TL;DR
Train browser agents without scraping live sites by building a synthetic web task gym: generate parametric websites (forms, carts, tables, auth, i18n), perturb them with CMP banners, popups, and A/B drift, and auto-label outcomes via DOM and network invariants. This yields reproducible, high-coverage datasets for SFT and stable, low-noise rewards for RL.
We will design a reproducible pipeline, show reference architecture and code snippets, define reward invariants, and outline an evaluation and training loop that scales from CPU-only CI to GPU-backed RL runs.
Why a synthetic web task gym now
Browser agents are making rapid progress, but three realities impede reliable training on the open web:
- Websites change constantly: A/B tests, cookie banners, feature flags, rate limits, and third-party integrations create drift and break reproducibility.
- Legal and ethical constraints: Scraping, logging PII, and automating against live properties raise terms-of-service and privacy risks.
- Sparse and noisy rewards: It is hard to define success reliably from screenshots or brittle CSS selectors in arbitrary pages.
A synthetic gym sidesteps these issues:
- Full control: We own the HTML/JS/CSS and the network stack, so we can record ground-truth outcomes and instrument everything.
- Programmatic diversity: Procedurally generate sites spanning common interaction patterns—forms, carts, tables, auth, i18n—at scale.
- Deterministic randomness: Seeded generation enables exact reproduction in CI and across labs.
- Automatic labels: Define success/failure with DOM and network invariants instead of heuristics.
- Drift on our terms: Inject CMPs, popups, banners, layout shifts, and microcopy variations to mimic the real web, but with traceable metadata.
The result is a closed-loop environment for SFT and RL that is cheaper, safer, and easier to debug than training on live sites, while still transferring skills to the open web with careful sim-to-real choices.
Design goals (and non-goals)
Goals:
