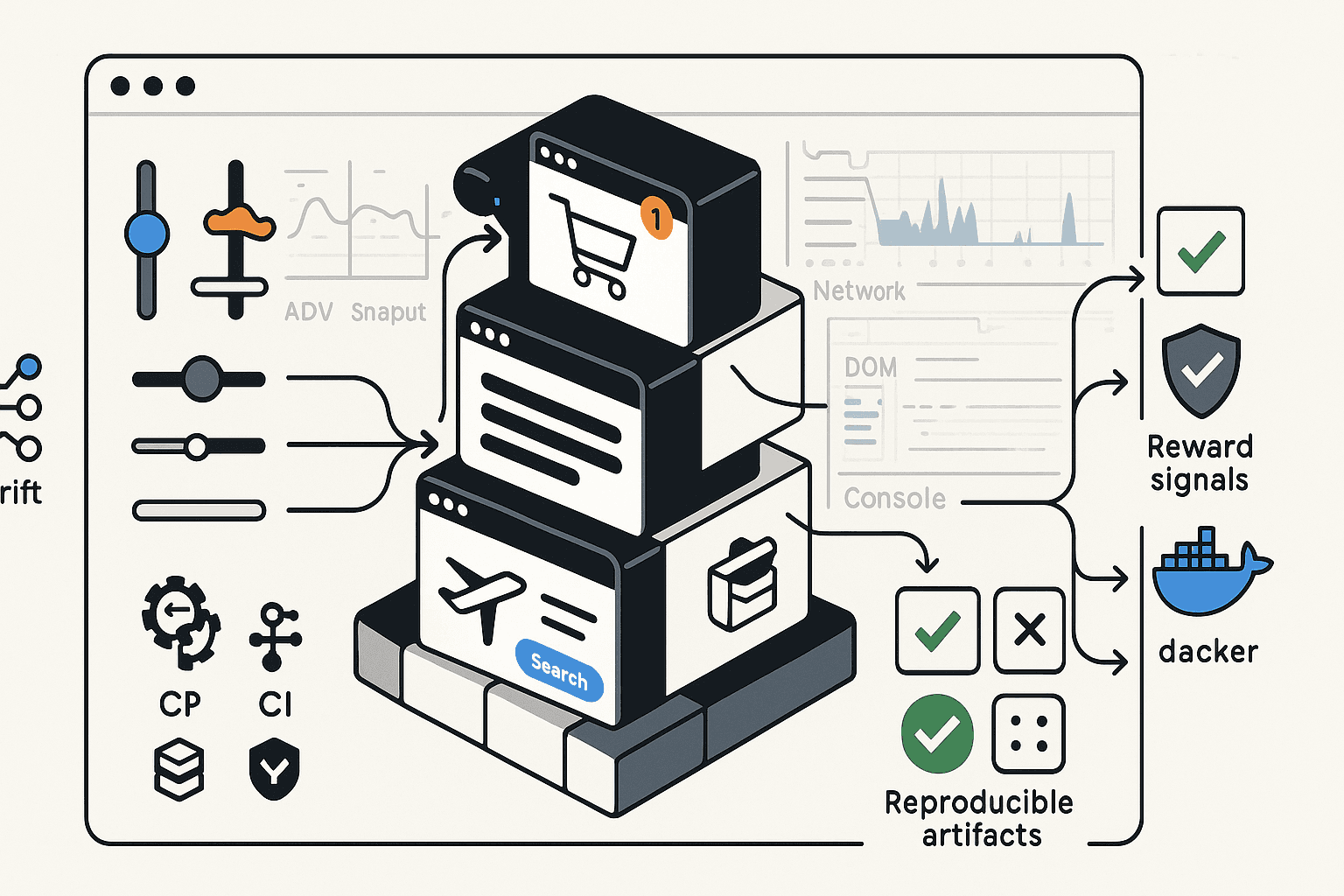
TL;DR
- Build a controllable mini‑web to train and evaluate LLM browser agents without the fragility of the open internet.
- Programmatically synthesize task‑rich apps (cart, checkout, flights) and flows from a simple DSL, guaranteeing ground truth states and oracle trajectories.
- Inject realistic UI and network drift to test robustness and encourage generalization.
- Weak‑label agent data with Chrome DevTools Protocol (CDP) traces for scalable supervision.
- Validate outcomes with deterministic reward checkers that verify DOM, API, and database state.
- Export reproducible CI/bench artifacts (seeds, manifests, containers) to compare agents fairly and track progress.
Introduction
Most web agent papers converge on the same pain points: brittle benchmarks, noisy or unavailable ground truth, and silent regressions when real websites change. MiniWoB++ was a good start, but its toy UIs fail to reflect modern single‑page apps; WebShop, Mind2Web, and WebArena improved realism, but still suffer from drift and limited controllability. If we want browser agents to be product‑grade—reliable on ecommerce, SaaS dashboards, or travel sites—we need a curriculum that is realistic, reproducible, and tunable.
The pragmatic answer: build a synthetic, programmatically generated web—"mini‑web"—that looks and behaves like the real thing, except you own every pixel, endpoint, and log. With a mini‑web, you can: (1) make tasks hard but solvable, (2) derive perfect weak labels from CDP traces and server state, (3) inject controlled drift into the DOM, styling, copy, and network, and (4) ship benchmark artifacts that anyone can run identically in CI.
Below is a blueprint for an opinionated, production‑minded synthetic web curriculum. It is not just a dataset spec; it is an engineering system: a code generator for apps and flows, a drift engine, validators for self‑play, and an export pipeline for benchmarks. Think domain randomization from robotics, re‑imagined for the web.
Why synthetic curricula for browser agents
- Controllability beats scraping: When you control UI, server, and network, you can guarantee consistent outcomes and expose edge cases on demand.
- Scalable supervision: CDP exposes interactions, network payloads, DOM snapshots, and console logs. That’s a treasure trove for weak labels and reward shaping.
- Robustness by design: Drift generators induce realistic variability (layout, copy, colors, delays, auth states) so agents learn invariant policies, not pixel‑perfect scripts.
- Measurability: Deterministic validators turn tasks into unit tests. You get binary success, partial credit, and path diagnostics—great for ML and great for CI.
- Reproducibility: Seeds, manifests, containers, and pinned dependencies let others reproduce results without arguing about traffic, time zones, or cookie banners.
System overview
- Programmatic app builder: Generate apps with product catalogs, carts, checkouts, search/forms, bookings, dashboards. Expose multiple flows per domain.
- Flow DSL: Specify tasks and oracles as state machines with parameter distributions and constraints (e.g., “apply coupon then remove item then checkout”).
- Drift generator: Inject UI drift (layout, CSS, ARIA roles, i18n), data drift (inventory, prices), and network drift (latency, retries, 429/503). All versioned.
- Execution harness: Headless browser with CDP recording, stateful backend with snapshot/rollback, and service worker controls.
- Labelers and validators: Turn traces into weak labels; create reward functions from server state deltas and validator predicates.
- Export stack: Produce benchmark artifacts—HTML/JS bundles, DB seeds, drift profiles, manifests, Dockerfiles, and an evaluator.
Design goals
- Realistic but local: Modern SPA patterns (React/Vue/Svelte or vanilla + HTMX), REST/GraphQL APIs, cookies/auth flows, pagination, search, modals.
- Deterministic when seeded: Identical catalogs, coupons, and flight schedules across machines. Controlled non‑determinism in drift profiles.
- Low friction: Run with Playwright or Puppeteer, no cloud dependencies required. Single docker-compose up should bring the world online.
- Ground‑truth aware: Every action changes a known state; server exposes a validation RPC; DB snapshots allow reversible rollouts.
Programmatic app generation
We need a way to express “apps” and “flows” succinctly, generate code, and get oracles for free. A small DSL is sufficient.
