; } document.addEventListener('click', (ev) => { const el = ev.target as HTMLElement; const rect = el.getBoundingClientRect(); // Do not capture raw input values const payload = { type: 'click', x: ev.clientX, y: ev.clientY, target: { selector: selectorFor(el), tag: el.tagName.toLowerCase(), text: (el as any).innerText?.slice(0, 40) || null, rect: { x: rect.x, y: rect.y, w: rect.width, h: rect.height }, } }; // @ts-ignore window['logClientEvent'](payload); }, true); document.addEventListener('input', (ev) => { const el = ev.target as HTMLInputElement | HTMLTextAreaElement; const rect = el.getBoundingClientRect(); const payload = { type: 'input', target: { selector: selectorFor(el), tag: el.tagName.toLowerCase(), typeAttr: (el as HTMLInputElement).type, rect: { x: rect.x, y: rect.y, w: rect.width, h: rect.height }, }, // redact value len: (el as HTMLInputElement).value?.length || 0, }; // @ts-ignore window['logClientEvent'](payload); }, true); }); await page.goto(url); await snapshotDOM('initial'); // User drives the session manually here… await page.waitForTimeout(30000); await snapshotDOM('final'); await context.storageState({ path: 'state.json' }); // Persist events & actions const fs = await import('node:fs'); fs.writeFileSync('events.json', JSON.stringify({ events, actions: actionLog }, null, 2)); await browser.close(); } recordSession('https://example.com');
State schema: what the agent knows
Good state design is the difference between robust generalization and brittle CSS-chasing. I recommend a multi-view, accessibility-first state with late fusion.
Core components per timestep t:
- Page metadata: URL, domain, path/query tokens, title, viewport size, time since load, scroll position.
- DOM graph: nodes with tag, role, aria attributes, text snippet, styles, visibility, bounding box; edges for parent-child and CSS layout hints. Consider a pruned tree (visible and interactive elements), plus a candidate set of actionable elements.
- Accessibility tree: names, roles, states (expanded, selected), landmarks. This is semantically stable across UI refactors.
- Element embeddings: for each candidate element i, compute a feature vector ei from: tag one-hot, role one-hot, text embedding (small language model or bag-of-ngrams), attribute hash, bbox normalized, z-index, clickability heuristics, network context (e.g., nearby spinner).
- History features: recent k actions (type, target embedding), last network statuses, error counts, form progress signals.
- Network features: recent 5XX/4XX rates, in-flight requests count, last response content-type, latency histogram.
- Optional visual features: low-resolution page embedding or element crop embedding (CLIP-like), used as a fallback to survive style and structure drift.
Representation strategies:
- Graph encoder: GNN over the DOM graph to produce contextualized element embeddings; aggregate to page embedding. Works well for variable-length structures.
- Candidate set encoding: restrict action space to top N elements by heuristic clickability and semantic relevance to task prompt.
- Tokenized textual context: if the agent is language-conditioned (e.g., “download the April report”), concatenate a compact prompt embedding to state.
Action schema: what the agent can do
Action design should be safe, discrete, and compositional. Avoid unconstrained JS execution in training and serving.
Recommended discrete action types:
- Click(element_id)
- Type(element_id, token) with token from a small controlled vocabulary: {ENTER, TAB, BACKSPACE, <alphanumeric-chunks>}. For sensitive inputs, use synthetic placeholders, not real secrets.
- Select(element_id, option_id)
- Scroll(direction, magnitude)
- Wait(duration_bucket)
- Navigate(url_whitelist_id)
- Submit(form_id)
Practical tips:
- Action targets are indices into the candidate element set derived from the current DOM snapshot.
- For typing, represent the plan as a sequence over tokenized chunks (e.g., “Acme Inc” -> [Acme, Inc]). Enforce token length limits.
- Keep a hard allowlist for navigation targets; infer it from training domains and explicit config.
- Bundle low-level primitives into high-level options for long-horizon stability, e.g., FillField(name=“email”) or ClickButton(name=“Continue”). Implement options as macro-actions that expand into primitives but train policy at the option level.
