Why site‑aware RAG for browser agents now
Autonomous browser agents are breaking out of demos and into daily workflows: scraping dashboards for KPIs, filing expenses, booking travel, or triaging customer tickets in legacy portals. Yet the largest failure mode remains control—not text generation.
Language models are adept at “what to do,” but their default approach to “how to click it” is brittle. Hard-coded CSS selectors shatter on trivial redesigns. Blind crawling wastes time and money. And every login flow is a snowflake until it isn’t.
A practical answer is site‑aware RAG for control: build per‑origin indices of affordances—the actionable semantics of a site, distilled from accessibility trees, labeled forms, and sitemaps—and retrieve task‑specific playbooks at runtime. Pair it with drift‑aware refresh pipelines so the index stays fresh without hammering sites or leaking user data.
This article lays out an opinionated, production‑minded blueprint. We’ll cover:
- What an “affordance index” is and why origin scope matters
- Ingesting a11y roles, form schemas, and sitemaps (plus robots.txt and schema.org hints)
- Designing hybrid retrieval for control (lexical + vector + structural filters)
- Playbooks as first‑class retrievables and how to execute them safely
- Detecting drift and refreshing indices with low cost and low risk
- PII‑safe storage and runtime redaction
- A working reference implementation in Python with Playwright, SQLite FTS5, and FAISS/Qdrant
- Metrics, pitfalls, and a roadmap to make it robust
If you currently rely on LLMs to “figure out the UI on the fly,” you’re paying latency and reliability taxes. Site‑aware RAG pays a one‑time cost per origin and amortizes it across tasks and users.
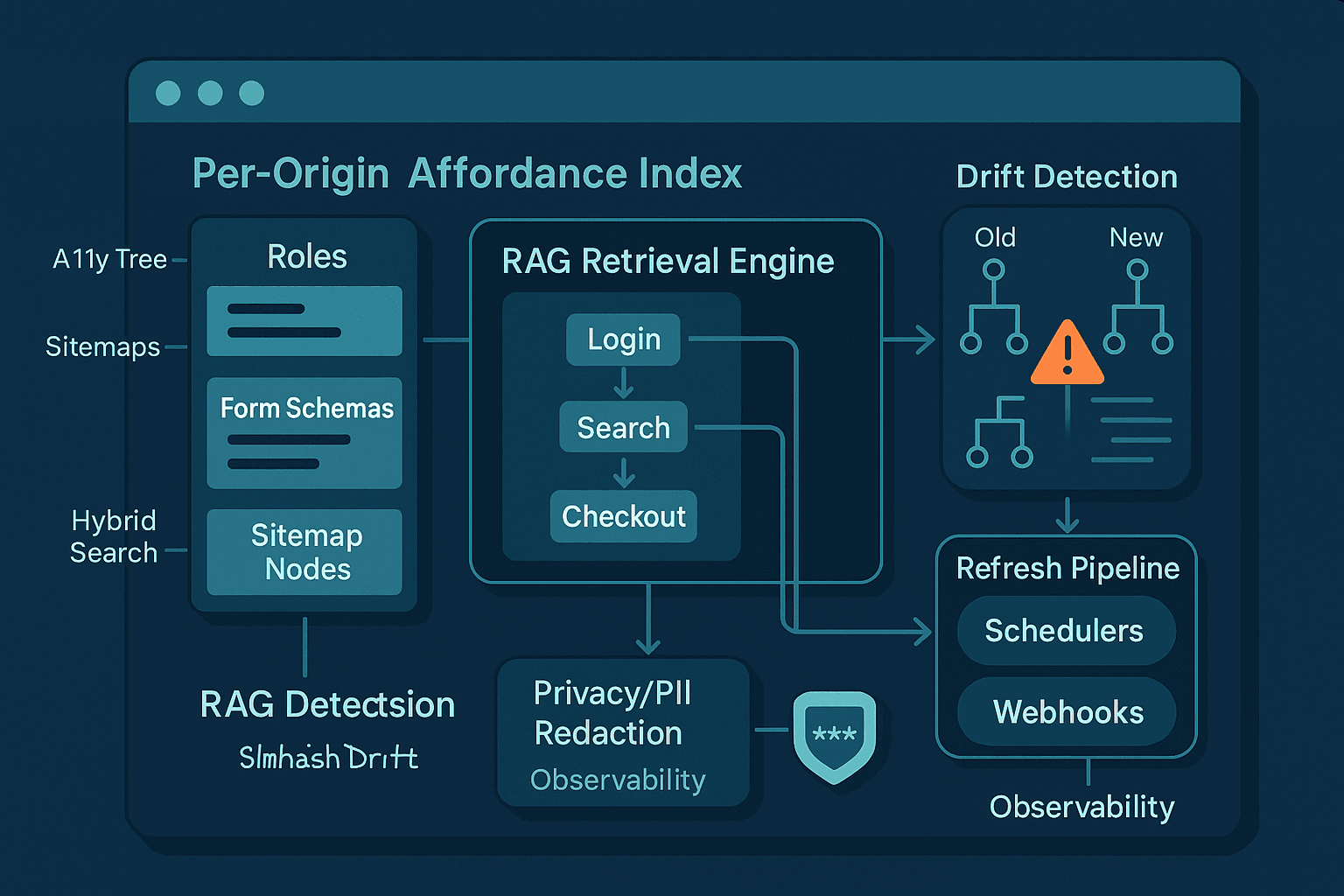
The core idea: retrieval‑augmented control at per‑origin scope
RAG for text generation retrieves passages. RAG for control retrieves affordances: the structured opportunities an interface presents to act.
- Scope: per origin (ideally per eTLD+1), e.g., github.com or portal.company.com
- Unit: an AffordanceDoc that describes an actionable element or workflow segment:
- Location: URL, route pattern, and stable anchors (e.g., a11y roles + labels rather than brittle selectors)
- Semantics: role (button, link, menuitem, textbox), accessible name, form field labels/types, constraints
- Preconditions/postconditions: auth state, expected nav changes, result cues
- Evidence: snippets of the a11y tree, surrounding text, screenshot hashes
- Provenance: when seen, by which crawler, confidence score
We then:
- Ingest and index these docs per origin.
- At runtime, the agent forms an intent query (e.g., “upload PDF invoice to Acme portal”).
- Retrieve candidate affordances and playbooks that match the origin and intent.
- Execute with verification loops, logging feedback to refine the index.
This separation—local, reusable knowledge vs. transient intent—keeps agents fast and consistent.
Why per origin? Stability and responsibility
Treat “origin” (scheme + host + port) or at least eTLD+1 as the atomic unit. Benefits:
- Stability: Most UI changes are local to a site. Reusing per‑origin indices yields high cache hit rates.
- Governance: You can respect robots.txt, per‑site rate limits, and legal terms consistently.
- Safety: Fine‑grained privacy policies and redaction rules by origin (e.g., strip account numbers on banking domains).
Use the public suffix list to canonicalize eTLD+1 and then bind indices to that scope.
Affordance schema
You need a schema that captures control‑useful semantics without overfitting to transient CSS. A minimal AffordanceDoc:
json{ "origin": "portal.acme.com", "url": "https://portal.acme.com/invoices/new", "route": "/invoices/new", "a11y": { "role": "textbox", "name": "Invoice Number", "aria": { "required": true } }, "form": { "form_name": "New Invoice", "field_name": "invoice_number", "input_type": "text", "constraints": { "pattern": "^[A-Z0-9-]{5,20}$" } }, "anchors": { "by_role_name": ["role=textbox", "name=Invoice Number"], "near_text": ["Invoice Details"], "data_testid": null }, "actions": [ { "type": "fill", "value_kind": "alphanumeric-id" }, { "type": "validate", "cue": "No validation errors" } ], "evidence": { "snippet": "label: Invoice Number, input[type=text]", "screenshot_phash": "f1c2..." }, "last_seen": "2026-02-10T12:00:00Z", "hash": "simhash:a11y=9f33b2", "confidence": 0.92 }
The crucial pieces for retrieval are the role/name and form semantics; the crucial pieces for control are the anchors and actions.
Ingestion: how to crawl once and capture durable semantics
You want to move beyond naive DOM scraping and invest in sources that are both stable and explicit:
- Accessibility tree (a11y): Roles, names, states—built for assistive tech; exactly what an agent needs to understand the UI logically. Extract via Playwright or CDP.
- Forms: Labels, input types, constraints (pattern, required), hidden fields, and submit buttons. Also mark hazards (passwords, 2FA, file inputs).
- Sitemaps: Enumerate canonical entry points and update cadence (via lastmod). Integrate robots.txt rules to respect crawl policies.
- Schema.org and HTML semantics: itemprop, rel attributes (e.g., rel="next", rel="search"), link headers, canonical tags.
- Performance hints: ETag, Last-Modified headers for drift detection.
A11y snapshot with Playwright (Python)
pythonimport asyncio from playwright.async_api import async_playwright async def snapshot_accessibility(url): async with async_playwright() as p: browser = await p.chromium.launch(headless=True) context = await browser.new_context() page = await context.new_page() await page.goto(url, wait_until="domcontentloaded") # Expand hidden nodes to capture actionable items tree = await page.accessibility.snapshot(root=None, interesting_only=False) await browser.close() return tree if __name__ == "__main__": tree = asyncio.run(snapshot_accessibility("https://portal.acme.com/invoices/new")) print(tree)
Transform that tree into affordances by walking nodes and collecting nodes with actionable roles:
- Buttons, links, menuitems, comboboxes, listboxes
- Textboxes, searchboxes, spinbuttons
- Checkboxes, radios, switches
- File inputs (flag for special handling)
Form extraction heuristics
- Prefer label->for associations and aria-labelledby.
- When ambiguous, compute proximity via DOM and a11y name.
- Capture patterns and required from native attributes and ARIA.
- Detect submit triggers: role=button with type=submit, Enter key handlers, or ARIA pressed toggles.
Sitemaps and robots
- robots.txt: Respect Disallow and crawl‑delay. Parse with an allowlist of user agents; set your agent string explicitly.
- sitemap.xml: Handle index sitemaps. Use <lastmod> to prioritize.
pythonimport requests from urllib.parse import urljoin import xml.etree.ElementTree as ET def fetch_sitemaps(origin_base): robots_url = urljoin(origin_base, "/robots.txt") r = requests.get(robots_url, timeout=10) sitemaps = [] if r.status_code == 200: for line in r.text.splitlines(): if line.lower().startswith("sitemap:"): sitemaps.append(line.split(":", 1)[1].strip()) if not sitemaps: sitemaps.append(urljoin(origin_base, "/sitemap.xml")) return sitemaps def parse_sitemap(url): r = requests.get(url, timeout=10) urls = [] if r.status_code == 200: root = ET.fromstring(r.text) ns = {'sm': 'http://www.sitemaps.org/schemas/sitemap/0.9'} if root.tag.endswith('sitemapindex'): for loc in root.findall('.//sm:loc', ns): urls.extend(parse_sitemap(loc.text)) else: for url_el in root.findall('.//sm:url', ns): loc = url_el.find('sm:loc', ns).text lastmod = url_el.find('sm:lastmod', ns) urls.append((loc, lastmod.text if lastmod is not None else None)) return urls
Schema.org and link relations
- Parse JSON‑LD for item types like SearchAction, Offer, Product, Article.
- Link rel="search" (OpenSearch), rel="next"/"prev" for pagination.
These hints seed playbooks (e.g., search flows) and help constrain navigation.
Index design: hybrid search with structural gating
Control retrieval is best served by hybrid search:
- Lexical (BM25/FTS): For exact label matches (e.g., "Invoice Number").
- Vector embeddings: For semantic matches ("billing id" ~ "invoice number").
- Structural filters: Role == textbox; origin == portal.acme.com; route prefix == /invoices.
Keep the index small and fast per origin. Store only what’s needed:
- Affordance text fields: role, name, labels, context snippet
- Numeric/enum fields: role_type, form_field_type, required, pattern hash
- Anchors: prefer role+name over CSS
- Evidence hashes (not images) for drift checks
A simple, fast stack:
- SQLite with FTS5 for lexical + JSON columns for metadata
- FAISS or Qdrant for vector search (per origin, small shards)
SQLite FTS5 schema
sqlCREATE TABLE affordances ( id INTEGER PRIMARY KEY, origin TEXT NOT NULL, url TEXT NOT NULL, route TEXT, role TEXT, name TEXT, form_name TEXT, field_name TEXT, input_type TEXT, required INTEGER, constraints_json TEXT, anchors_json TEXT, evidence_json TEXT, last_seen TEXT, hash TEXT, confidence REAL ); CREATE VIRTUAL TABLE affordances_fts USING fts5( name, field_name, form_name, content='affordances', content_rowid='id' ); CREATE INDEX idx_affordances_origin ON affordances(origin); CREATE INDEX idx_affordances_role ON affordances(role); CREATE INDEX idx_affordances_url ON affordances(url);
Vector fields
Choose a compact, domain‑tuned model for UI semantics, e.g., a sentence‑transformer fine‑tuned on role/name/label triplets.
pythonfrom sentence_transformers import SentenceTransformer import numpy as np model = SentenceTransformer("all-MiniLM-L6-v2") def affordance_text(doc): parts = [doc.get('role', ''), doc.get('name', ''), doc.get('field_name', ''), doc.get('form_name', '')] return " | ".join([p for p in parts if p]) embedding = model.encode([affordance_text(doc)], normalize_embeddings=True) # store embedding in FAISS or Qdrant keyed by affordance id
Playbooks: reusable, verifiable task sequences
Affordances are atoms. Playbooks are molecules—small, verifiable workflows like “login with username/password,” “search and open first result,” “create new invoice.” Make playbooks retrievable per origin and intent.
A playbook DSL should:
- Target an origin and (optionally) a route prefix
- Specify preconditions (logged out, logged in, CSRF token present)
- Sequence steps that bind to affordances by constraints (role, name, field type)
- Include runtime checks (URL change, toast appears, a11y alert region) and timeouts
- Declare hazards (mfa_required, captcha_present) and fallbacks
Example YAML:
yamlorigin: portal.acme.com name: login_basic version: 3 preconditions: state: logged_out steps: - wait_for: url: "https://portal.acme.com/login" timeout_ms: 8000 - fill: match: { role: textbox, name: "Email" } value_from: secret_store.user_email - fill: match: { role: textbox, name: "Password" } value_from: secret_store.user_password secure: true - click: match: { role: button, name: "Sign in" } - assert: any: - a11y_alert_contains: "Welcome" - url_startswith: "https://portal.acme.com/dashboard" postconditions: state: logged_in hazards: - mfa_possible - captcha_possible
Store playbooks alongside affordances and index them (title, description, steps summary). Retrieval often returns both:
- Affordances for immediate actions
- Playbooks for short multi‑step flows
At runtime, the agent forms a control query:
json{ "origin": "portal.acme.com", "intent": "upload invoice pdf and submit", "state": "logged_in", "url": "https://portal.acme.com/invoices/new" }
Hybrid retrieval returns:
- Playbook candidates: create_invoice, upload_attachment, submit_form
- Affordance candidates: role=file upload (name=Upload PDF), role=button (name=Submit)
The agent resolves conflicts and executes with verification and backoff.
Runtime retrieval algorithm (sketch)
- Localize: Confirm the current origin and canonical route; map to the right index shard.
- Derive query: intent + current route + state + last observed cues (e.g., "error: invalid invoice number").
- Retrieve playbooks: top‑k by semantic match + structural filter by route.
- Retrieve affordances: top‑k by match; filter by role/type needed for next step.
- Bind and act: prefer anchors with high stability (role+name, aria attributes). Avoid brittle selectors.
- Verify: use a11y alerts, toasts, heading changes, network events, or URL transitions.
- Log: Success/failure events update affordance confidence; ambiguous steps are candidates for human review.
Pseudocode:
pythoncands_pb = playbook_index.retrieve(intent, origin, filters={"route_prefix": route_prefix}) next_pb = select_playbook(cands_pb, state) for step in next_pb.steps: need = step.match cands_aff = affordance_index.retrieve( text=query_from(step, context), origin=origin, filters={"role": need.role, "route": route} ) bound = disambiguate(cands_aff, page_state) act(bound, step) assert verify(step.assertions, page_state)
Drift detection and refresh without waste
Web UIs drift. You want to detect relevant changes quickly without recrawling every page daily.
Signals:
- a11y tree fingerprint: Build a SimHash or MinHash over role/name sequences and landmark structure.
- Evidence hashes: Per critical affordance, maintain screenshot perceptual hash (pHash) of a small bounding box.
- HTTP freshness: ETag/Last-Modified for pages and assets; if unchanged, skip deep scan.
- Sitemap lastmod: Guides crawling priority.
- Runtime canaries: If an execution step fails more than N times, flag route for re‑ingestion.
SimHash for a11y fingerprints
pythonfrom simhash import Simhash def a11y_fingerprint(a11y_tree): tokens = [] def walk(node, depth=0): role = node.get('role') or '' name = (node.get('name') or '').lower() if role: tokens.append(f"{depth}:{role}") if name: tokens.append(f"n:{name}") for child in (node.get('children') or []): walk(child, depth+1) walk(a11y_tree) return Simhash(tokens).value # Compare previous vs current; if Hamming distance > threshold, route flagged
Stale‑while‑revalidate (SWR) strategy
- Hot routes (recently used): Re‑fingerprint on a schedule (e.g., 6–24 hours) with low‑impact checks (HEAD, ETag, then partial a11y snapshot on first byte change).
- Cold routes: Rely on sitemap lastmod and runtime canaries to trigger refresh.
- Batch updates: Use a queue (e.g., SQS/Kafka) for refresh jobs with per‑origin concurrency limits.
Refresh pipeline outline
- Scheduler: picks candidates considering rate limits and robots.
- Fetcher: lightweight check first (ETag/Last-Modified). If changed, do full a11y snapshot.
- Differ: compute fingerprints and update only changed affordances/playbooks.
- Reviewer: auto‑approve low‑risk updates; queue high‑drift changes for human review.
- Notifier: emit events to invalidate caches.
PII and privacy: index structure, not secrets
The fastest way to lose access and trust is to leak user data. Principles:
- Data minimization: Store only structure: labels, roles, constraints, route patterns. Never store example values.
- Redaction: At ingestion, scrub anything that looks like PII (emails, phone numbers, IDs) in text snippets and evidence.
- Separation of concerns: Runtime secrets (passwords, tokens) live only in a secure secret store and never touch the index.
- Differential storage by origin: Some origins may ban any storage of text snippets—respect and comply.
- Ephemeral runtime logs: Trace action types and success/failure, but hash or redact content.
Simple redaction in Python (use a real PII tool in prod)
pythonimport re EMAIL_RE = re.compile(r"[a-zA-Z0-9_.+-]+@[a-zA-Z0-9-]+\.[a-zA-Z0-9-.]+") PHONE_RE = re.compile(r"\+?\d[\d\s().-]{7,}\d") ACCT_RE = re.compile(r"\b\d{8,16}\b") REPLACEMENTS = [EMAIL_RE, PHONE_RE, ACCT_RE] def redact(text: str) -> str: if not text: return text t = text for r in REPLACEMENTS: t = r.sub("<redacted>", t) return t
For production, integrate Microsoft Presidio, spaCy NER, or a policy engine to support per‑origin rules.
Evidence storage
- Store perceptual hashes rather than screenshots.
- If you must store screenshots (e.g., for review), encrypt at rest, access‑control by origin, and scrub overlays.
Observability with privacy
- Use OpenTelemetry spans for steps, but attributes hold enums and hashes, not raw strings.
- Maintain a PII budget per origin; drop logs when signals exceed thresholds.
Reference implementation blueprint
We’ll sketch a minimal stack you can scale:
- Crawler: Playwright (headless Chromium) + Python asyncio
- Ingestion: a11y snapshot, form parser, sitemap walker
- Index: SQLite FTS5 + FAISS (or Qdrant if you want a managed vector DB)
- Orchestrator: runtime retrieval and execution
- Drift: SimHash fingerprints + ETag checks
- Privacy: simple redaction + secret store boundary
Data model
- SQLite tables: affordances, playbooks, routes, fingerprints
- Vector store keyed by affordance_id and playbook_id
sqlCREATE TABLE routes ( origin TEXT, url TEXT, route TEXT, e_tag TEXT, last_modified TEXT, a11y_fingerprint TEXT, last_seen TEXT, PRIMARY KEY (origin, url) );
Ingestion worker (simplified)
pythonimport time import json import sqlite3 async def ingest_route(db, origin, url): # 1) HEAD for ETag/Last-Modified # 2) If changed or unknown, navigate and snapshot a11y tree = await snapshot_accessibility(url) fp = a11y_fingerprint(tree) # 3) Extract affordances docs = extract_affordances(tree, url, origin) # your implementation # 4) Upsert into SQLite + FTS + vector store with sqlite3.connect(db) as conn: cur = conn.cursor() for d in docs: cur.execute( """ INSERT INTO affordances (origin,url,route,role,name,form_name,field_name,input_type,required,constraints_json,anchors_json,evidence_json,last_seen,hash,confidence) VALUES (?,?,?,?,?,?,?,?,?,?,?,?,?,?,?) ON CONFLICT(origin,url,role,name,field_name) DO UPDATE SET last_seen=excluded.last_seen, constraints_json=excluded.constraints_json, anchors_json=excluded.anchors_json, evidence_json=excluded.evidence_json, hash=excluded.hash, confidence=max(confidence, excluded.confidence) """, ( origin, d['url'], d.get('route'), d.get('role'), redact(d.get('name')), redact(d.get('form_name')), d.get('field_name'), d.get('input_type'), int(d.get('required') or 0), json.dumps(d.get('constraints', {})), json.dumps(d.get('anchors', {})), json.dumps(d.get('evidence', {})), time.strftime('%Y-%m-%dT%H:%M:%SZ', time.gmtime()), d.get('hash'), d.get('confidence', 0.5) ) ) # Update FTS cur.execute("INSERT INTO affordances_fts(rowid, name, field_name, form_name) VALUES (last_insert_rowid(), ?, ?, ?)", (redact(d.get('name') or ''), d.get('field_name') or '', redact(d.get('form_name') or ''))) conn.commit() # 5) Store route fingerprint with sqlite3.connect(db) as conn: conn.execute("INSERT OR REPLACE INTO routes(origin,url,route,a11y_fingerprint,last_seen) VALUES (?,?,?,?,?)", (origin, url, d.get('route'), str(fp), time.strftime('%Y-%m-%dT%H:%M:%SZ', time.gmtime())))
Retrieval (hybrid)
pythondef retrieve_affordances(db, origin, query_text, role=None, route=None, k=10): with sqlite3.connect(db) as conn: conn.row_factory = sqlite3.Row # Lexical ft = conn.execute("SELECT rowid, bm25(affordances_fts) as score FROM affordances_fts WHERE affordances_fts MATCH ? ORDER BY score LIMIT ?", (query_text, k*5)).fetchall() ids = [r['rowid'] for r in ft] # Metadata filter q = "SELECT * FROM affordances WHERE id IN ({seq}) AND origin=?".format(seq=','.join(['?']*len(ids))) params = ids + [origin] rows = conn.execute(q, params).fetchall() # Optionally combine with vector rerank here if role: rows = [r for r in rows if r['role'] == role] if route: rows = [r for r in rows if (r['route'] or '').startswith(route)] return rows[:k]
Execution bindings with a11y anchors (TypeScript + Playwright)
Favor Playwright’s role selectors and label matching:
tsimport { Page, expect } from '@playwright/test'; export async function actFillByRoleName(page: Page, role: string, name: string, value: string) { const locator = page.getByRole(role as any, { name }); await locator.waitFor({ state: 'visible', timeout: 5000 }); await locator.fill(value); } export async function actClickByRoleName(page: Page, role: string, name: string) { const locator = page.getByRole(role as any, { name }); await locator.waitFor({ state: 'visible', timeout: 5000 }); await locator.click(); }
This is far more stable than CSS/XPath guessing.
Evaluation: know if your index is paying rent
Track these metrics per origin:
- Index hit‑rate: fraction of steps resolved via index (vs. blind search)
- Selector stability: breakage rate of anchors over time
- Task success rate/time: end‑to‑end success and median latency
- Drift MTTD: mean time to detect UI changes that impact tasks
- Refresh efficiency: refreshes that actually changed the index / total refreshes
- Privacy budget: redacted tokens per MB logged
A/B test with and without site‑aware indices. Expect big wins on latency and success, especially for multi‑step forms.
Pitfalls and pragmatic guardrails
- Over‑scraping: Don’t crawl every path. Respect robots.txt and rate limits; seed via sitemaps and observed routes only.
- CSS addiction: Avoid CSS selectors as primary anchors. Use role+name and labeled relationships.
- PII leakage via snippets: Redact aggressively; drop evidence if in doubt.
- Giant embeddings: Keep per‑origin shards small. Compress text to key fields and use compact models.
- Playbook drift: Keep assertions strong but not brittle (use multiple cues). Auto‑disable failing playbooks and trigger refresh.
- CAPTCHA/MFA dead ends: Detect early; hand off to human or out‑of‑band auth providers. Don’t try to “solve” CAPTCHAs.
- State confusion: Persist and query state (logged_in, tenant_selected). Retrieval must be state‑aware.
Advanced topics
- Grammar‑constrained plans: Use JSON schema/toolformer style prompts so the LLM emits only known action types.
- Learning from logs: Mine successful trajectories to synthesize new playbooks. Guard with differential privacy if needed.
- Schema.org SearchAction: Autogenerate site search playbooks where available.
- Content security policy (CSP) awareness: Some sites block automation artifacts; design your agent to blend with standard headers and fingerprints ethically.
- On‑device indices: For enterprise privacy, keep per‑origin indices local to user machines and sync fingerprints only.
- Mixed‑initiative UI: Offer the user confirmable suggestions for high‑risk actions (submit, delete) with evidence screenshots.
A concrete end‑to‑end example: "Upload an invoice PDF to Acme"
- At startup, the agent receives: origin portal.acme.com; task: “upload invoice PDF and submit.”
- Agent verifies login state (cookie present). If not, retrieves login_basic playbook and executes it.
- On /invoices/new, the agent retrieves:
- Affordance: role=file input, name=“Upload PDF” (confidence 0.93)
- Affordance: role=textbox, name=“Invoice Number” (pattern ^[A-Z0-9-]{5,20}$)
- Affordance: role=button, name=“Submit”
- Playbook: create_invoice_v2 with steps fill->upload->submit->assert toast
- Execution binds anchors via getByRole; fills invoice number; uploads file; clicks Submit.
- Verification: waits for ARIA live region “Invoice submitted” or URL redirect to /invoices.
- Logs success; bumps confidence on used affordances. No PII (actual invoice number/file path) is stored.
- Two weeks later, Acme renames “Upload PDF” to “Attach file”. Runtime retrieval still matches via vector + role filter; minor drift detected by a11y SimHash; refresh pipeline re‑indexes the route and updates labels.
What to build first (90‑day plan)
- Week 1–2: Build per‑origin SQLite + FTS index; ingest sitemaps; basic a11y snapshot; extract and store 5–10 roles.
- Week 3–4: Add Playwright execution with getByRole; implement 3 playbooks: login, search, create.
- Week 5–6: Add FAISS reranking; standardize AffordanceDoc schema; start redaction; wire OpenTelemetry spans.
- Week 7–8: Drift fingerprints with SimHash; SWR scheduler; ETag/Last-Modified checks; canary‑triggered refresh.
- Week 9–10: Human review UI for high‑drift diffs; CI to run smoke playbooks per origin.
- Week 11–12: Metrics dashboards; A/B tests; harden privacy (per‑origin policies, encryption at rest for evidence).
Closing take
Site‑aware RAG moves the control problem from improvisation to retrieval. By investing in per‑origin affordance indices, you externalize UI knowledge into a durable, queryable asset. A11y trees and form semantics make this knowledge robust. Playbooks make execution predictable. Drift‑aware refresh keeps it current without harassing sites or leaking user data.
Don’t wait for a universal agent that “figures out any UI.” Put your agent on rails: retrieve, then act. Your latency will drop, your success rates will climb, and your security people will finally breathe again.