Example domain spec (YAML):
yamlversion: 1 seed: 1337 domains: - id: shop entities: product: schema: id: uuid title: string price: float[2,200] tags: enum[electronics,home,travel,books] coupon: schema: code: string[A-Z0-9]{6} discount_pct: float[5,40] applies_to: tags pages: - id: catalog components: [search, filters, grid(product)] - id: product_detail components: [gallery, description, add_to_cart] - id: cart components: [line_items, apply_coupon, subtotal, checkout_btn] - id: checkout components: [address_form, card_form, place_order] flows: - id: apply_coupon_and_checkout params: tag: sample(tags) steps: - goto: catalog - search: { q: title_contains(tag) } - add_to_cart: 2 - goto: cart - apply_coupon: { for_tag: tag } - assert: { discount_applied: true } - goto: checkout - fill: { address_form: random_valid } - fill: { card_form: valid_visa } - click: place_order - assert: { order_status: success }
This DSL compiles into:
- Frontend pages (React components) and routes.
- REST endpoints (Express/FastAPI) to query products, apply coupons, create orders.
- Test oracles: deterministically generated catalogs/coupons and golden flows performing steps.
- Stateful validators: e.g., discount_applied checks DB state rather than text alone.
Minimal code generator sketch (Node.js):
js// tools/generate-miniweb.js import fs from 'node:fs'; import { faker } from '@faker-js/faker'; import Mustache from 'mustache'; import seedrandom from 'seedrandom'; export function buildDomain(spec) { const rng = seedrandom(spec.seed); faker.seed(spec.seed); // 1) Materialize entities const products = Array.from({ length: 120 }).map((_, i) => ({ id: faker.string.uuid(), title: faker.commerce.productName(), price: Number(faker.commerce.price({ min: 2, max: 200 })), tags: faker.helpers.arrayElements(['electronics','home','travel','books'], Math.max(1, Math.floor(rng() * 2))) })); const coupons = Array.from({ length: 12 }).map(() => ({ code: faker.string.alphanumeric({ length: 6, casing: 'upper' }), discount_pct: Math.round((5 + rng() * 35) * 10) / 10, applies_to: faker.helpers.arrayElement(['electronics','home','travel','books']) })); // 2) Emit backend fixtures fs.writeFileSync('server/fixtures.json', JSON.stringify({ products, coupons }, null, 2)); // 3) Render frontend pages via templates const pages = spec.domains[0].pages; pages.forEach(p => { const tpl = fs.readFileSync(`templates/${p.id}.tsx.mustache`, 'utf8'); const code = Mustache.render(tpl, {}); fs.writeFileSync(`app/src/pages/${p.id}.tsx`, code); }); // 4) Build flow oracles as Playwright tests const flow = spec.domains[0].flows.find(f => f.id === 'apply_coupon_and_checkout'); const testTpl = fs.readFileSync('templates/flow.test.ts.mustache', 'utf8'); const testCode = Mustache.render(testTpl, { flow }); fs.writeFileSync(`tests/${flow.id}.spec.ts`, testCode); }
Stylistically, you can generate apps with any frontend stack. The key is consistency: component libraries, ARIA roles, and data-test attributes must be systematic so drift can be applied and validators can find anchors.
Example React component stub with test anchors:
tsx// app/src/components/Cart.tsx export function Cart({ items, onApplyCoupon, onCheckout }) { return ( <section role="region" aria-label="Cart" data-test="cart"> {items.map((it, idx) => ( <div className="line" key={it.id} data-test={`line-${idx}`}> <span data-test="title">{it.title}</span> <span data-test="price">${it.price.toFixed(2)}</span> </div> ))} <form onSubmit={onApplyCoupon} data-test="coupon-form"> <label htmlFor="coupon">Coupon</label> <input id="coupon" name="coupon" aria-label="Coupon" /> <button type="submit" data-test="apply-coupon">Apply</button> </form> <button onClick={onCheckout} data-test="checkout">Checkout</button> </section> ); }
Generating multiple domains
Don’t stop at carts. Include:
- Flights: Search by origin/destination/dates, sort by price/duration, multi‑leg itineraries, hold vs. purchase.
- SaaS dashboards: CRUD tables with pagination, filters, modals, role‑based access.
- Auth flows: Sign up, email verification, 2FA, password reset.
- Support portals: Submit tickets, attach files, read KB articles with infinite scroll.
Each domain should define flows with success and failure oracles. E.g., flights must detect impossible routes; auth must reject weak passwords; support must rate limit attachments.
Injecting UI and network drift
Agents trained against a single DOM will overfit. Drift encourages abstraction: learn semantics, not pixel positions.
Drift taxonomy
- Layout drift: Reorder DOM sections, switch between grid/list, insert ads or banners, change spacing.
- Style drift: Alter theme (light/dark), colors, contrast, fonts; hide button text into icons, adjust border radii.
- Copy drift: Vary microcopy (“Checkout” vs “Place order”), switch locales/time zones and currency formats.
- Semantics drift: Change ARIA roles, add nested containers, wrap buttons in labels.
- Interaction drift: Debounce search, require double‑click, introduce confirmation modals.
- Network drift: Add jitter, throttle bandwidth, 429/503s with Retry‑After, stale ETags, server‑side sorting differences.
- Data drift: Skew price distributions, remove coupons, change inventory.
Represent drifts as profiles, versioned and composable.
Example drift profile (YAML):
yamlprofile: "v1-hard-generalization" ui: layout_shuffle: 0.4 theme: [light, dark] button_text_variants: checkout: ["Checkout", "Place order", "Proceed"] aria_role_noise: 0.1 locale: [en-US, fr-FR] network: latency_ms: { min: 50, max: 800, p95: 500 } error_rates: 429: 0.03 503: 0.02 retry_after_s: [1, 3] data: coupon_dropout: 0.2 price_jitter_pct: 0.1
CSS/layout drift injector (build‑time):
js// tools/drift/ui-drift.js import postcss from 'postcss'; import * as csstree from 'css-tree'; export function applyStyleDrift(css, profile, rng) { const tree = csstree.parse(css); csstree.walk(tree, { visit: 'Declaration', enter(node) { if (node.property === 'border-radius' && rng() < 0.5) { node.value = csstree.parse(`${Math.floor(rng()*16)}px`, { context: 'value' }); } if (node.property === 'font-size' && rng() < 0.2) { const mult = 0.9 + rng() * 0.3; // naive: leave as is if calc present } } }); return csstree.generate(tree); }
Copy drift via placeholders:
ts// i18n.ts const variants = { checkout: ["Checkout", "Place order", "Proceed"], }; export function t(key: keyof typeof variants, rng) { const arr = variants[key]; return arr[Math.floor(rng() * arr.length)]; }
Network drift via Service Worker:
js// public/sw.js self.addEventListener('fetch', (event) => { const url = new URL(event.request.url); if (url.pathname.startsWith('/api/')) { event.respondWith((async () => { const latency = 50 + Math.random() * 750; // replace with seeded RNG await new Promise(r => setTimeout(r, latency)); // Inject errors stochasticly if (Math.random() < 0.03) { return new Response(JSON.stringify({ error: 'Too Many Requests' }), { status: 429, headers: { 'Retry-After': '2' } }); } return fetch(event.request); })()); } });
You can also inject drift at runtime via a feature flag system that toggles classes/roles and DOM order. Prefer deterministic RNG seeded from the profile hash to make runs reproducible.
Weak labeling with CDP traces
Chrome DevTools Protocol exposes exact, machine‑readable evidence of what happened:
- Network.requestWillBeSent/Network.responseReceived: URLs, payloads, headers, status codes.
- Page.frameNavigated, DOM.attributeModified: structural changes.
- Input.dispatchMouseEvent/dispatchKeyEvent: precise actions.
- Performance timeline: CPU, layout thrash.
We can derive weak labels for agent training from these traces without human annotation:
- Action labels: Map click coordinates to target element (via DOM snapshot), extract role/name/text for semantic supervision.
- Intent labels: Infer “applied coupon” if a PUT /api/cart with coupon field occurs and DB state reflects discount.
- Outcome labels: Mark success if POST /api/order returns 201 and order_id appears on confirmation page.
Playwright example: capture CDP and derive labels
python# tools/tracing/labeler.py import asyncio from playwright.async_api import async_playwright from dataclasses import dataclass, asdict @dataclass class ActionLabel: kind: str # click, type, select selector: str role: str | None name: str | None value: str | None timestamp: float async def run_and_label(seed: int, scenario_id: str): async with async_playwright() as p: browser = await p.chromium.launch() context = await browser.new_context() page = await context.new_page() cdp = await context.new_cdp_session(page) await cdp.send('Network.enable') await cdp.send('DOM.enable') labels: list[ActionLabel] = [] network_events = [] cdp.on('Network.requestWillBeSent', lambda e: network_events.append(e)) async def label_click(selector): el = await page.locator(selector).first role = await el.get_attribute('role') name = await el.get_attribute('aria-label') await el.click() labels.append(ActionLabel('click', selector, role, name, None, page.timeouts['navigation'] if 'navigation' in page.timeouts else 0)) await page.goto(f"http://localhost:3000/?seed={seed}&scenario={scenario_id}") await label_click('[data-test=add-to-cart]:nth-of-type(1)') await page.fill('[data-test=coupon-input]', 'SAVE10') await label_click('[data-test=apply-coupon]') await label_click('[data-test=checkout]') # Post-process network events into intent/outcome labels intents = [] for ev in network_events: url = ev['request']['url'] if url.endswith('/api/cart') and ev['request']['method'] in ('POST','PUT'): intents.append({'intent': 'update_cart', 'payload': ev['request'].get('postData', '')}) if url.endswith('/api/order') and ev['request']['method'] == 'POST': intents.append({'intent': 'place_order'}) await browser.close() return { 'actions': [asdict(l) for l in labels], 'intents': intents, 'network': network_events, } if __name__ == '__main__': asyncio.run(run_and_label(seed=1337, scenario_id='apply_coupon_and_checkout'))
A richer labeler can:
- Snapshot DOM with DOM.getDocument / DOM.describeNode and compute stable selectors by role/name/text.
- Extract element bounding boxes with DOM.getBoxModel to train pointer models.
- Canonicalize text fields (e.g., masked credit cards) and normalize currency/time.
Designing reward validators and self‑play rewards
Training purely from next‑token loss on transcripts leaves agents good at chat, not completion. We need rewards that capture goal completion and penalize degenerate shortcuts.
Principles for reward validators:
- Ground truth over surface heuristics: Check server state and API semantics first, then DOM text.
- Determinism: Avoid flaky signals; if the network drifts, validators should account for retries and idempotency.
- Decomposability: Offer subgoal rewards (e.g., “coupon applied”, “address valid”, “payment accepted”) to stabilize learning.
- Adversarial guards: Penalize hidden devtools usage, JS execution outside allowed APIs, or reading validation endpoints.
Validator RPC (backend):
ts// server/src/validator.ts import { db } from './db'; import express from 'express'; const router = express.Router(); router.post('/validate', async (req, res) => { const { run_id, expectations } = req.body; const { order_id, coupon_code } = expectations || {}; const out: Record<string, boolean> = {}; if (coupon_code) { const cart = await db.cart.findUnique({ where: { run_id } }); out.coupon_applied = Boolean(cart?.applied_coupon === coupon_code && cart?.discount_total > 0); } if (order_id) { const order = await db.order.findUnique({ where: { id: order_id, run_id } }); out.order_success = Boolean(order && order.status === 'CONFIRMED'); } res.json({ ok: true, results: out }); }); export default router;
Self‑play loop (conceptual):
- Agent receives instruction and environment URL/seed.
- Interacts via browser automation (restricted toolset: click, type, wait, etc.).
- After each step or episode, the harness queries validators with known expectations (from DSL) and computes rewards.
- Train with policy gradient or Q‑learning on top of a language model that outputs actions (action grammar constrained by schema).
Sketch: environment step for RL
python# rl/env.py from dataclasses import dataclass @dataclass class Obs: screenshot_path: str | None accessibility_tree: dict url: str text_snippet: str class MiniWebEnv: def __init__(self, seed, scenario, drift_profile, validator_url): ... async def reset(self): self.state = await self._launch_browser() # return initial observation return await self._observe() async def step(self, action): # action example: {"kind":"click","selector":"role=button[name=/place/i]"} reward = 0.0 done = False info = {} await self._apply_action(action) obs = await self._observe() partial = await self._validator_check() reward += 0.2 if partial.get('coupon_applied') else 0 if partial.get('order_success'): reward += 1.0 done = True return obs, reward, done, info
To keep agents honest, deny them introspective access to validator endpoints; the harness can hold the token, and validators should check origin. For self‑play discovery, you can run two instances of the agent: a proposer that generates candidate plans using the DSL’s goal schema and a verifier that attempts to refute them by inducing drifts or edge cases.
Exporting reproducible CI/bench artifacts
A benchmark nobody can reproduce is not a benchmark; it’s an anecdote. Ship artifacts like you would a production service.
What to export
- Docker images: app server, DB, drift service, evaluator harness.
- Seeded data: catalogs, coupons, flight schedules, user accounts, auth secrets (scoped to the container).
- Drift profiles: YAML files with profile IDs, seeds, and change logs.
- Task manifests: JSON with tasks, parameters, expected validators, difficulty tags.
- Evaluator CLI: run tasks, record traces, compute metrics; write JSONL results.
- Reference agents: minimal rule‑based baseline and a prompt‑only LLM baseline for context.
Manifest example:
json{ "benchmark": "miniweb-v0.3", "seed": 1337, "profiles": ["v1-easy", "v1-hard-generalization"], "tasks": [ {"id": "shop.apply_coupon_and_checkout", "repeats": 50, "time_limit_s": 120}, {"id": "flights.roundtrip_filter_sort_buy", "repeats": 50, "time_limit_s": 180} ], "metrics": ["success_rate", "normalized_path_length", "retry_robustness", "accessibility_compliance"] }
Evaluator CLI skeleton:
bashminiweb bench run \ --manifest bench/miniweb-v0.3.json \ --agent http://localhost:7777/agent \ --output results/run-2024-12-01.jsonl
CI considerations
- Run headless (Xvfb or built‑in headless Chromium) with pinned browser version.
- Persist video/screenshots selectively to keep storage sane.
- Enforce timeouts and memory limits per run; collect CPU/mem stats for fairness.
- Publish SBOMs and lockfiles to avoid dependency drift.
Measuring progress
Raw success rate is necessary but not sufficient.
- Success rate: Binary completion rate of tasks under each drift profile.
- Normalized path length: Steps taken vs. oracle path; rewards agents that avoid dithering.
- Robustness: Degradation under increased latency, error injection, or copy drift.
- Recovery: Fraction of runs that recover after a 429/503 without abandoning the task.
- Accessibility alignment: Fraction of actions targeting elements by ARIA role/name; discourages brittle CSS selectors.
- Side‑effect verification: Cross‑check DB deltas; catch “visual only” hacks.
Baselines and related work
- MiniWoB++ showed the value of small, programmatic tasks but lacks modern SPA traits and network complexity.
- WebShop and Mind2Web introduced realistic shopping and task annotations; Mind2Web leverages human annotations but inherits website drift.
- WebArena built a contained environment with multiple sites; our proposal extends with richer drift controls, server‑side validation, and exportable CI artifacts.
- AgentBench/BrowserGym‑style harnesses demonstrate evaluation harness patterns; integrate their schemas where possible for interoperability.
Compared to these, a synthetic curriculum that programmatically generates both UI and server logic yields: (1) perfect ground truth, (2) drift controls, (3) exact validators, and (4) reproducible packaging—tightening the loop between training and deployment.
Putting it together: a sample pipeline
- Generate apps and tasks
- Write a DSL spec for shop and flights.
- Build apps with seed 1337; output frontend bundle, backend server, DB fixtures.
- Produce task manifests and oracle scripts.
- Create drift profiles
- v1‑easy: minimal UI drift, no network errors.
- v1‑hard‑generalization: 40% layout shuffle, dark/light theme mix, copy variants, 3–5% 429/503.
- v1‑i18n: fr‑FR locale, EUR currency, Monday‑first calendars.
- Collect pretraining data (weak labels)
- Run oracle flows under all drifts with Playwright; save CDP traces.
- Generate action labels (role, name, selector), intents (API semantics), and outcomes.
- Save as JSONL shards for supervised finetuning.
- Supervised finetuning
- Train an action‑conditional LLM to map (instruction, recent DOM summary, prior actions) → next action.
- Constrain decoding via an action grammar (click/type/select/wait, with structured arguments).
