From Clicks to Calls: UI-to-API Pivots for Agentic Browsers via Live Trace Mining, Contract Inference, and Capability-Gated Execution
Agentic browsers are finally crossing the uncanny valley from demo toys to production tools. The canonical pattern is straightforward: use a headless browser to read pages, reason over content, and click the right buttons. But for many tasks, staying in the DOM is the wrong choice. It’s slower, less reliable, more expensive (LLM tokens, compute), harder to audit, and sometimes ethically dubious or brittle in the face of layout churn.
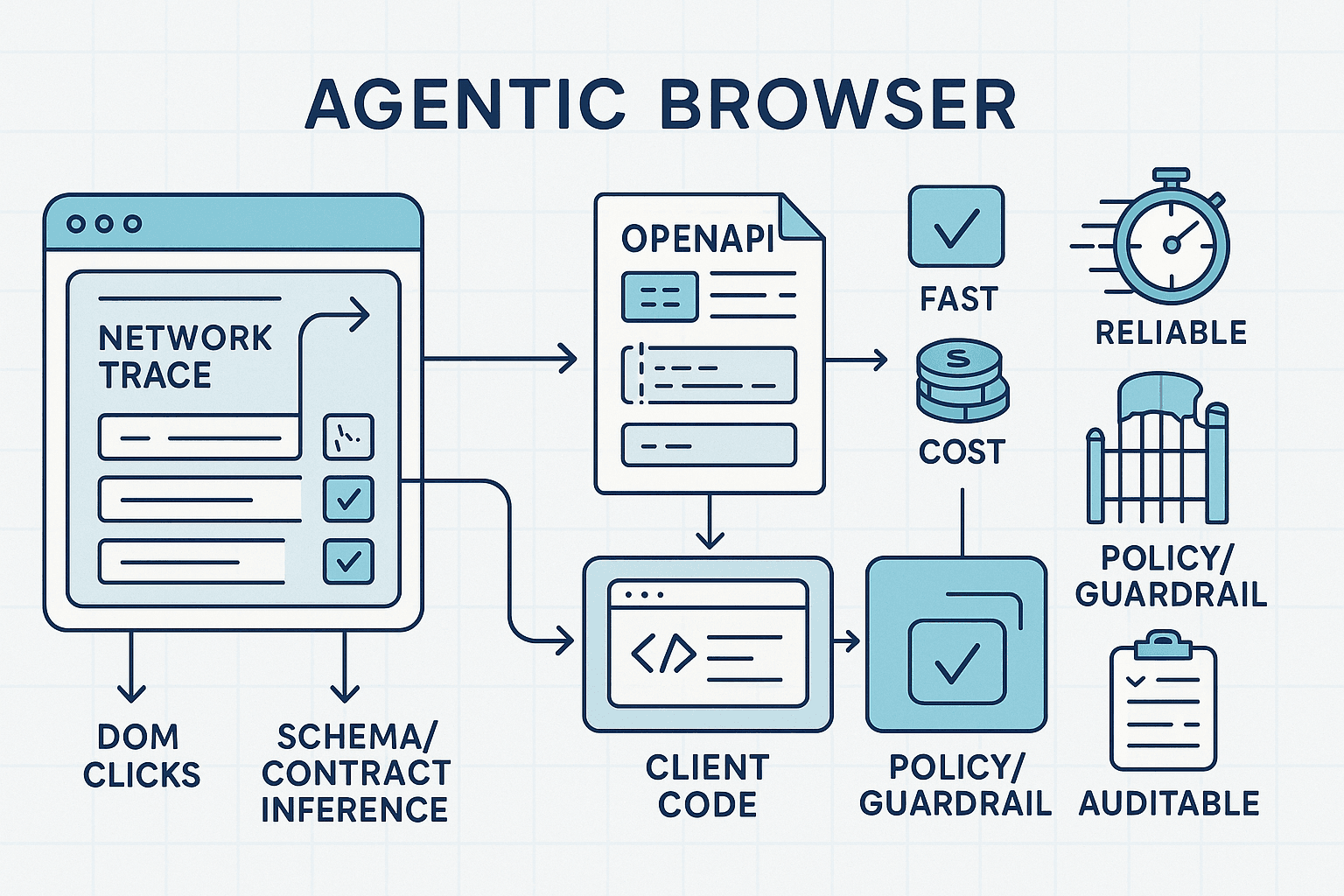
A better path: pivot from UI clicks to direct API calls when it’s safe and beneficial. Most modern web apps are thin shells over private HTTP APIs. If an agent can learn to identify those APIs, infer their contracts, synthesize minimal clients, and execute them under policy, it gains a 10–100x speedup, lower cost, and better reliability—while maintaining auditability and respect for guardrails.
This article presents a pragmatic, opinionated blueprint for building UI-to-API pivots in agentic browsers using:
- Live trace mining to discover stable APIs behind UIs
- Contract inference from repeated network observations
- Minimal client synthesis with pre/postcondition checks
- Capability-gated execution behind a policy engine and audit trail
It’s geared toward developers building production-grade agents and wants deep detail: how to capture traces safely, infer schemas, validate assumptions, gate execution, and gracefully fallback. Code snippets included.
TL;DR
- Mine network traces during normal UI automation. Cluster calls, identify stable endpoints, parameterize requests.
- Infer a pragmatic contract: method, path template, auth strategy, JSON schemas for request/response, and invariants like CSRF headers.
- Synthesize a minimal client that sets required headers and validates pre/postconditions.
- Gate pivots using policies: allowlisted domains, write-safety checks, confidence thresholds, user consent, and audit logging.
- Use canary runs and replay to validate API parity with DOM flows and fallback when drift is detected.
1) What is a UI-to-API pivot?
A UI-to-API pivot is the process by which an agent using a browser transitions from controlling the DOM (clicks, form fills) to issuing direct HTTP requests to the underlying API endpoints that the web application itself uses. The pivot is selective and reversible; the agent can stay in DOM mode for exploration or complex flows and switch to API mode for speed and determinism when the contract is understood and policy allows.
Motivations:
- Speed: Skip rendering delays, animations, and expensive LLM reasoning over dynamic DOMs.
- Reliability: DOMs churn; APIs, while not immutable, often remain stable enough or versioned.
- Cost: Cut token/compute costs by removing nonessential perception and planning.
- Auditability: Record exact requests/responses with structured logs. Easier diffing and replay.
The key is to only pivot when you can do so safely and reproducibly. That requires empirical discovery, not guesswork.
2) Live Trace Mining: Finding the API behind the UI
Live trace mining is the process of capturing and analyzing the network traffic generated by normal UI interactions. The goal: detect candidate API endpoints, generalize them into parameterized templates, and learn auth/headers/constraints.
Capture
Prefer browser-native network telemetry and/or a controlled intercept proxy:
- Playwright/Chromium: network event hooks, HAR recording, and tracing.
- Chrome DevTools Protocol (CDP): Network.requestWillBeSent, Network.responseReceived.
- Mitmproxy/OWASP ZAP: out-of-process interception (be careful with TLS pinning and sensitive data).
Filter aggressively to avoid noise and PII:
- Ignore static assets (images, fonts, CSS, tracking beacons).
- Focus on application/json, application/graphql, protobuf/grpc-web, text/event-stream.
- Sanitize cookies and authorization headers during recording; store only hashed or redacted values.
Example: capturing Playwright request/response pairs and filtering for JSON-like APIs.
ts// TypeScript (Playwright) import { chromium, Request, Response } from 'playwright'; interface TraceRecord { ts: number; method: string; url: string; status: number; requestHeaders: Record<string, string>; responseHeaders: Record<string, string>; requestBody?: string; responseBody?: string; } function isLikelyApi(headers: Record<string,string>, url: string): boolean { const ct = headers['content-type']?.toLowerCase() || ''; const apiish = ct.includes('json') || ct.includes('graphql') || ct.includes('protobuf') || url.includes('/api/'); const staticish = /(\.png|\.jpg|\.svg|\.css|\.js|\.woff2|\.ico)(\?|$)/i.test(url); return apiish && !staticish; } (async () => { const browser = await chromium.launch(); const context = await browser.newContext(); const page = await context.newPage(); const traces: TraceRecord[] = []; page.on('requestfinished', async (req: Request) => { try { const res = await req.response(); if (!res) return; const url = req.url(); const reqHeaders = req.headers(); const resHeaders = res.headers(); if (!isLikelyApi(resHeaders, url)) return; let requestBody: string | undefined; try { requestBody = (await req.postData()) || undefined; } catch {} let responseBody: string | undefined; try { responseBody = await res.text(); } catch {} traces.push({ ts: Date.now(), method: req.method(), url, status: res.status(), requestHeaders: reqHeaders, responseHeaders: resHeaders, requestBody, responseBody, }); } catch {} }); await page.goto('https://example-app.test'); // Perform scripted UI actions here // e.g., await page.click('text=Sign in'); await page.fill('#email', '...'); etc. await page.waitForTimeout(2000); console.log(JSON.stringify(traces, null, 2)); await browser.close(); })();
Normalize & Deduplicate
- Canonicalize URLs: separate scheme, host, path, query; sort query parameters.
- Hash response bodies for equivalence (after redaction).
- