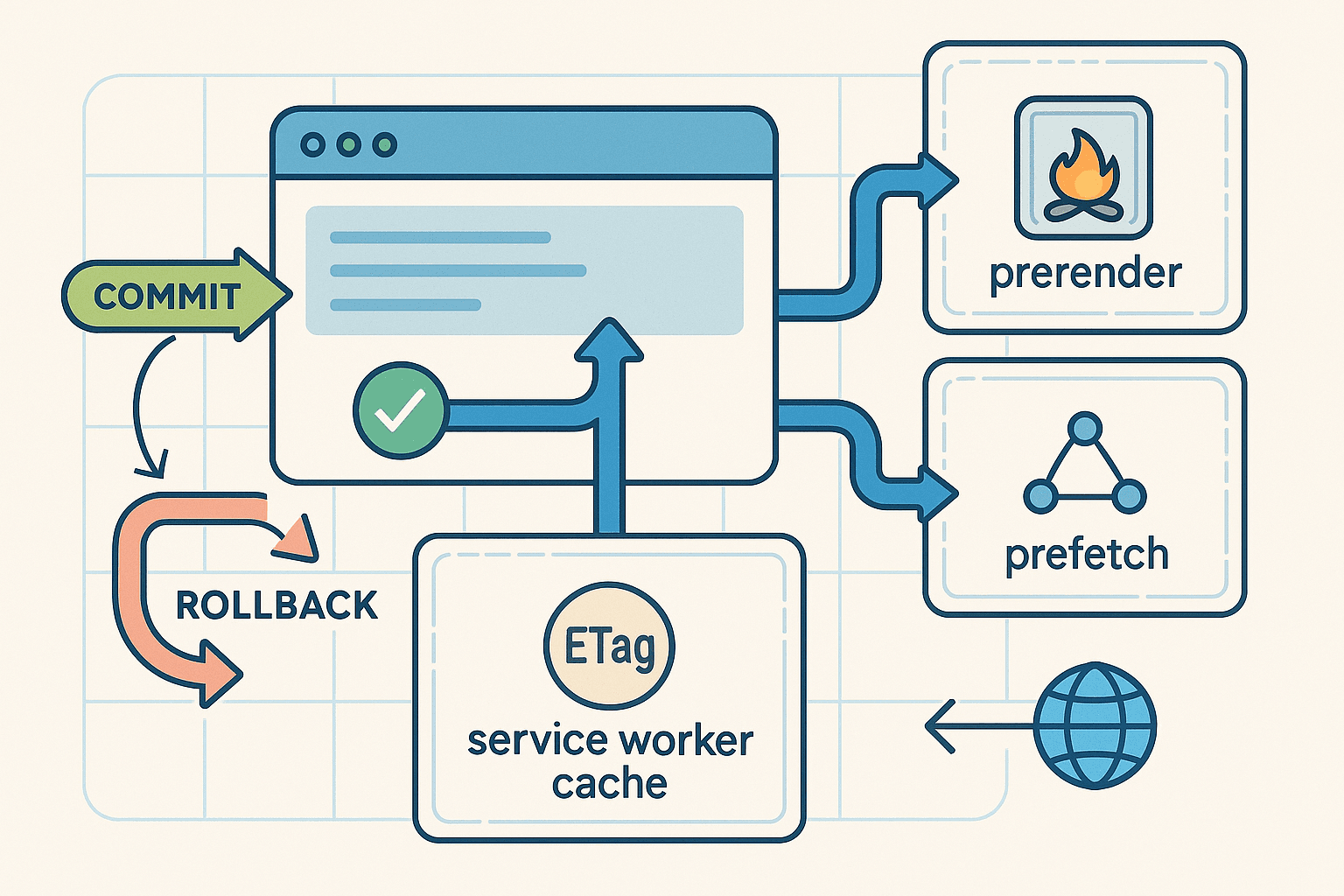
Speculative execution is not just for CPUs anymore. In the era of AI agents that browse, read, click, and fill forms on our behalf, waiting synchronously for each network hop or DOM update is a tax on throughput. The browser platform is finally mature enough to borrow the winning ideas from microarchitecture and distributed systems: branch and rollback, predictive prefetch, isolated sandboxes, and transactional commit.
This article proposes an AI-in-the-browser pipeline that predicts likely next actions, forks them into isolated contexts, prefetches and prerenders safely, confirms that speculations still match live state, then commits instantly or rolls back without leaving side effects. The goal: slash end-to-end latency for agentic workflows while respecting site policies and avoiding anti-bot triggers.
If you are building autonomous or semi-autonomous browser agents, developer tools, or high-performance frontends, you can put this to work today using a combination of service workers, the Speculation Rules API, navigation prerender, tab-level isolation, and careful conflict detection.
- The case for speculative execution in the browser
Agents are latency amplifiers. Consider a typical interaction loop: observe page, plan, act, wait for roundtrips, re-plan. Every network wait, layout thrash, or expensive hydration step multiplies across the chain of reasoning. Humans accept a few seconds for full-page navigations; agents chained over dozens of steps cannot.
On the server we solve this with caches, precomputation, and branch prediction. On the client, browsers already do a modest version: DNS prefetch, link prefetch, prerender. But agentic workflows are richer than naive URL predictions. They involve:
- Multi-branch action trees: click next vs open details vs refine filter vs jump to checkout
- Same-page state transitions triggered by JS controllers with hidden fetches and side effects
- Forms and multi-step wizards where the best next move depends on live DOM and policy logic
Agents know their likely next moves. They can encode these as branches with probabilities and values, budget speculative work in the background, and then commit the winning branch with near-zero perceived latency.
This is practical if we adopt principles that the web platform supports natively:
- Keep speculation safe and idempotent by prioritizing GET navigations and cache-warming
- Use isolated browsing contexts so speculation does not leak storage or side effects
- Confirm against live state and revalidate caches before commit
- Cancel or discard branches with no persistent footprint
- Goals, constraints, and threat model
Design goals:
- Latency reduction: shave 100 to 800 ms on navigations and tens of ms on same-origin resource fetches
- Safety: avoid side effects during speculation; only commit when safe
- Isolation: storage, cookies, JS state confined per branch until activation
- Robustness: handle cross-origin SOP constraints gracefully
- Compliance: respect site policies, avoid abusive request patterns, integrate backoff heuristics
Non-goals:
- We do not attempt to bypass anti-bot systems. This design seeks to behave like an impatient but polite user: anticipating, caching, prerendering via sanctioned browser primitives, and backing off when challenged.
Threat model and constraints:
- Cross-origin DOM is opaque due to SOP; you cannot snapshot or mutate foreign DOM directly
- Many POST endpoints have CSRF protections, cookies, and server-side mutation; speculative POST is generally inappropriate
- Headless detection and anti-automation systems monitor timing, fingerprint stability, and request cadence; we stick to browser-native prerender and prefetch semantics that are treated as hints
- Storage partitioning and site isolation can change availability of caches per branch and per top-level site
- System architecture overview
We will build a pipeline with the following components:
- Planner: Generates a set of plausible next actions with probabilities and estimated value
- Branch Manager: Chooses which branches to speculate given budgets and risks
- Prefetcher and Prerender Coordinator: Uses Speculation Rules API, link rel hints, and service workers to warm caches and, where safe, prerender full pages
- Sandbox Factory: Materializes isolated contexts per branch using browser prerender, tabs, or extension offscreen documents
- State Oracle and Conflict Detector: Tracks what assumptions each speculative branch relies on and checks them against live state at commit time
- Commit and Rollback Coordinator: Activates prerendered contexts or consumes warmed cache instantly; otherwise cancels and evicts speculative artifacts
- Compliance Governor: Enforces polite rate limits, progressive backoff, and per-origin budgets to avoid triggering defenses
A typical loop looks like this:
-
Observe live page and agent intent
-
Produce 2 to 5 likely branches, each with a URL or in-page action and probability
-
For navigation branches, issue speculation rules to prefetch or prerender best candidates
-
For in-page GET data dependencies, prefetch via service worker into Cache Storage
-
When the agent commits to a branch, confirm state: conditional GET revalidation and DOM assertions
-
If consistent, activate prerendered page or consume cache; else rollback speculation and fall back to regular navigation
-
Predictive prefetch and prerender: use the platform, not hacks
The modern browser gives us powerful, standards-based building blocks that behave predictably and safely.
4.1 Speculation Rules API
Chrome exposes a mechanism for declaring candidate URLs for prefetch or prerender based on heuristics. You add a script tag with type 'speculationrules' and JSON-like rules. We will generate this dynamically from our planner.
Example dynamic injection (JS) that avoids double quotes for this article but is valid in principle:
jsfunction installSpeculationRules(candidates) { // candidates: [{ url, action: 'prefetch'|'prerender', score }] const rules = { prerender: candidates .filter(c => c.action === 'prerender') .map(c => ({ source: 'list', urls: [c.url] })), prefetch: candidates .filter(c => c.action === 'prefetch') .map(c => ({ source: 'list', urls: [c.url] })) }; const s = document.createElement('script'); s.type = 'speculationrules'; s.textContent = JSON.stringify(rules); // Replace previous rules to avoid runaway speculation const old = document.querySelector('script[type="speculationrules"]'); if (old) old.remove(); document.head.appendChild(s); }
Prerendered pages run in an isolated context that prevents most side effects and are only activated if you navigate to them. This is ideal for low-risk branching.
References: search for Chromium Speculation Rules API and prerender2 documentation.
4.2 Link rel prefetch and preload
For non-navigation resources you can hint intent via link tags:
html<link rel='prefetch' href='/api/search?q=foo' as='fetch'> <link rel='preload' href='/static/bundle.js' as='script' fetchpriority='high'>
These are safe, best-effort signals. Browsers may throttle or ignore them under memory pressure.
4.3 Service worker cache warming and conditional revalidation
A service worker can isolate and control fetches for your origin, enabling cache warming, background retries, and fast commit via revalidation. Register once per origin:
js// main thread if ('serviceWorker' in navigator) { navigator.serviceWorker.register('/sw.js'); }
Then implement basic caching with ETag-aware revalidation inside sw.js:
jsconst CACHE = 'agent-spec-v1'; self.addEventListener('install', event => { self.skipWaiting(); }); self.addEventListener('activate', event => { event.waitUntil(self.clients.claim()); }); async function cacheFirstWithRevalidate(request) { const cache = await caches.open(CACHE); const cached = await cache.match(request, { ignoreVary: false }); if (cached) { // Try conditional revalidation in the background const headers = new Headers(); const etag = cached.headers.get('ETag'); const lm = cached.headers.get('Last-Modified'); if (etag) headers.set('If-None-Match', etag); if (lm) headers.set('If-Modified-Since', lm); const revalidate = fetch(request, { headers, cache: 'no-store' }) .then(resp => { if (resp.status === 304) return cached; // still fresh cache.put(request, resp.clone()); return resp; }) .catch(() => cached); return revalidate; } const resp = await fetch(request, { cache: 'no-store' }); if (resp.ok) await cache.put(request, resp.clone()); return resp; } self.addEventListener('fetch', event => { const req = event.request; // Only same-origin GET is cached to keep speculation safe if (req.method === 'GET' && new URL(req.url).origin === location.origin) { event.respondWith(cacheFirstWithRevalidate(req)); } }); // Speculative warming API invoked by the page self.addEventListener('message', async event => { const { type, urls } = event.data || {}; if (type === 'speculative-warm' && Array.isArray(urls)) { const cache = await caches.open(CACHE); for (const u of urls) { try { const req = new Request(u, { method: 'GET', cache: 'no-store' }); const resp = await fetch(req); if (resp.ok) await cache.put(req, resp.clone()); } catch {} } } });
From the page, you can ask the service worker to warm a list of GET endpoints relevant to each branch. Because this is same-origin, you avoid CSRF pitfalls and keep speculation idempotent.
4.4 Navigation API activation
When a prerendered page exists for a URL, navigating to it activates instantly. Use the emerging Navigation API when available:
jsasync function commitNavigation(url) { if ('navigation' in window) { // navigation.navigate will activate a matching prerender if one exists await navigation.navigate(url); return; } // Fallback location.assign(url); }
- Branch and rollback planning
We define a branch as a tuple: intent, probability p, expected benefit b (ms saved), cost c (bytes, CPU), and risk r (likelihood of conflict or waste). The Branch Manager selects the subset that maximizes expected utility under budgets.
5.1 Utility model
Simple expected utility for branch i:
U_i = p_i * max(0, L_baseline_i - L_spec_i) - alpha * bytes_i - beta * cpu_i - gamma * risk_i
Where:
- L_baseline_i is expected latency without speculation
- L_spec_i is latency with speculation and instantaneous commit
- alpha, beta, gamma are tunables reflecting resource budgets and caution level per origin
You can refine this with multi-armed bandits that learn p_i and b_i online.
5.2 Practical branch types
- Navigation branches: clicking a search result, opening details, going to next page. Best candidate for prerender or prefetch because navigation is usually GET and isolated by browser.
- Data dependency branches: the agent will likely open a menu or scroll into a component that triggers predictable fetches under your origin. Warm in service worker.
- Form branches: submitting with likely parameters. Speculative POST is usually a no-go; instead, prefetch the confirmation page template and any supporting GET calls. If you control the server, expose a dry-run endpoint for validation.
- In-page JS transitions: only safe if you control the app and can instrument pure computations or dry-run modes. For arbitrary sites, limit to read-only precomputation.
5.3 Branch lifecycles
- Prepare: register speculation rules and warm caches
- Observe: attach mutation observers to watch for state changes that might invalidate assumptions
- Confirm: before commit, revalidate ETag or query stale-while-revalidate results
- Commit: navigate to prerender or consume warmed cache
- Rollback: remove speculation rules, inform service worker to deprioritize or evict entries, abort pending fetches
- Isolation: tabs, prerender sandboxes, and extension offscreen contexts
Isolation is the core safety property. Using the right context ensures speculation cannot leak cookies, write storage, or run privileged code until commit.
- Prerendered pages are run in a separate browsing context. They can execute scripts and load resources but are not visible or interactive, and activation is controlled by the browser.
- Site isolation means each site instance is in its own process, reducing cross-site bleed and side channels.
- For same-origin tinkering, you can use an iframe with src pointing to your own origin and a staged environment. Use the sandbox attribute to restrict capabilities as needed.
- Chrome extensions offer an offscreen document API that lets you create a hidden DOM environment to precompute layout or run app JS safely for same-origin use cases. See Chrome offscreen documents docs.
Do not attempt to hide normal tabs and run reckless JS. Use sanctioned primitives. They exist precisely to make speculative work safe and compatible with resource management.
- State oracle and conflict detection
Speculation assumes some invariants. Before commit, you must confirm that they still hold or gracefully roll back.
7.1 Conditional revalidation
If you prerendered based on a list of products, verify that server state is still consistent. Conditional GET via service worker revalidation ensures cached data is current or fast-updated:
- Use ETag and Last-Modified to avoid refetching entire payloads
- On 304 responses, proceed; on 200 with different ETag, evaluate if the change is acceptable
7.2 DOM assertions
For same-page branches, track the DOM predicates you assumed, such as existence of a target button or a price threshold. Confirm with a quick query before invoking the action.
jsfunction assertPredicates(predicates) { for (const p of predicates) { if (!p()) return false; } return true; }
7.3 Staleness windows and deadline budgets
Give each branch a staleness TTL and a decision deadline. If the agent has not committed by deadline, discard the branch to free memory and reduce background noise.
- Compliance-friendly behavior that avoids triggering defenses
Rather than evading detection, design your speculation to be indistinguishable from a high-quality web experience and to respect site policies:
- Prefer browser-native hints: prerender and prefetch are normal user features; servers are accustomed to them
- Constrain concurrency per origin: e.g., at most 2 spec branches and 4 warmed URLs per branch
- Respect robots and caching headers: if a resource is private, no-store, or disallows prefetching, do not cache or prefetch it
- Use normal user input cadence: avoid bursty speculative floods; sprinkle jitter and randomized delays within a small range
- Back off on challenge: if you see 429 Too Many Requests, Retry-After, or a CAPTCHA interstitial, immediately suspend speculation for that origin and switch to baseline navigation
- Honor CSP and Feature-Policy and do not subvert security boundaries
- Prefer official APIs when sites expose them; if a site provides a search endpoint for suggestions, use that rather than scraping dynamic pages
This posture is more durable and cooperative. You gain much of the latency win without adversarial techniques.
- A concrete pipeline with code
Let us stitch the pieces together for a single-page agent shell that predicts the next click on a product listing page.
9.1 Planner and branch manager
ts// types.d.ts export type Branch = { id: string; kind: 'navigate' | 'data' | 'form'; url?: string; // for navigate or data formSpec?: { endpoint: string; payloadPreview: Record<string, string> }; probability: number; // 0..1 expectedMsSaved: number; bytesCost?: number; risk?: number; // 0..1 predicates?: Array<() => boolean>; deadlineMs: number; };
js// branch-manager.js class BranchManager { constructor({ maxConcurrent = 2, byteBudget = 500000 }) { this.maxConcurrent = maxConcurrent; this.byteBudget = byteBudget; this.active = new Map(); } select(branches) { const scored = branches .map(b => { const alpha = 1e-6; // per-byte penalty const beta = 0.2; // risk penalty const util = b.probability * b.expectedMsSaved - alpha * (b.bytesCost || 0) - beta * (b.risk || 0); return { b, util }; }) .sort((x, y) => y.util - x.util); const chosen = []; let bytes = 0; for (const item of scored) { if (chosen.length >= this.maxConcurrent) break; const nextBytes = bytes + (item.b.bytesCost || 0); if (nextBytes > this.byteBudget) continue; chosen.push(item.b); bytes = nextBytes; } return chosen; } trackStart(branch) { this.active.set(branch.id, { branch, startedAt: performance.now() }); } trackStop(id) { this.active.delete(id); } }
9.2 Speculation rules and SW warming
js// prefetcher.js export async function specWarm(branches) { const navs = branches.filter(b => b.kind === 'navigate' && b.url); const datas = branches.filter(b => b.kind === 'data' && b.url); // Install or update speculation rules installSpeculationRules( navs.map(b => ({ url: b.url, action: 'prerender', score: b.probability })) ); // Ask service worker to warm data URLs (same-origin) if (navigator.serviceWorker?.controller && datas.length) { const urls = datas.map(b => b.url); navigator.serviceWorker.controller.postMessage({ type: 'speculative-warm', urls }); } }
9.3 Commit or rollback coordinator
js// commit.js async function confirmAndCommit(branch) { // 1) Check predicates if (branch.predicates && !assertPredicates(branch.predicates)) { return { committed: false, reason: 'predicates-failed' }; } // 2) For navigate: activate prerender or normal nav if (branch.kind === 'navigate' && branch.url) { await commitNavigation(branch.url); return { committed: true }; } // 3) For data: fetch from cache or network quickly if (branch.kind === 'data' && branch.url) { const resp = await fetch(branch.url, { cache: 'default' }); const json = await resp.json().catch(() => null); return { committed: true, data: json }; } // 4) For form: only if you have a dry-run server endpoint if (branch.kind === 'form' && branch.formSpec) { // Example: preview submission to get confirmation page shell const previewUrl = new URL(branch.formSpec.endpoint); previewUrl.searchParams.set('preview', '1'); for (const [k, v] of Object.entries(branch.formSpec.payloadPreview)) { previewUrl.searchParams.set(k, v); } const resp = await fetch(previewUrl.toString(), { method: 'GET' }); if (!resp.ok) return { committed: false, reason: 'preview-failed' }; const html = await resp.text(); // Render confirmation shell locally or hand off to app return { committed: true, html }; } return { committed: false, reason: 'unknown-branch' }; }
9.4 Timeouts and cleanups
jsfunction scheduleRollback(branch, ms) { const id = setTimeout(() => { // Remove speculation rules if branch was the only candidate for that URL // In practice, you maintain a refcount per URL. // Here, we just no-op and rely on browser GC and SW cache TTLs. }, ms); return () => clearTimeout(id); }
9.5 Putting it all together
jsimport { specWarm } from './prefetcher.js'; import { BranchManager } from './branch-manager.js'; const bm = new BranchManager({ maxConcurrent: 2, byteBudget: 300000 }); function planNextBranches(ctx) { // ctx includes page embeddings, DOM cues, agent intent // Example heuristic planner on a product list page const links = Array.from(document.querySelectorAll('a.product-tile')); const top = links.slice(0, 3).map((a, i) => ({ id: 'nav-' + i, kind: 'navigate', url: a.href, probability: 0.2 + 0.2 * (3 - i), expectedMsSaved: 400, bytesCost: 120000, risk: 0.1, predicates: [() => !!document.body] })); const nextPage = document.querySelector('a.next'); const branches = [ ...top, nextPage ? { id: 'nav-next', kind: 'navigate', url: nextPage.href, probability: 0.3, expectedMsSaved: 350, bytesCost: 100000, risk: 0.1 } : null ].filter(Boolean); return branches; } async function tick() { const candidates = planNextBranches({}); const chosen = bm.select(candidates); await specWarm(chosen); // Example: commit first branch when an agent decides // In a real agent, decision is based on model output const decision = chosen[0]; const cleanup = scheduleRollback(decision, decision.deadlineMs || 3000); const res = await confirmAndCommit(decision); cleanup(); if (!res.committed) { console.log('Rolled back:', res.reason); } } // Run the loop when idle to avoid jank (function loop() { if ('requestIdleCallback' in window) { requestIdleCallback(tick, { timeout: 1000 }); } else { setTimeout(tick, 250); } })();
- DOM-level speculation for same-page actions
Navigation is the low-hanging fruit. But what about actions within the same page, like expanding an accordion that triggers async loads or running expensive client-side sort logic?
On arbitrary third-party sites, do not attempt to simulate event handlers inside a cloned DOM. Event listeners are closures you cannot copy reliably, and cross-origin restrictions bite. Safer strategies:
- Pre-warm data: if you can infer that opening a pane will hit a JSON endpoint on the same origin, warm it through the service worker.
- Calculate pure view-models: for apps you control, split heavy computations into pure functions and let workers compute them speculatively. For example, compute paginated results and memoize them.
- Use requestIdleCallback to perform speculative work only when the main thread is idle.
Example of speculative pure computation in a web worker:
js// worker.js self.onmessage = e => { const { type, payload } = e.data; if (type === 'compute-sort') { const { items, key } = payload; const sorted = items.slice().sort((a, b) => (a[key] > b[key] ? 1 : -1)); postMessage({ type: 'sorted', sorted }); } };
js// main thread const worker = new Worker('/worker.js'); worker.onmessage = e => { if (e.data.type === 'sorted') { // Cache the result and apply instantly when user opens the sort panel window.sortedCache = e.data.sorted; } }; function maybeSpeculateSort(items, key) { if ('requestIdleCallback' in window) { requestIdleCallback(() => worker.postMessage({ type: 'compute-sort', payload: { items, key } })); } }
This sidesteps DOM manipulation during speculation and focuses on CPU-heavy transforms that are pure and easily discarded if unused.
- Measuring impact and tuning
If it does not get measured, it does not get faster. Use the Performance API to quantify the win.
11.1 Metrics to track
- Navigation time to first contentful paint and time to first interaction with and without prerender
- Data fetch latency from in-memory cache vs unconditional network
- Branch waste: bytes and CPU spent on branches not committed
- Conflict rate: percentage of branches rolled back due to invalidation
- Trigger rate: occurrences of 429, Retry-After, or anti-automation challenges during speculation
11.2 Instrumentation example
jsconst po = new PerformanceObserver(list => { for (const entry of list.getEntries()) { if (entry.entryType === 'navigation') { console.log('Nav timing', entry.name, entry.duration); } } }); po.observe({ type: 'navigation', buffered: true });
Use server logs to verify that speculative GETs are within acceptable thresholds and not causing undue load.
11.3 Tuning tips
- Bias toward prerender for the top 1 or 2 branches when network is fast and memory is ample
- Bias toward service worker warming when CPU is busy or memory is tight
- Set per-origin budgets and cool-off windows if speculative waste exceeds a threshold
- Failure modes and fallbacks
- Prerender blocked: Some sites or browsers disallow prerender. Inspect console and reduce to prefetch only
- Cache poisoning concerns: Only cache same-origin GETs with proper validation and avoid caching personalized or private responses
- ETag mismatches: On frequent invalidations, consider shorter warm windows or lower priority speculation
- Memory pressure: The browser may evict prefetched resources; always be prepared to fetch normally
- Navigation mismatch: If the final URL differs from the prerender candidate due to redirects, activation may not happen; fall back to normal navigation and learn from the miss
- Ethics and boundaries
Responsible speculation adheres to the spirit of the platform:
- Use official, documented features designed for this purpose: Speculation Rules, prerender, prefetch, SW caching
- Do not script around anti-automation walls; if a site serves a challenge, respect it and slow down or stop speculative actions for that origin
- Provide a user-facing control to disable or throttle speculation, and log speculative requests transparently for auditing
This keeps your agent aligned with site operators and end-user expectations.
- Open research questions and enhancements
- Better planners: Learn branch probabilities from real agent traces via bandits or offline RL, including context from DOM embeddings and URL semantics
- Cost-aware caching: Integrate server-provided cache keys and surrogate-control-like signals to optimize warm sets
- Cross-origin hints: Explore Privacy-preserving prefetch proxies or hints cooperatively offered by sites to guide speculation without leaking user intent
- Transactional UI: For apps you control, expose dry-run modes that return diffs and server-side validation so client speculation can be stronger without any side effects
- Integration with Navigation Transitions and View Transitions to smooth activation across prerender commits
- A concise checklist for productionizing
- Implement a service worker with cache warming and conditional revalidation for same-origin GETs
- Add a planner that emits 2 to 5 candidate branches with probabilities and expected savings
- Install Speculation Rules dynamically for top navigation branches
- Track budgets per origin and total: max concurrent branches, max warmed bytes, cooldown windows
- Confirm before commit: predicates plus conditional GET revalidation
- Activate via Navigation API or location replacement
- Log metrics and implement automatic tuning of branch selection
- Expose a user control to disable or limit speculation and to view logs
- Conclusion
Speculative execution for browser agents is both feasible and valuable today. By leaning on platform features that were built for safe anticipation — prefetch, prerender, service workers, and strict isolation — you can realize most of the latency benefits of agentic foresight without crossing ethical or technical red lines.
The branch-and-rollback pattern, executed at tab-level isolation, lets your agent be ready for the next click before it decides to click. Predictive prefetch warms the path; prerender makes navigation nearly instant; service workers ensure data is already there; and confirm-before-commit avoids surprises. Done well, your agent feels snappy and confident, not reckless.
As models get better at predicting next actions, the payoff compoundly increases. The browser, long seen as a constraint, becomes a speculation-friendly runtime. It is time to treat it as such and bring the best of systems thinking to the client side.