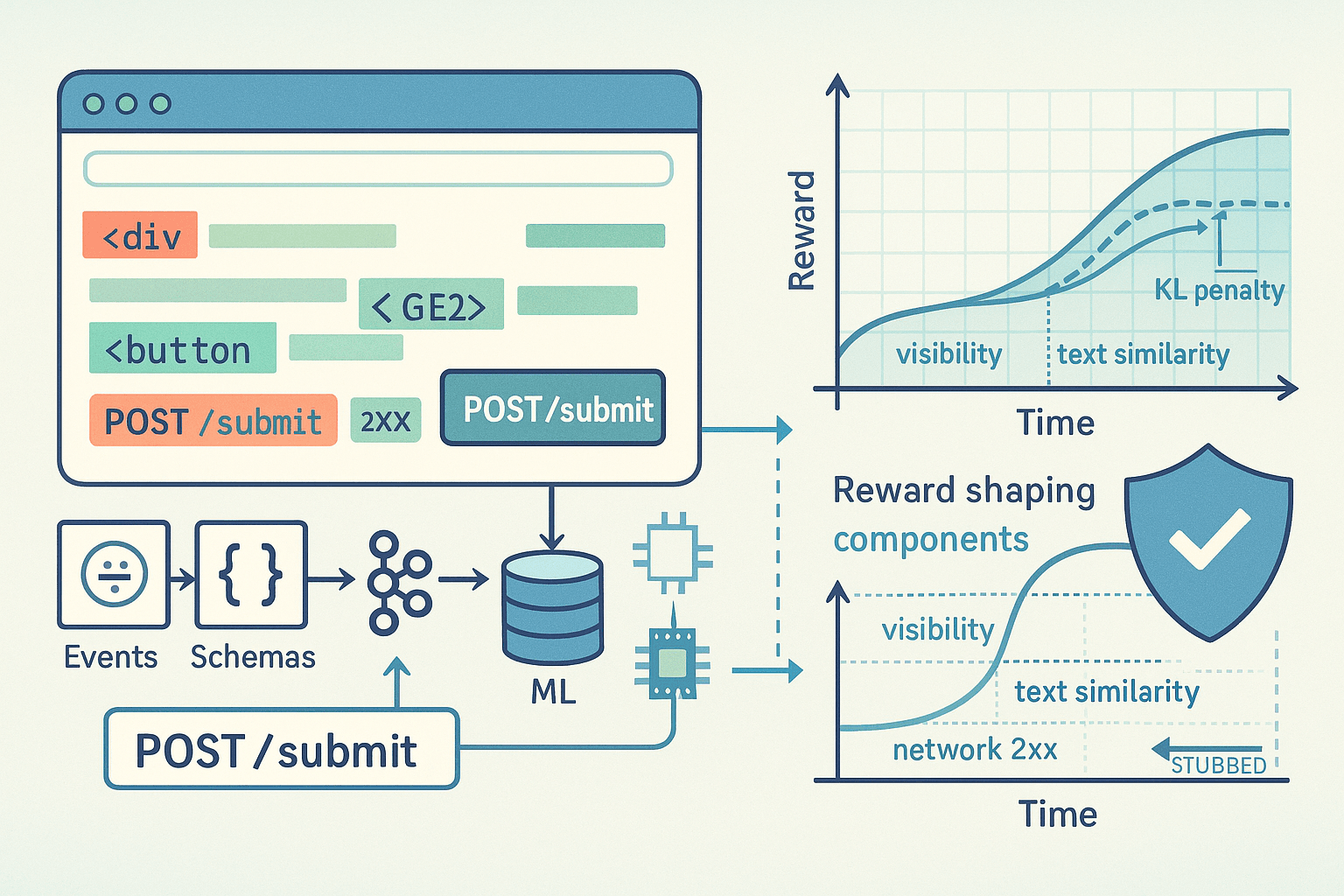
Why reward models for browser agents need to be different
Browser agents are deceptively hard to train. If you’ve built agents that click, type, scroll, and fetch on arbitrary websites, you’ve run into the same two issues that sink most projects:
- Sparse and deceptive rewards: “Task completed” is often a single boolean buried behind login flows, dynamic UIs, pop-ups, and multi-step funnels. A naive success/failure reward drives credit assignment problems and brittle behavior.