- Reproducible and parameterized site generation
- High coverage of canonical web interactions
- Drift injection that mimics the messy web
- Automatic ground-truth labels with low false positives
- Efficient orchestration for millions of episodes
- Clear curriculum from easy to adversarial tasks
- Transparent telemetry (DOM, network, console) for debugging
Non-goals:
- Pixel-perfect reproduction of any specific commercial site
- Evasion of anti-bot systems on real properties
- Full-browser virtualization research (we rely on standard automation stacks)
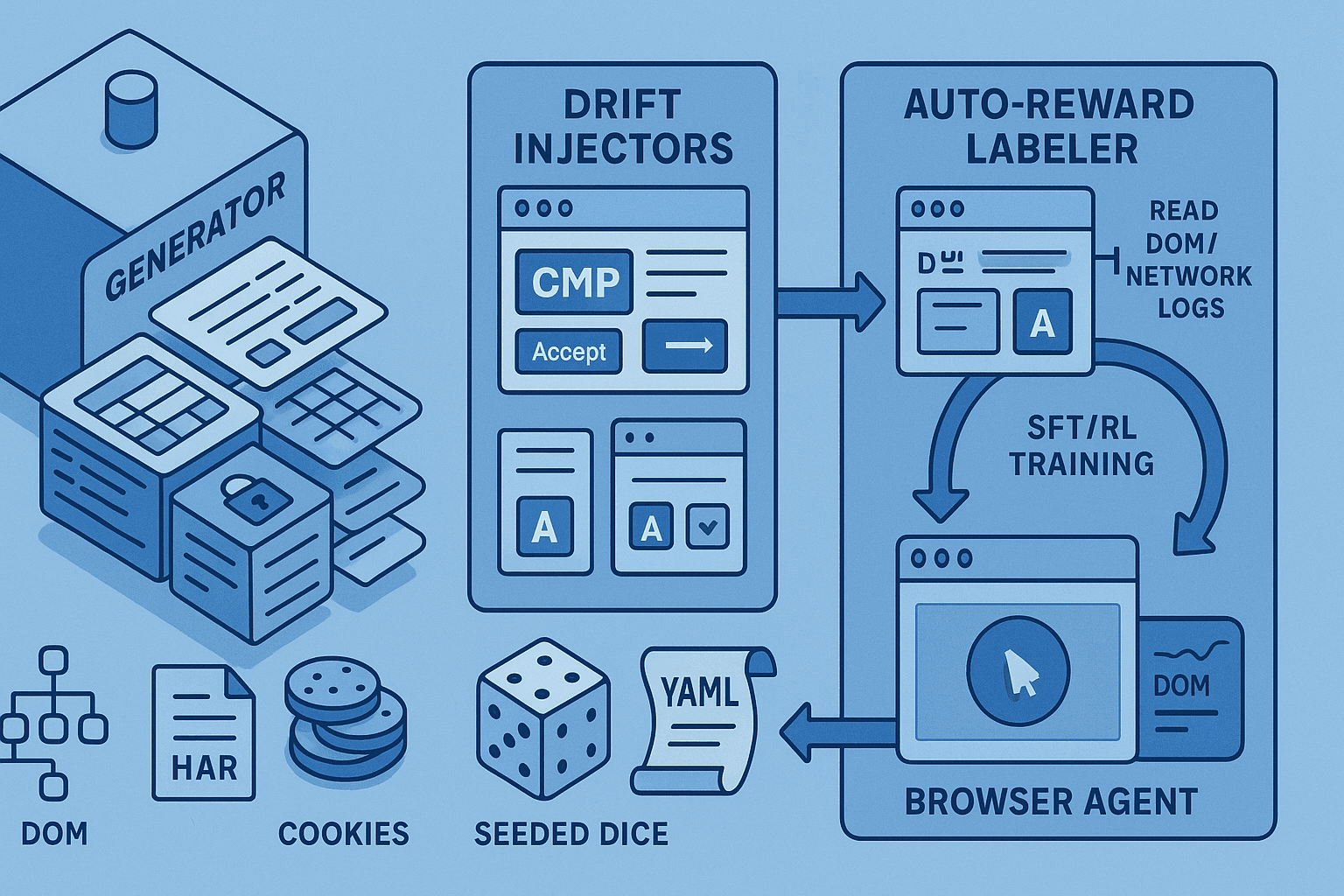
Architecture overview
Core components:
- Site generator: Produces parametric applications (SSR + client) with fixtures, seeded content, and standard patterns (forms, carts, tables, auth, i18n).
- Scenario DSL: Declares goals, preconditions, terminal conditions, and success invariants for each task.
- Drift fuzzer: Programmatically injects banners, popups, A/B variations, microcopy drift, layout perturbations, and latency/error chaos.
- Instrumentation & logger: Captures DOM snapshots, network HAR, cookies/localStorage, console logs, and accessibility trees.
- Auto-reward labeler: Evaluates DOM and network invariants to compute success/partial/failure and dense shaping signals.
- Agent runner: Playwright/Puppeteer/Selenium adapter to run scripted baselines and learned policies.
- Orchestrator: Distributes episodes, enforces seeds, aggregates artifacts, and writes datasets for SFT and RL.
A typical episode lifecycle:
- Orchestrator samples a scenario + seed -> generator emits a site variant.
- Drift fuzzer applies perturbations (e.g., cookie consent CMP injected).
- Runner launches a browser and executes agent policy.
- Instrumentation captures DOM/network traces.
- Auto-labeler computes rewards and labels.
- Artifacts and labels are stored, training data updated.
Procedural site blueprints
Cover the long tail of web tasks via composable blueprints, each with parameters that control difficulty and drift.
-
Forms and wizards
- Single- and multi-step forms (shipping, billing, profile, support tickets)
- Validation types: regex, cross-field dependencies, async server checks
- Input modalities: text, email, phone, radio, checkbox, select, date, file upload
- Accessibility: ARIA roles, labels, keyboard navigation
-
Tables, filters, pagination
- Server-side pagination and sorting
- Client-side filters with debounce and multi-select facets
- Infinite scroll, virtualized lists, sticky headers
- Row detail drawers and bulk actions
-
Carts and checkout
- Add/remove items, quantity updates, promo codes
- Tax/shipping calculation, currency/i18n
- Guest vs. authenticated checkout, address auto-complete
- Payment mocks: card entry, 3DS/OTP, wallet flow
-
Authentication and account flows
- Email/password with password reset
- OTP (email/SMS) and TOTP
- OAuth device code flow simulator (no external providers)
-
i18n and microcopy
- Multiple locales with pluralization rules
- RTL support
- Varying button microcopy (Buy now vs. Checkout vs. Continue)
-
System conditions
- Network flakiness, retries, and backoff
- Local storage state and cookies
- Feature flags toggled per seed
Each blueprint is modeled with parameters so we can sample across a wide space while retaining ground-truth invariants.
Scenario DSL: declaring goals and invariants
We need a compact, readable DSL to describe:
- Environment parameters (blueprints + seed)
- Initial state (e.g., items in cart)
- Goal specification
- Success criteria via DOM/network invariants
- Shaping/partial-credit rules
- Negative signals (tab crashes, console errors)
Example (YAML-like):
yamlversion: 1 id: checkout.apply_promo_and_pay seed: 123456 site: blueprint: ecommerce.checkout params: locale: en-US currency: USD taxRegion: CA items: - sku: SKU-001 qty: 2 - sku: SKU-007 qty: 1 payment: mode: card require3ds: true drift: cmpBanner: true abVariant: B popupProbability: 0.3 microcopyDrift: medium goal: natural: Apply promo code SPRING20, verify 20% discount on subtotal, then complete payment. success: dom: - css: '#order-summary .subtotal .value' equals: '$96.00' - css: '#promo-status' contains: 'SPRING20 applied' network: - method: POST url: '/api/payments/charge' body.json: amountCents: 12000 currency: 'USD' success: true url: contains: '/checkout/complete' shaping: partialCredit: - name: promo-accepted dom: - css: '#promo-status' contains: 'applied' - name: card-submitted network: - method: POST url: '/api/payments/charge' penalties: consoleErrors: -0.1 each pageReloads: -0.05 each unhandledModal: -0.2
With this DSL we can validate episodes deterministically and compute a scalar reward suitable for RL, alongside categorical success labels for SFT.
Drift injectors and fuzzers
Real websites are messy. Agents must handle variation. We inject controlled drift so that agents learn robust strategies.
Types of drift:
-
Consent Management Platforms (CMP)
- Banner blocks bottom 20% viewport
- Modal blocks clicks until Accept or Manage preferences
- Cookie categories toggles that re-render consent state
-
Popups and dialogs
- Newsletter prompt on first scroll
- Exit-intent modal
- Interstitial overlays with shadow DOM
-
A/B and layout drift
- Button label and position changes
- Swapping order of input fields
- Different checkout flow steps (2 vs. 3 steps)
-
Microcopy drift and i18n
- Synonyms for verbs (Apply vs. Redeem)
- Localized decimal separators and currency formats
- RTL direction and control ordering
-
Network and timing chaos
- 300–1200ms latency on key endpoints
- 5% flaky responses with retry semantics
- Reordered resource loads
-
Visual noise (optional)
- Ad placeholders, skeleton loaders, shimmering
- Sticky headers/footers pushing content
Each drift is annotated and recorded in metadata so that failures can be attributed and curriculum can adapt.
Example CMP injector (Express middleware):
js// Injects a consent banner into every HTML response with probability p. function cmpInjector(p = 0.5) { return (req, res, next) => { const send = res.send; res.send = function (body) { const shouldInject = Math.random() < p && /text\/html/.test(res.get('Content-Type') || ''); if (!shouldInject) return send.call(this, body); const banner = ` <div id='cmp-banner' role='dialog' aria-label='Cookie consent' style='position:fixed;bottom:0;left:0;right:0;background:#111;color:#fff;padding:16px;z-index:9999;'> <span>We use cookies to improve your experience.</span> <button id='cmp-accept'>Accept</button> <button id='cmp-manage'>Manage</button> </div> <script> document.getElementById('cmp-accept').onclick = () => { document.cookie = 'cmp=accepted; path=/'; document.getElementById('cmp-banner').remove(); window.dispatchEvent(new Event('cmp:close')); }; document.getElementById('cmp-manage').onclick = () => { alert('Preferences saved'); document.cookie = 'cmp=custom; path=/'; document.getElementById('cmp-banner').remove(); window.dispatchEvent(new Event('cmp:close')); }; </script>`; const updated = String(body).replace('</body>', `${banner}</body>`); return send.call(this, updated); }; next(); }; }
Auto-reward labeling via DOM and network invariants
Key idea: Success should be measured by state changes that the environment authoritatively knows, not by brittle selectors or screenshots. Invariants are schema-checked assertions over:
- DOM: Presence of elements, text content normalized, ARIA roles, input values, visibility/occlusion, disabled states
- URL: Path/query/hash
- Storage: Cookies/localStorage/sessionStorage
- Network: Request/response tuples, payload fields, status codes, order constraints
- Application state: In-memory store or test DB rows committed
Principles:
- Determinism: All checks are pure functions of recorded artifacts
- Composability: Multiple invariants combine into a scalar via a configurable aggregator
- Partial credit: Intermediate milestones yield shaped rewards
- Robustness: Normalize values (currency, whitespace, locale formats)
Reference evaluator (TypeScript):
tstype Invariant = | { kind: 'dom'; css: string; contains?: string; equals?: string; visible?: boolean } | { kind: 'network'; method: string; url: string; body?: Record<string, unknown> } | { kind: 'url'; contains?: string; equals?: string } | { kind: 'cookie'; name: string; value?: string }; interface EvalSpec { success: Invariant[]; partialCredit?: { name: string; invariants: Invariant[]; weight?: number }[]; penalties?: { kind: 'consoleError' | 'pageReload' | 'unhandledModal'; weight: number }[]; } export function evaluate(artifacts: any, spec: EvalSpec) { const ctx = buildContext(artifacts); // index DOM, network, url, cookies const score = { base: 0, partial: 0, penalties: 0 }; const ok = spec.success.every(inv => check(inv, ctx)); if (ok) score.base = 1.0; for (const p of spec.partialCredit || []) { const weight = p.weight ?? 0.2; if (p.invariants.every(inv => check(inv, ctx))) score.partial += weight; } for (const pen of spec.penalties || []) { const count = countPenalty(pen.kind, ctx); score.penalties -= count * pen.weight; } const total = Math.max(0, Math.min(1, score.base + score.partial + score.penalties)); return { success: ok, reward: total, breakdown: score }; } function check(inv: Invariant, ctx: any) { switch (inv.kind) { case 'dom': return checkDom(inv, ctx.dom); case 'network': return checkNet(inv, ctx.net); case 'url': return checkUrl(inv, ctx.url); case 'cookie': return checkCookie(inv, ctx.cookies); default: return false; } }
Normalization helpers should handle locale-specific number formatting, currency, and whitespace.
Training loops: SFT first, RL next
A practical training roadmap:
-
Bootstrap with scripted policies
- Deterministic baseline policies implemented with Playwright (e.g., locate by label, click-through CMP, fill known patterns)
- Use to collect first demonstration corpus
-
Supervised Fine-Tuning (SFT)
- Build an instruction-following dataset: (goal text, observation trace, action sequence)
- Include failure cases with contrastive annotations
- Add chain-of-thought rationales optionally (internal use only)
-
Preference modeling / DPO
- Sample multiple trajectories per scenario with different seeds and drift
- Label preferences by reward or heuristics (e.g., shorter, fewer steps, no console errors)
-
Offline/online RL
- Offline RL on synthetic buffer with reward from invariants
- Online RL with small epsilon for exploration, curriculum scheduling of drift
- Stabilize with reward clipping and entropy regularization
-
Continuous evaluation
- Hold out seeds and drift combinations for eval
- Track sim-to-real probes on a curated set of public demo sites (respecting ToS and rate limits)
Reference implementation: stack and code
Suggested stack:
- Generator: Next.js or Remix (SSR + client), TypeScript, React
- State: In-memory SQLite or Prisma with SQLite for determinism
- API: Express/Fastify with seed-aware fixture injection
- Automation: Playwright for browser control, HAR recording, video/screenshots
- Orchestration: Node worker pool or Python Ray; Docker for isolation
- Telemetry: OpenTelemetry for spans; NDJSON logs per episode
Seeded faker and fixtures:
tsimport seedrandom from 'seedrandom'; import { faker } from '@faker-js/faker'; export function withSeed(seed: number) { const rng = seedrandom(String(seed)); faker.seed(seed); Math.random = rng as any; // local scope in real code; avoid global override }
Parametric form blueprint (React):
tsximport React from 'react'; import { z } from 'zod'; export const AddressSchema = z.object({ name: z.string().min(2), line1: z.string().min(3), city: z.string().min(2), region: z.string().min(2), postal: z.string().min(3), phone: z.string().optional() }); type Address = z.infer<typeof AddressSchema>; export function AddressForm({ initial, labels }: { initial?: Partial<Address>; labels: Record<string, string> }) { const [data, setData] = React.useState<Address>({ name: initial?.name || '', line1: initial?.line1 || '', city: initial?.city || '', region: initial?.region || '', postal: initial?.postal || '', phone: initial?.phone || '' }); return ( <form aria-label={labels.form} id='address-form'> <label htmlFor='name'>{labels.name}</label> <input id='name' name='name' value={data.name} onChange={e => setData({ ...data, name: e.target.value })} /> <label htmlFor='line1'>{labels.line1}</label> <input id='line1' name='line1' value={data.line1} onChange={e => setData({ ...data, line1: e.target.value })} /> <label htmlFor='city'>{labels.city}</label> <input id='city' name='city' value={data.city} onChange={e => setData({ ...data, city: e.target.value })} /> <label htmlFor='region'>{labels.region}</label> <input id='region' name='region' value={data.region} onChange={e => setData({ ...data, region: e.target.value })} /> <label htmlFor='postal'>{labels.postal}</label> <input id='postal' name='postal' value={data.postal} onChange={e => setData({ ...data, postal: e.target.value })} /> <label htmlFor='phone'>{labels.phone}</label> <input id='phone' name='phone' value={data.phone || ''} onChange={e => setData({ ...data, phone: e.target.value })} /> <button type='submit' id='submit-address'>{labels.submit}</button> </form> ); }
Network invariant recorder (Express):
jsconst recorded = []; app.use((req, res, next) => { const chunks = []; const oldJson = res.json; res.json = function (body) { recorded.push({ ts: Date.now(), method: req.method, url: req.path, status: res.statusCode, reqBody: req.body, resBody: body }); return oldJson.call(this, body); }; next(); }); app.get('/_artifacts/network', (req, res) => res.json(recorded));
Playwright baseline runner:
tsimport { chromium } from 'playwright'; export async function runEpisode(scenario) { const browser = await chromium.launch(); const ctx = await browser.newContext(); const page = await ctx.newPage(); await page.goto(scenario.entryUrl); // Handle CMP if present const cmp = page.locator('#cmp-banner'); if (await cmp.isVisible().catch(() => false)) { await page.getByRole('button', { name: /accept|agree/i }).click().catch(() => {}); } // Example goal: apply promo and checkout await page.getByLabel(/promo code/i).fill('SPRING20'); await page.getByRole('button', { name: /apply|redeem/i }).click(); await page.getByLabel(/card number/i).fill('4242 4242 4242 4242'); await page.getByLabel(/expiry/i).fill('12/30'); await page.getByLabel(/cvc/i).fill('123'); await page.getByRole('button', { name: /pay|complete/i }).click(); // Capture artifacts const dom = await page.content(); const url = page.url(); const cookies = await ctx.cookies(); const net = await page.evaluate(async () => { const res = await fetch('/_artifacts/network'); return res.json(); }); await browser.close(); return { dom, url, cookies, net }; }
Reward aggregator and dataset writer:
tsimport fs from 'node:fs'; export function writeEpisode(episodeId, scenario, artifacts, evalResult) { const dir = `./runs/${episodeId}`; fs.mkdirSync(dir, { recursive: true }); fs.writeFileSync(`${dir}/scenario.json`, JSON.stringify(scenario, null, 2)); fs.writeFileSync(`${dir}/artifacts.json`, JSON.stringify(artifacts)); fs.writeFileSync(`${dir}/label.json`, JSON.stringify(evalResult)); }
Curriculum design and difficulty scaling
Start simple, then add drift and complexity systematically.