From human clickstreams to datasets
You need to align states, actions, and outcomes into trajectories.
- Sessionization: cut logs into sessions by navigation boundaries, idle timeouts, or task markers.
- Timestep boundaries: create a state snapshot before each user action; define the next state after network/DOM quiescence or after a short fixed delay.
- Action extraction: translate DOM events into action records using the action schema; associate each action with a candidate element index and metadata.
- Outcome labels: compute terminal success/failure via heuristics, e.g., presence of a success banner, URL matches a goal pattern, or network response 200 from a known endpoint.
- Data quality filters: drop sessions with high error rates, non-deterministic experiments (A/B with radically different UIs), or obvious bots.
- Balancing and deduplication: avoid over-representing easy paths; include negative and near-miss examples for contrastive learning and robust value estimation.
Dataset format (parquet/arrow recommended):
- episode_id, t, domain
- s_t: serialized state (compact protobuf, msgpack, or columnar fields)
- a_t: action type + target index + params
- r_t: scalar reward
- p_b(a_t|s_t): behavior policy propensity (if available)
- done: boolean
Rewards and success signals
Rewards should be sparse, composable, and auditable. Avoid brittleness.
- Terminal rewards: success = +1, failure/timeouts = 0. For e-commerce or support workflows, consider shaped terminal rewards proportional to task value.
- Shaping (careful): incremental rewards for progress markers—form completion %, DOM diff indicating file downloaded, specific network response codes (200 from expected endpoint), reaching a URL path prefix.
- Penalties: clicks leading to 4XX/5XX bursts, repeated back-and-forth navigations, typing into sensitive fields without prior consent.
- Safety-based clipping: cap reward for actions flagged risky to prevent exploitation.
Behavior policy estimation for OPE
Counterfactual estimators need propensities p_b(a|s). If you have no direct logging policy probabilities (typical for human sessions), estimate a behavior policy.
- Behavior cloning (BC): train a policy π_b(a|s) over the logged data using cross-entropy. Use the same action space/candidate selection as the target policy to reduce mismatch.
- Calibration: apply temperature scaling or isotonic regression to calibrate probabilities. Poor calibration inflates IS variance.
- Stratification: fit separate π_b per domain or UI family to reduce multi-modal confusion.
- Smoothing: add floor epsilon to avoid zero probabilities for seen actions.
Offline RL algorithms that actually work
Pick algorithms known to be conservative and stable:
- CQL (Conservative Q-Learning, Kumar et al. 2020): penalizes Q over out-of-distribution actions, reducing overestimation. Good default for discrete action sets derived from candidates.
- IQL (Implicit Q-Learning, Kostrikov et al. 2022): value-weighted regression without importance sampling; robust and simple. Strong baseline for medium-to-large datasets.
- BRAC (Behavior Regularized Actor-Critic): explicitly regularizes divergence from behavior policy; useful when you trust π_b.
- Decision Transformer (DT): sequence modeling alternative using return-to-go conditioning. Works surprisingly well in long-horizon settings; combine with action masking and safety constraints.
Practical notes:
- Use action masking to disallow actions not applicable to the current state (e.g., clicking invisible elements).
- Prefer hierarchical training: option-level policy first, then fine-tune primitive controller.
- Enforce conservative Q-learning in early experiments; it’s easier to relax conservatism than to mop up aggressive failures in prod.
Counterfactual policy evaluation (DR, WDR, FQE)
You should not ship a policy without offline risk estimates. Combine multiple OPE estimators and require agreement.
- Importance Sampling (IS): unbiased but very high variance. Step-wise IS is often better than trajectory-wise in long horizons.
- Weighted IS (WIS/SNIS): normalizes weights to reduce variance, introduces small bias.
- Doubly Robust (DR): combines IS with model-based value estimates (Q or V) for variance reduction and robustness to misspecification. The go-to in practice.
- Weighted DR (WDR): normalizes IS weights in DR for further stability.
- Fitted Q Evaluation (FQE): trains a value function on the dataset using the target policy’s Bellman operator; separate from the RL training; useful cross-check.