Action schema (JSON Schema):
json{ "$id": "https://miniweb/actions.schema.json", "oneOf": [ {"type": "object", "properties": {"kind": {"const": "click"}, "selector": {"type": "string"}}}, {"type": "object", "properties": {"kind": {"const": "type"}, "selector": {"type": "string"}, "text": {"type": "string"}}}, {"type": "object", "properties": {"kind": {"const": "wait"}, "until": {"type": "string"}}} ] }
- RL fine‑tuning with self‑play
- Use validators for rewards (subgoals + terminal success).
- Perturb drift across episodes; anneal difficulty based on performance.
- Penalize unsafe shortcuts: CSS selectors that lack semantic anchors, reliance on brittle text when roles exist.
- Evaluate and export
- Run the evaluator across all profiles; gather metrics.
- Package results and artifacts; publish Docker images and manifests.
Example: rule‑based baseline
python# agents/baseline.py from playwright.sync_api import sync_playwright class RuleAgent: def run(self, url, instruction): with sync_playwright() as p: b = p.chromium.launch() ctx = b.new_context() page = ctx.new_page() page.goto(url) # naive: click buttons by role/name page.get_by_role('button', name=r/(add to cart|add)/i).first.click() page.get_by_label('Coupon').fill('SAVE10') page.get_by_role('button', name=r/(apply|use)/i).click() page.get_by_role('button', name=r/(checkout|place order|proceed)/i).click() # return a trace file path b.close()
Engineering concerns and pitfalls
- Overfitting to synthetic quirks: Avoid uniform component layouts; randomize semantics within guardrails (e.g., roles, not just classes).
- Reward hacking: Agents can sometimes trigger validators without truly completing tasks (e.g., directly calling API endpoints). Enforce origin checks, CSRF tokens, and network policy in the harness.
- Latency determinism: Use seeded RNG for drift; when measuring, fix seeds or report confidence intervals across seeds.
- Accessibility: Generate ARIA‑correct components; run axe-core in CI. Train agents to prefer semantic targets.
- Time zones and locales: Normalize server timestamps; explicitly surface locale in observations so agents don’t guess date formats.
- Security: Sandbox the browser (no file system access), block eval/devtools Protocol commands beyond what the harness requires.
Opinionated best practices
- Treat validators like unit tests: For each flow, write property‑based tests (Hypothesis/fast‑check) that assert invariants regardless of drift.
- Prefer role/name selectors: Force baselines to use getByRole/getByLabel/getByText before CSS; score them accordingly.
- Keep oracles honest: Use the same drift profiles for oracle runs; ensure oracles do not depend on fixed positions.
- Ship seeds and SBOMs: Every “release” of the benchmark should have a seed manifest, vulnerability report, and reproducibility checklist.
- Expose a stable API: Provide a thin observation/action API so different agents (prompt‑only, toolformer, RL) can plug in without rewriting harness code.
Open research questions
- Generalization bounds: How much drift is needed to robustify real‑world transfer? Analogies exist in domain randomization for robotics; we need similar studies for DOM/UI.
- Representation learning: What’s the right observation space—full DOM, accessibility tree, distilled semantic graph, or multimodal screenshot + text overlays?
- Credit assignment: Better reward shaping from CDP traces (e.g., matching causal chains between actions and API effects) could reduce dithering.
- Human‑in‑the‑loop: Can we solicit minimal human corrections to bootstrap oracles for new domains or to detect dataset bugs?
- Safety: How to constrain agents against security‑sensitive actions (e.g., exfiltration via form fields) while keeping the benchmark open?
Conclusion
A synthetic mini‑web is not a toy; it’s a scalpel. With programmatic app generation, drift engines, CDP‑backed weak labels, and deterministic validators, we can build browser agents that actually generalize—and measure them credibly. Exporting reproducible artifacts turns benchmarks from moving targets into shared infrastructure that teams can iterate on in CI, on laptops, and in papers.
The roadmap is clear:
- Start small (shop + flights) with solid validators.
- Turn on drift and watch your agent crumble; then teach it invariances.
- Wire up self‑play and profile rewards until training is stable.
- Package everything so others can replicate results exactly.
If you’re serious about shipping web agents, own your web. Build a mini‑web, inject drift with intent, supervise with traces, and validate outcomes like you would production code. The result is an agent that’s not just clever in a demo—but reliable in the wild.