- Safety and stability: Real websites have write paths you must not touch in training (cart checkouts, destructive account settings). Agents can accidentally trigger side‑effects or leak PII when trained from real telemetry.
RLHF (Reinforcement Learning from Human Feedback) and its cousin RLAIF (Reinforcement Learning from AI Feedback) are the most pragmatic ways to shape agent behavior without hand‑coding rules. But the browser setting needs specialized reward modeling—and careful rollout engineering—to be both effective and safe.
This article proposes an opinionated recipe:
- Convert DOM and network diffs into dense, shaped reward signals that reflect real progress.
- Build an event‑sourced telemetry pipeline to capture reproducible trajectories, with privacy and redaction built‑in.
- Mix human and LLM preference signals to train robust reward models; calibrate the LLM-as-judge.
- Gate all write effects with stubs and sandboxes so on‑policy rollouts can safely improve policies from real telemetry.
We’ll go deep on data models, reward shaping heuristics, safe rollout tiers, and code snippets to make this concrete.
What makes browser reward modeling hard
- Partial progress is everywhere. A user might be halfway to “download the invoice PDF” after navigating to the right page and opening the dropdown. If your reward only fires at download time, your policy never learns the multi-step structure.
- The DOM is opaque unless you interpret it. Screenshot-only policies can miss key semantics like hidden inputs, form validation, or dynamically injected elements. Conversely, DOM-only ignores visual affordances like modal z‑index or obscured buttons.
- The network layer matters. A “successful” form interaction usually coincides with a 2xx POST, a redirect, and some JSON updates. Reward shaping should use network signals to avoid optimizing toward visually deceptive states.
- Safety risk is task dependent. Clicking “Delete” looks like success in some flows, but is catastrophic in real accounts. You need strong gating and sandboxes before you do any on‑policy improvement.
Event‑sourced telemetry: the substrate for training and auditing
The foundation is a comprehensive, event‑sourced log that captures everything needed to replay and analyze a trajectory offline. Event sourcing turns every interaction into immutable append‑only events. It’s the right mental model for RL data: deterministic, auditable, and debuggable.
Core principles:
- Append‑only events with lamport or monotonic timestamps
- Deterministic identifiers for sessions, pages, and nodes
- Separation of raw capture (high volume) and derived artifacts (diffs, embeddings)
- Built‑in PII/secret redaction at the edge
- Reproducibility via deterministic seeds and pinned resource versions when possible
Recommended event types:
- session.start, session.end
- page.navigate(url, referrer), page.load, page.screenshot(id)
- dom.snapshot(id, root_html, layout_metrics), dom.diff(parent_id, patch)
- ui.click(xpath/css, bounding_box, visible=true/false), ui.input(selector, text_len, masked=true), ui.scroll(x,y)
- net.request(id, method, url, headers_hash, body_hash, redacted_fields), net.response(id, status, content_type, size)
- agent.action(tokenized_action_text, tool_call, arguments)
- reward.shaping(component, value, meta)
- safety.event(type, details)
A minimal TypeScript schema:
ts// Event envelope for Kafka / Kinesis / PubSub interface EventEnvelope<T> { event_id: string; // uuid v4 session_id: string; // uuid v4 per rollout seq: number; // monotonic per session ts: string; // ISO timestamp kind: string; // e.g., 'ui.click', 'dom.diff' actor: 'agent' | 'env' | 'labeler' | 'system'; payload: T; pii_redacted: boolean; schema_version: string; } interface DomSnapshot { snapshot_id: string; url: string; html: string; // optional: gzipped+base64 to limit size viewport: { w: number; h: number }; layout: Array<{ nodeId: number; x: number; y: number; w: number; h: number; visible: boolean }>; } interface DomDiffPatch { parent_snapshot_id: string; patch: string; // e.g., JSON Patch (RFC 6902) over serialized DOM tree representation added_nodes: number; removed_nodes: number; text_changed_nodes: number; } interface UiClick { selector: string; xpath?: string; bbox?: [number, number, number, number]; visible: boolean } interface UiInput { selector: string; text_len: number; masked: boolean } interface NetRequest { id: string; method: string; url: string; body_hash?: string; headers_hash?: string; redacted_fields?: string[] } interface NetResponse { id: string; status: number; content_type?: string; size?: number } interface RewardShaping { component: string; value: number; meta?: Record<string, unknown> }
Storage and processing:
- Ingest: Browser CDP clients (e.g., Chrome DevTools Protocol via Puppeteer/Playwright) emit events to Kafka.
- Hot storage: Kafka topics partitioned by session_id; consumers derive dom.diff from successive snapshots (tree differ), materialize net request/response joins, and compute shaping features.
- Cold storage: Parquet in S3/GCS with partitioning by date/task; ClickHouse/BigQuery for analytics and offline evaluation.
- Privacy: Redact text in inputs; hash network bodies and redact known PII fields (emails, tokens) by regex and learned detectors at the edge. Maintain allowlists for non‑sensitive payload logging.
Why event sourcing here:
- Reproducible off‑policy learning and counterfactual evaluation.
- Auditing: When a reward hack emerges (it will), you can reconstruct exactly how the model exploited the signal.
- Extensibility: Add new derived reward components later without recapturing data.
DOM‑ and network‑diff shaping: from sparse to teachable
Shaping converts raw diffs into dense signals that correlate with progress. The art is to mix task‑agnostic and task‑specific components without making the reward trivially exploitable.
Task‑agnostic shaping components:
- Element existence: Target selectors become present/visible (e.g., a success banner div.alert-success).
- Text similarity: Levenshtein or token F1 between current page text and a target substring (e.g., order number present on page).
- Form validation state: Count of inputs with aria-invalid=false post‑submit; presence of .error messages decreases reward.
- Network success: Weighted count of 2xx responses following a submit; 4xx/5xx penalized.
- Navigation progress: Distance in click‑graph to known success URLs; redirects to known patterns are rewarded.
- Focused viewport: Visibility of target element in viewport after scroll.
- Latency: Negative shaping for long idle gaps post‑click if expected response usually arrives quickly.
Task‑specific shaping components:
- Selector match: CSS/XPath for a goal element (e.g., button[data-test='download-invoice']) becomes available and clickable.
- Structured field extraction: JSON response contains a field with a value matching regex (e.g., invoice_id = /INV-[0-9]+/).
- File artifact: Downloaded file checksum matches expected pattern/type; PDF text contains terms.
- Basket delta: Cart item count equals target quantity.
Implementation sketch in Python:
pythonfrom difflib import SequenceMatcher from rapidfuzz import fuzz from urllib.parse import urlparse class RewardComputer: def __init__(self, task_spec): self.task = task_spec # contains target_selectors, target_text, success_urls, etc. def text_similarity(self, old_text: str, new_text: str, target_text: str) -> float: # Encourage movement toward target text appearing base_gain = (fuzz.token_set_ratio(new_text, target_text) - fuzz.token_set_ratio(old_text, target_text)) / 100.0 return max(-0.1, min(0.3, base_gain)) def element_visibility(self, dom_after): score = 0.0 for sel in self.task.get('target_selectors', []): el = dom_after.query(sel) # hypothetical API over parsed DOM+layout if el and el.visible: score += 0.2 return min(score, 0.6) def network_shaping(self, recent_responses): score = 0.0 for resp in recent_responses: if 200 <= resp.status < 300: score += 0.05 elif resp.status >= 400: score -= 0.1 return max(-0.3, min(0.2, score)) def url_progress(self, old_url, new_url): if new_url in self.task.get('success_urls', []): return 0.5 # Reward moving closer in URL pattern space if urlparse(old_url).path != urlparse(new_url).path: return 0.05 return 0.0 def compute(self, traj_window): # traj_window: access to last dom snapshot, patch, network, etc. old_text = traj_window.prev_text new_text = traj_window.curr_text dom_after = traj_window.dom_after old_url, new_url = traj_window.prev_url, traj_window.curr_url r = 0.0 r += self.text_similarity(old_text, new_text, self.task.get('target_text', '')) r += self.element_visibility(dom_after) r += self.network_shaping(traj_window.recent_responses) r += self.url_progress(old_url, new_url) # Penalties for obvious regressions if traj_window.dom_patch.removed_nodes > 500 and not traj_window.expected_reload: r -= 0.2 # suspicious mass removals without a nav if any('error' in (m.get('class','')+m.get('role','')) for m in traj_window.new_nodes_meta): r -= 0.1 return r
Guidelines for shaping:
- Prefer deltas over absolutes: Reward should reflect improvement this step.
- Cap each component: Avoid runaway single‑component dominance.
- Mix a few orthogonal signals: Text, DOM visibility, network status, URL progress.
- Keep a sparse success label: A binary “task_done” for evaluation and as a terminal bonus.
Anti‑gaming:
- Use network corroboration for any UI success banner.
- Use visibility and occlusion checks to prevent scrolling to hidden sections and farming text similarity.
- Penalize actions that only manipulate the view (e.g., zoom, CSS toggles) without network or semantic progress.
RLHF + RLAIF: building a preference dataset that scales
Even with well‑engineered shaping, a learned reward model (RM) trained on preference data makes the signals more robust across websites and tasks.
Data collection strategy:
- Start with off‑policy trajectories from heuristics, scripted baselines, or a supervised agent (behavior‑cloned from demonstrations).
- Break trajectories into segments (2–8 steps) and create pairwise comparisons (A vs B) for the same instruction.
- Ask labelers or an LLM judge: “Which segment makes better progress toward the goal? Why?”
- Label keys: preferred, not_preferred, tie/unclear. Include rationale for auditing and potential chain‑of‑thought inspection (don’t train on rationale directly unless you’re careful about leakage).
LLM‑as‑judge prompt (calibrated and rubric‑driven):
Task: <user instruction>
Given two browser trajectory segments with DOM/network deltas and key UI events, pick which segment makes better progress toward the task. Consider:
- Did the agent navigate closer to a page containing target entities?
- Did a successful form submission occur (2xx net response)?
- Are error banners or validation messages present?
- Is the target element visible and interactable?
- Avoid preferring cosmetic changes without semantic progress.
Return one of: A, B, or Tie. Provide a one‑sentence justification.
Quality controls for RLAIF:
- Gold tasks with known answers to measure judge accuracy.
- Calibrate the judge’s temperature low and use a deterministic rubric.
- Use a small seed of human‑labeled pairs to fit a judge debiasing/calibration layer (e.g., isotonic regression on judge scores to match human preferences).
- Active sampling: ask the judge to label pairs where the current RM is uncertain.
Fitting the reward model:
- Architecture inputs:
- DOM tokens: linearized subtree around interacted elements with attributes (id/class/role/aria) and text snippets.
- Layout features: bounding boxes, visibility, z‑index, overlap counts.
- Network features: recent response codes, endpoints, request types.
- Action tokens: tool/action type, selector, text length, key flags (submit, navigation).
- Instruction embedding: task description text.
- Model options:
- Tree‑aware transformer over DOM tokens (node type + attributes) with positional encodings from DOM paths.
- Cross‑encoder that fuses instruction embedding with DOM/action features.
- Optional vision branch (ViT) over screenshot crops around clicked elements if visual cues are critical.
Objective:
- Pairwise preference loss: Given segments A and B with returns computed by RM, maximize log(sigmoid(R(A) − R(B))) for preferred A. You can also train with DPO/IPO style objectives directly on policy vs reference, but a classic Bradley–Terry/Luce preference model works well.
- Regularization: KL penalties to avoid extreme scores; dropout on features to improve robustness across sites.
Data structure example for a preference pair:
json{ "instruction": "Download the latest invoice as PDF", "segment_A": { "actions": [ {"type": "click", "selector": "#account-menu"}, {"type": "click", "selector": "a[href='/billing']"} ], "dom_summary": "Billing link now visible; table of invoices present", "net_summary": [{"status": 200, "url": "/api/invoices"}] }, "segment_B": { "actions": [ {"type": "scroll", "y": 2000}, {"type": "click", "selector": "#footer"} ], "dom_summary": "No invoice table; footer links only", "net_summary": [] }, "label": "A", "rationale": "A navigates into Billing and loads invoices; B is cosmetic only" }
Safe on‑policy rollouts: gate all writes with stubs and sandboxes
Eventually you must train on‑policy to beat distribution shift and reward hacking. But on real websites, on‑policy must be safe by design. Divide environments into tiers and apply effect gating:
Safety tiers:
- Offline replay: No live traffic. Use recorded sessions; agent acts but effects are simulated via recorded diffs.
- Sandbox: Clone or staging environment with seeded data; network is rewritten to staging hosts.
- Shadow mode: Live site with write stubs; agent issues “write” intents, but actual submits/POSTs are blocked and simulated.
- Controlled writes: Limited allowlisted endpoints and test accounts, with quotas and rollback plans.
Write stubs interpose on every effectful operation:
- Network layer: Intercept fetch/XHR/WebSocket; allowlist GETs; convert POST/PUT/DELETE to no‑ops that return canned responses or staging mirrors.
- DOM layer: Intercept form.submit() and click() on elements with data-danger, type=submit, or matching configured selectors; replace with a synthetic success path if allowed.
- System layer: Block file downloads except to a sandbox directory; hash and sanitize filenames.
Playwright/Chromium example: intercept network writes
tsimport { chromium, Request } from 'playwright'; const WRITE_METHODS = new Set(['POST', 'PUT', 'PATCH', 'DELETE']); function isWrite(url: string, method: string): boolean { if (!WRITE_METHODS.has(method)) return false; // deny by default; allowlist specific hosts/paths try { const u = new URL(url); if (u.hostname.endsWith('.staging.example.com')) return true; // sandbox return false; } catch { return true; } } (async () => { const browser = await chromium.launch(); const context = await browser.newContext({ acceptDownloads: false }); const page = await context.newPage(); await page.route('**/*', async (route) => { const req = route.request(); if (isWrite(req.url(), req.method())) { // Emit a stubbed event; do not let the write hit the network await route.fulfill({ status: 200, body: JSON.stringify({ stubbed: true }) }); // log safety event console.log(JSON.stringify({ kind: 'safety.event', type: 'write_stub', url: req.url(), method: req.method() })); } else { await route.continue(); } }); })();
DOM submit gating via injected script:
js// Injected into every page (function () { const blockSubmit = (e) => { const form = e.target.closest('form'); if (!form) return; const url = (form.action || location.href); const method = (form.method || 'GET').toUpperCase(); const isWrite = ['POST','PUT','PATCH','DELETE'].includes(method); if (isWrite) { e.preventDefault(); window.postMessage({ kind: 'safety.event', type: 'form_submit_blocked', url, method }, '*'); // Optionally simulate a success banner const banner = document.createElement('div'); banner.className = 'agent-stub-success'; banner.textContent = 'Action simulated in sandbox.'; document.body.prepend(banner); } }; document.addEventListener('submit', blockSubmit, true); })();
Operational guardrails:
- Rate limits per domain; concurrency caps; circuit breakers if error rates spike.
- Test accounts only; secrets vaulted; no production credentials in rollout workers.
- Domain allowlists/denylists version‑controlled; changes require code review.
- Safety telemetry: every blocked effect is logged and reviewed.
From reward model to policy: DPO/PPO hybrids with KL control
Once you have a trained RM, use it to improve the agent policy while staying close to a safe reference model.
Pragmatic approach:
- Start with a supervised policy (BC) trained on demonstrations plus high‑return off‑policy traces.
- Fine‑tune with:
- DPO/IPO: Direct preference optimization between current vs reference policy using the RM or raw pairwise prefs.
- PPO/GRPO: On‑policy RL steps with the RM as the reward signal. Add a strong KL penalty to the reference to avoid collapse.
- Mix in behavior cloning (BC) on high‑quality human traces during early epochs to stabilize.
Pseudocode for a PPO step with RM and KL regularization:
python# Assume: policy pi_theta, reference policy pi_ref (frozen), reward model R_phi for epoch in range(E): trajs = collect_on_policy_trajectories(pi_theta, env, safety_stubs=True) # compute stepwise rewards via RM on dom/net diffs rewards = [R_phi(traj.step_features) for traj in trajs] # compute KL per step to reference kl_pen = [kl_div(pi_theta.logits(s), pi_ref.logits(s)) for s in trajs.states] shaped_rewards = [r - beta * kl for r, kl in zip(rewards, kl_pen)] # standard PPO update advantages = compute_gae(trajs, shaped_rewards) update_policy_with_ppo(pi_theta, trajs, advantages)
Tips:
- Anneal beta (KL weight) based on return drift; increase beta when RM return spikes without success rate improvement (reward hacking alarm).
- Use clipped value loss if you train a critic; otherwise, advantage estimation from returns is fine for short horizons.
- Keep episodes short (10–20 steps) with early stop when success banner/URL achieved in sandbox.
Putting DOM diff shaping into practice
DOM differencing strategy:
- Represent DOM as a sequence of nodes with stable IDs (XPath path hash). Include attributes relevant for interactivity (role, aria‑*, disabled, href, onclick).
- Use a tree diff algorithm (e.g., Zhang–Shasha) or a practical JSON Patch approach over a serialized tree.
- Extract feature deltas:
- added_nodes, removed_nodes counts
- text_changed_nodes count and TF‑IDF similarity shift toward goal text
- visibility changes for target selectors
- click target properties (was interactive? disabled? overlapped?)
- Maintain a per‑element interaction history to avoid rewarding the same discovery repeatedly (diminishing returns).
Example of a DOM patch fragment (JSON Patch style):
json[ {"op": "replace", "path": "/body/div[2]/div[1]/@class", "value": "alert alert-success"}, {"op": "add", "path": "/body/div[3]/ul/li[5]", "value": {"tag": "li", "text": "Invoice INV-1029"}} ]
Mapping to rewards:
- If a replace introduces class containing "alert-success", add +0.2 (with network corroboration in last 2s).
- If a new list item contains regex INV-[0-9]+, add +0.1 and set a latent “target_present” flag.
- Penalize large removals without a navigation event.
Worked example: “Find the product price and copy it”
Instruction: “On the product page, find the current price and copy it to clipboard.”
A naive success check might be: price element exists and clipboard.changed=true. But live sites vary widely. Here’s a shaped approach:
Signals:
- DOM: presence of selectors matching common price patterns: [data-test='price'], .price, [itemprop=price], meta[itemprop=price], text matching currency regex near “Add to cart”.
- Visibility: ensure price element is in viewport and not obscured.
- Network: ensure no 4xx/5xx after interaction; optional schema.org/JSON‑LD includes price.
- Clipboard: intercept navigator.clipboard.writeText; compare against extracted price string.
Reward steps example:
- Agent clicks “Details” tab; DOM adds a div.price with text “$129.00”. Reward: +0.2 (element visibility) +0.1 (regex match) = +0.3.
- Agent scrolls to bring price into viewport. Reward: +0.05 (visibility improvement).
- Agent selects text near price; triggers copy. navigator.clipboard.writeText called with "$129.00". Reward: +0.4 (target copied) and end episode with success flag.
Clipboard stub:
js// Injected safe clipboard stub (async function(){ const originalWriteText = navigator.clipboard && navigator.clipboard.writeText; navigator.clipboard.writeText = async (text) => { window.postMessage({ kind: 'env.clipboard', text_len: (text||'').length, hash: await sha256(text||'') }, '*'); // Optionally, in sandbox allow actual copy; in shadow mode, no-op if (window.__SANDBOX__) return originalWriteText ? originalWriteText(text) : undefined; return undefined; }; })();
Shaping function fragment:
pythondef price_extraction(dom): # search common patterns candidates = dom.find_price_candidates() # returns [(text, visible, bbox), ...] best = None for t, vis, bbox in candidates: if vis and re.search(r"[$€£]\s?\d[\d,]*(?:\.\d{2})?", t): best = t; break return best r = 0.0 prev_price = price_extraction(dom_before) curr_price = price_extraction(dom_after) if not prev_price and curr_price: r += 0.2 if clipboard_event and curr_price and similar(clipboard_event.text, curr_price) > 0.9: r += 0.4; success = True
This example illustrates how DOM/network/clipboard hooks create a gradient of progress that a general reward model can internalize across sites.
Evaluation: measure the right things, catch reward hacks
Benchmarks and datasets to consider:
- MiniWoB++: micro‑browser tasks; good for quick iteration.
- WebArena and Mind2Web: more realistic multi‑step tasks across multiple sites.
- AgentBench and BrowserGym‑like suites: agent tool interaction with web.
Metrics:
- Success rate on held‑out tasks (binary terminal success labels).
- Step‑efficiency: median steps to success.
- Safety incidents per 1k episodes: blocked writes, attempted PII exfiltration (stubbed), domain rule violations.
- Reward‑success calibration: correlation between RM return and true success; calibration curves over deciles.
Reward hack detection:
- Returns spike without success rate improvement.
- High rewards dominated by a single component (e.g., text similarity). Add caps, add corroboration signals.
- Frequent triggering of cosmetic success classes without network corroboration.
Offline validation:
- Use counterfactual evaluation: with logged propensities from the behavior policy, estimate expected return of candidate policies before rollout. Doubly robust estimators help, though high variance is expected for long horizons.
Opinionated takes: what works and what doesn’t
- Combine DOM and network; screenshots alone are insufficient. Visual‑only agents miss crucial semantics like hidden validation errors or SPA route changes.
- Don’t overfit to selectors. Reward models should not require exact CSS selectors in task specs; instead, use multi‑signal heuristics (role, proximity, text semantics) and let the RM learn.
- RLAIF is a force multiplier but must be calibrated. An uncalibrated judge can entrench spurious correlations. Always mix in human seeds and monitor judge drift.
- On‑policy rollouts are necessary for robustness. Off‑policy pretraining saturates quickly; your agent needs to feel real latency, network variance, and anti‑automation defenses—in a safe harness.
- Build safety in code, not by policy alone. Effect gating, allowlists, and stubs must be part of the runtime. Relying on “we won’t click destructive buttons” is not a strategy.
Practical infrastructure blueprint
- Browser workers: Playwright/Puppeteer drivers with CDP access; run in isolated containers with no file system writes, no external network except allowlisted domains.
- Telemetry pipeline: Kafka for events; Flink/Spark streaming jobs to materialize dom.diff and basic shaping; ClickHouse for ad‑hoc queries; S3 Parquet lake for long‑term.
- Feature store: Embeddings/features for RM training stored per step with keys (session_id, seq).
- Training stack: PyTorch/JAX for RM and policy; DPO/PPO trainers with KL control; Weights & Biases/MLflow for experiment tracking.
- Labeling: Internal UI for human preferences; LLM judge service with cached decisions and gold task gating.
- Safety config: Central repository for domain rules, allowlists, and stub behaviors; CI tests to assert that critical paths remain blocked.
Cost tips:
- Snapshot sparingly: Full DOM snapshots every N steps; diffs in between. Compress with zstd.
- Screenshots only when needed for visual cues; crop around interacted elements.
- Use event sampling on high‑volume net requests; store hashes not bodies unless allowlisted.
Minimal end‑to‑end loop: code sketch
python# Pseudocode combining all pieces def training_iteration(task_batch): # 1) Collect on-policy data in sandbox/shadow mode trajs = [] for task in task_batch: traj = run_episode(task, stubs=True, safety_rules=RULES) trajs.append(traj) emit_events(traj) # event-sourced logs # 2) Compute shaped rewards (online + richer offline pass) for traj in trajs: traj.shaped_rewards = [reward_computer.compute(w) for w in sliding_windows(traj)] # 3) Sample segments; gather preferences from humans + LLM judge pairs = make_pairs(trajs) labeled_pairs = label_with_humans(pairs_subset(pairs)) + label_with_llm_judge(pairs) # 4) Train reward model from preferences R_phi = train_reward_model(labeled_pairs, features=extract_features(trajs)) # 5) Policy improvement with RM rewards + KL regularization update_policy_with_ppo(policy, trajs, rewards=score_with(R_phi, trajs), kl_to=ref_policy) # 6) Evaluation on held-out tasks + safety audit eval_report = evaluate(policy, heldout_tasks, stubs=True) safety_report = audit_safety_telemetry() return eval_report, safety_report
A short checklist to implement this in your org
- Instrumentation
- CDP driver emits UI, DOM, network, and screenshot events
- Event‑sourced pipeline with schemas and PII redaction
- DOM diff materialization and basic shaping in stream jobs
- Reward modeling
- Define task‑agnostic shaping: visibility, text, network, URL progress
- Implement task‑specific hooks where applicable (selectors, regexes)
- Build preference dataset; seed with human labels; add LLM judge with calibration
- Train RM with pairwise loss; monitor calibration vs success
- Safety
- Write stubs for network and DOM submits; allowlists and rate limits
- Shadow/sandbox modes with test accounts
- Safety telemetry and alerts; incident review process
- Policy learning
- Start from BC; add DPO/PPO with KL to reference
- On‑policy rollouts with early stopping and budget caps
- Evaluate on held‑out tasks and real‑world canaries
References and further reading
- Ouyang et al., Training language models to follow instructions with human feedback (InstructGPT): https://arxiv.org/abs/2203.02155
- Bai et al., Constitutional AI: https://arxiv.org/abs/2212.08073
- Rafailov et al., Direct Preference Optimization (DPO): https://arxiv.org/abs/2305.18290
- Christiano et al., Deep RL from Human Preferences: https://arxiv.org/abs/1706.03741
- MiniWoB++: https://miniwob.farama.org/
- WebArena: https://webarena.dev/
- Mind2Web: https://arxiv.org/abs/2306.06070
- Martin Fowler on Event Sourcing: https://martinfowler.com/eaaDev/EventSourcing.html
- Playwright docs (network interception): https://playwright.dev/docs/network
Closing thoughts
Reward models for browser agents live or die on the quality of their signals and the safety of their rollouts. DOM and network diffs provide the best available substrate for dense shaping; event‑sourced telemetry makes the learning loop reproducible and auditable; mixing human and calibrated LLM preferences scales supervision; and write stubs make on‑policy improvement possible without risking production data.
Put differently: don’t wait for a perfect general web benchmark or a single monolithic success metric. Start capturing rich telemetry, engineer robust shaping that correlates with progress, train a preference‑based reward model, and iterate on‑policy under a strict safety harness. Agents trained this way become not just better at clicking—but better at understanding when clicks actually move the task forward.