Step-wise DR estimator for episodic MDP:
- Learn/evaluate Q_hat(s,a) and V_hat(s) = E_{a~π_e}[Q_hat(s,a)] under the evaluation policy π_e.
- Compute per-step importance weights w_t = Π_{i=0}^t π_e(a_i|s_i)/π_b(a_i|s_i).
- DR estimate: V_DR = (1/N) Σ_{episodes} Σ_{t} w_t [ r_t - Q_hat(s_t,a_t) + γ V_hat(s_{t+1}) ]. For terminal states, V_hat(s_{T+1}) = 0.
Variance control and CIs:
- Use per-decision WDR to damp heavy tails.
- Truncate weights at a quantile (p99) and report sensitivity.
- Bootstrap across episodes to get confidence intervals.
- Sanity-check with on-policy rollouts in a safe sandbox where possible.
Example: minimal DR OPE in PyTorch-like pseudocode
pythonimport torch def doubly_robust_ope(episodes, pi_e, pi_b, Q_hat, V_hat, gamma=0.99, clip_w=100.0): # episodes: list of dicts with keys s, a, r, done (each a list) values = [] for ep in episodes: w = 1.0 v = 0.0 for t in range(len(ep['a'])): s_t, a_t, r_t = ep['s'][t], ep['a'][t], ep['r'][t] s_tp1 = ep['s'][t+1] if t+1 < len(ep['s']) else None pb = max(pi_b.prob(s_t, a_t), 1e-6) pe = max(pi_e.prob(s_t, a_t), 1e-6) w = min(w * (pe / pb), clip_w) q_hat = Q_hat(s_t, a_t) v_hat = 0.0 if s_tp1 is None else V_hat(s_tp1) v += w * (r_t - q_hat + gamma * v_hat) values.append(v) return torch.tensor(values).mean().item(), torch.tensor(values).std().item()
A practical stack pairs WDR with FQE; require both to agree within tolerance before promotion.
DOM drift and representation robustness
The web changes under your feet. Agents need selectors and embeddings that survive:
- Class/id churn from CSS frameworks and minifiers
- Component reordering
- A/B tests and feature flags
- Mobile/desktop responsive layouts
Mitigation strategies:
- Accessibility-first selectors: prefer role + accessible name over CSS classes. Use name computation per ARIA spec.
- Semantic element embeddings: combine tag/role/text with neighborhood context (parent roles, sibling types) using a GNN. The model learns invariances beyond literal selectors.
- Visual fallback: when selectors break, match via element crop embeddings or keypoint-based template matching; use only as a tie-breaker.
- DOM versioning: store per-domain DOM schemas over time; detect drift by measuring embedding distribution shift (e.g., MMD or FID-like metrics) and trigger retraining.
- Invariant risk minimization (IRM): train with domain labels (themes, locales, A/B) and penalize spurious correlations.
- Selector robustness tests: unit tests that locate critical elements across releases using your locator stack; gate deployments on pass rates.
Safety constraints and promotion gating
Safety is not an afterthought. It’s a formal part of the MDP. Model it as a constrained MDP (CMDP) or use a “shield” with hard rules enforced at inference.
Policy-independent constraints (hard rules):
- Domain allowlist: never navigate outside configured domains.
- Sensitive actions blocklist: never click destructive buttons (delete, submit payment) without explicit human approval.
- PII guard: never read or emit raw secrets; redact logs; disallow typing into password/credit card fields.
- Rate limiting: per-domain QPS, max concurrency, and backoff strategies.
- robots.txt and ToS compliance: restrict crawling/automation as required.
- CSRF/CSP respect: no injection of custom scripts unless explicitly whitelisted for owned properties.
Policy-dependent constraints (learned or value-based):
- Risk-aware action selection: penalize Q for actions historically associated with errors or security warnings.
- Seldonian constraints: optimize under probabilistic safety constraints with high-confidence bounds.
Operational gating:
- OPE threshold: require DR and FQE estimates to exceed a baseline by margin m with 95% CI above baseline.