- Level 0: No drift, single-step tasks, simple forms and table filters
- Level 1: Add CMP banners and minor microcopy drift
- Level 2: Multi-step wizards, network latency, small error rates with retries
- Level 3: Popups and interstitials, layout shifts, RTL/i18n
- Level 4: Adversarial: conflicting hotkeys, shadow DOM overlays, infinite scroll, partial offscreen elements
Curriculum scheduler can use per-skill success rates to adapt: increase drift only when accuracy exceeds a threshold; reduce when model regresses.
Observability and debugging
Never train blind. Log and index:
- DOM snapshots and diffs across steps
- HAR or custom network logs
- Console logs and errors (tracebacks, React warnings)
- Accessibility tree snapshots
- Video/screenshot keyframes with annotations for actions
- Seed, drift, and feature-flag metadata
Use OpenTelemetry spans for:
- Episode run
- Drift injection subspans
- Agent action spans with attributes: locator strategy, latency, outcome
Add replay tooling to load an episode in a headless viewer (or in-head browser with overlays) to step through actions, view invariants, and see why labeling succeeded or failed.
Reproducibility and determinism
- Seed everything: faker, RNG, UUIDs, feature flags, sort orders, data fixtures, network chaos
- Version control the generator, DSL, and drift libraries; produce a content hash per episode config
- Pin npm/yarn/pip package versions and lockfiles
- Containerize with exact Node and browser versions; capture Playwright browser binaries
- Avoid time-of-day randomness (or normalize to a fixed epoch during runs)
A content-addressed artifact store (e.g., by hashing scenario + seed + git commit) makes it easy to deduplicate and cache.
Sim-to-real transfer: making synthetic count
Synthetic environments risk overfitting to toy patterns. Improve transfer:
- Use realistic HTML semantics: labels tied to inputs, ARIA roles, data-testid sparingly, dynamic classnames
- Avoid brittle IDs; prefer locator strategies that mirror real-world heuristics (role, name, text)
- Introduce naming and microcopy diversity; vary currency/locale/formatting
- Recreate common anti-patterns: hidden elements, lazy-loading, debounced clicks
- Mimic network edge cases: redirects, 401->login->redirect, flaky fetch with backoff
- Evaluate on a curated set of real demo sites (docs, storefront samples) within allowed usage
Evaluation metrics and benchmarks
Track both task-level outcomes and skill-level micro-metrics.
- Task success rate by scenario and drift level
- Time-to-success (steps and wall-clock)
- Error footprint: console errors per episode, unhandled modal count
- Robustness deltas across A/B and i18n variants
- Generalization to held-out seeds and drift combinations
- Sim-to-real transfer score on external probes
For RL stability, monitor reward variance, KL to reference policy, and catastrophic forgetting on earlier curriculum levels.
Scaling and cost
- Headless vs. headed: Headless is faster; use headed with video only for a sample of episodes
- Browser concurrency: 4–8 contexts per core is typical, tune by CPU/memory
- Artifact sampling: Store full videos for N%, screenshots for M%, always store logs and labels
- Cloud-friendly: Run generators and runners in containers; isolate via network namespaces if needed
- CI integration: Deterministic seeds for smoke tests; nightly wide sweeps for drift coverage
Risks and mitigations
-
Overfitting to gym patterns
- Mitigation: broad drift, microcopy diversity, periodic redesign of blueprints
-
Label leakage into prompts/actions
- Mitigation: segregate evaluator outputs from agent observations; never surface success hints
-
Reward hacking
- Mitigation: rely on network/backend invariants rather than DOM-only; randomize UI while keeping API contracts stable
-
Data privacy and security
- Mitigation: synthetic data only; no third-party calls; sanitize logs; redact secrets
Opinionated take: invariants beat magic
A lot of current web-agent demos rely on task-specific regex over screenshots or fragile selectors. That does not scale to RL. Explicit invariants—especially network-level checks—are the most reliable way to define rewards that are neither sparse nor noisy. Combined with systematic drift, this approach creates a curriculum that trains agents to handle the same annoyances human users do, but in a controlled, reproducible way.
Minimal end-to-end example
A tiny runnable sketch that ties the pieces:
-
Define a scenario JSON (converted from the YAML above) and persist it.
-
Start the generator with seed and drift flags.
bashnode server.js --seed=123456 --drift.cmp=true --drift.ab=B
- Run the baseline agent, collect artifacts.
tsconst artifacts = await runEpisode({ entryUrl: 'http://localhost:3000/checkout' });
- Evaluate and write labels.
tsenvSpec = loadEvalSpec('checkout.apply_promo_and_pay.json'); const result = evaluate(artifacts, envSpec); writeEpisode('ep-00001', envSpec, artifacts, result);
- Aggregate episodes into an SFT dataset and a replay buffer for RL.
json{ "prompt": "Goal: Apply SPRING20 and complete checkout. Current URL: /checkout. Visible elements: ...", "actions": [ { "type": "click", "locator": { "role": "button", "name": "Accept" } }, { "type": "fill", "locator": { "label": "Promo code" }, "value": "SPRING20" }, { "type": "click", "locator": { "role": "button", "name": "Apply" } }, { "type": "fill", "locator": { "label": "Card number" }, "value": "4242 4242 4242 4242" }, { "type": "click", "locator": { "role": "button", "name": "Pay" } } ], "label": { "success": true, "reward": 1.0 } }
Extensions and future work
- Multi-tab and multi-origin tasks (OAuth, third-party widgets) with sandboxed origin simulators
- File uploads and downloads with checksum invariants
- Email inbox simulator for email-based OTP and confirmation flows
- Keyboard-only and screen-reader-only curricula for accessibility robustness
- PDF viewers, canvas-heavy UIs, and WebGL/WebGPU content
- Program synthesis for blueprints from high-level specs
References and related work
- Playwright, Puppeteer, Selenium for automation backends
- Property-based testing and fuzzing (QuickCheck lineage) inspiring drift strategies
- RL from human feedback (RLHF), DPO, and offline RL literature for training loop design
- Academic environments: WebShop, MiniWoB++, and browser-task benchmarks
- Observability: OpenTelemetry, HAR formats
Conclusion
A synthetic web task gym is the pragmatic foundation for training capable, robust browser agents today. By procedurally generating diverse sites, injecting realistic drift, and labeling outcomes with invariant checks over DOM and network state, we can build large, reliable datasets for SFT and stable, informative rewards for RL. The approach is reproducible, scalable, and safer than scraping, yet close enough to real-world complexity to transfer. If you are serious about shipping browser agents, build the gym first and let invariants be your ground truth.