- Canary rollout: start with 1% of safe, low-value tasks; gradually expand with live monitoring.
- Human-in-the-loop (HITL): for high-stakes actions, require confirmation or provide a reversible sandbox.
- Audit logging: immutable logs of all actions, decisions, and model versions.
Code snippets: dataset schema and model hooks
Candidate element featurization (Python):
pythonimport numpy as np def element_features(node): # node: dict with tag, role, aria, text, rect, visible tag_vocab = ['a','button','input','div','span','li','ul','img','select','textarea','form'] role_vocab = ['button','link','textbox','combobox','menuitem','checkbox','radio','dialog','tab'] def one_hot(x, vocab): v = np.zeros(len(vocab), dtype=np.float32) if x in vocab: v[vocab.index(x)] = 1.0 return v text_embed = hash(node.get('text') or '') % 10007 / 10007.0 # toy hashing trick; replace with LM embed rect = node.get('rect', {}) bbox = np.array([ rect.get('x',0)/1440.0, rect.get('y',0)/900.0, rect.get('w',0)/1440.0, rect.get('h',0)/900.0 ], dtype=np.float32) feat = np.concatenate([ one_hot(node.get('tag'), tag_vocab), one_hot(node.get('role'), role_vocab), np.array([text_embed, float(node.get('visible', False))], dtype=np.float32), bbox, ]) return feat
CQL-style training loop sketch (PyTorch):
python# Pseudocode only; see official CQL repos for complete implementation class QNet(torch.nn.Module): def __init__(self, state_dim, action_dim): super().__init__() self.f = torch.nn.Sequential( torch.nn.Linear(state_dim, 512), torch.nn.ReLU(), torch.nn.Linear(512, 512), torch.nn.ReLU(), torch.nn.Linear(512, action_dim) ) def forward(self, s): return self.f(s) q = QNet(state_dim, action_dim) q_target = QNet(state_dim, action_dim) optimizer = torch.optim.Adam(q.parameters(), lr=3e-4) alpha = 1.0 # CQL penalty weight def cql_loss(batch): s, a, r, s2, done = batch q_sa = q(s).gather(1, a.long()) with torch.no_grad(): v_s2 = q_target(s2).max(dim=1, keepdim=True).values y = r + gamma * (1 - done) * v_s2 bellman = ((q_sa - y) ** 2).mean() # CQL penalty: push down Q on actions not in dataset logits = q(s) logsumexp = torch.logsumexp(logits, dim=1).mean() dataset_q = q_sa.mean() penalty = (logsumexp - dataset_q) return bellman + alpha * penalty for step in range(steps): batch = replay.sample() loss = cql_loss(batch) optimizer.zero_grad(); loss.backward(); optimizer.step() soft_update(q_target, q, tau=0.005)
OPE with WDR + FQE gate (sketch):
pythonwdr_mean, wdr_std = doubly_robust_ope(val_episodes, pi_e, pi_b, Q_hat, V_hat) fqe_value, fqe_ci = run_fqe(val_episodes, pi_e) if (wdr_mean - 1.96 * wdr_std/len(val_episodes)**0.5) > baseline + margin \ and (fqe_value - fqe_ci) > baseline + margin: approve_for_canary() else: reject_and_iterate()
Metrics and rollout strategy
Pre-promotion offline metrics:
- DR/WDR mean and 95% CI vs baseline policy
- FQE estimate and CI
- Safety constraint violations (simulated): zero tolerance
- Robustness tests across DOM drift cohorts
Canary-phase online metrics:
- Task success rate uplift with CI
- Incident rate: blocked actions, timeouts, retries
- Latency distribution and network load
- Safety SLOs: PII guard triggers, domain allowlist hits (must be zero), CAPTCHA encounters
Rollout steps:
- Shadow mode: run the agent in parallel, logging decisions but not acting; compare with human actions and compute counterfactuals.
- Canary: enable for low-value, low-risk tasks on owned domains; 1% traffic; instantaneous rollback on incident.
- Gradual expansion: double traffic at each stable plateau; keep HITL for high-stakes actions.
- Continuous OPE: re-run WDR/FQE nightly on fresh logs; halt if estimates degrade.
References and benchmarks
- CQL: Kumar, A., et al. Conservative Q-Learning for Offline Reinforcement Learning (NeurIPS 2020).
- IQL: Kostrikov, I., et al. Offline RL with Implicit Q-Learning (ICLR 2022).
- OPE Surveys: Dudík et al. Doubly Robust Policy Evaluation; Thomas & Brunskill. Data-Efficient OPE in RL.
- FQE: Le et al. Batch Policy Evaluation Under Sufficient Coverage.
- Browser benchmarks: MiniWoB++ (Shi et al.), WebArena (Zhou et al.), BrowserGym (Millidge et al.).
- CDP: Chrome DevTools Protocol documentation.
Opinionated end-to-end blueprint
Here is the condensed playbook I recommend for most teams building agentic browsers:
- Instrumentation and data hygiene
- Use Playwright or Puppeteer plus a CDP session to log DOM snapshots, accessibility tree, user events, and HAR-like network traces.
- Redact credentials and PII at the source. Hash stable identifiers. Enforce domain-level consent.
- Align state/action at action boundaries; snapshot DOM before and after each action with quiescence windows.
- Schema and representation
- Define a multi-view state: DOM graph + AX tree + candidate element features + minimal visual fallback. Keep it small enough for fast inference.
- Design a discrete, masked action space over candidates; introduce macro-actions for common patterns.
- Build robust selectors prioritizing role/name; keep CSS as a fallback only.
- Rewards and outcomes
- Start with sparse terminal rewards; add conservative shaping for progress markers validated against network responses and DOM diffs.
- Penalize error-prone patterns and risky behaviors.
- Behavior policy and calibration
- Train a calibrated behavior cloning model per domain family to estimate propensities.
- Validate calibration with reliability diagrams; apply temperature scaling.
- Offline RL training
- Start with CQL over masked discrete actions; add IQL as a cross-check.
- Consider hierarchical options for long flows; mask unsafe/inapplicable actions by design.
- Early-stop aggressively based on validation losses and OPE stability.
- Counterfactual evaluation
- Compute WDR with calibrated π_b, using step-wise weights and clipping; bootstrap CIs.
- Train FQE separately; require agreement with WDR within tolerance.
- Sensitivity analysis: vary clipping thresholds, check per-domain performance and heavy-tail exposure.
- Drift and robustness
- Monitor embedding distribution shifts; retrain when thresholds exceeded.
- Maintain a selector robustness test suite; fail builds on red.
- Apply IRM-style penalties or domain adversarial training to reduce spurious correlations.
- Safety and governance
- Implement a policy shield with hard allowlists, blocklists, PII guards, and rate limits.
- Codify SLOs for safety incidents (zero tolerance), latency, and success.
- Establish audit logging, model versioning, and rollback switches.
- Staging and rollout
- Shadow mode in staging and then production.
- Canary on owned domains and low-stakes tasks; HITL for sensitive ones.
- Continuous re-evaluation with OPE; auto-halt on degradation or incident.
- Iterate and expand
- Add new domains via transfer learning; update behavior policies and masks.
- Harvest fresh human data to close gaps; prioritize coverage where OPE shows uncertainty.
Closing thoughts
The big trap in browser agents is believing that more model capacity will transcend the messiness of the web. It won’t. What works is discipline: a clean state/action schema grounded in accessibility, a conservative offline RL method, a calibrated behavior policy for OPE, and an uncompromising safety shield. With that foundation, the agent learns not just to click, but to defer, to wait, to retry, and—crucially—to avoid. That’s how you turn a flashy demo into a system you can trust on a Tuesday afternoon when everything is slightly on fire.
If you adopt one mantra from this blueprint, make it this: OPE is a gate, not a graph. Only ship what you can justify with counterfactual evidence, and you’ll spend your engineering time expanding capability instead of apologizing for incidents.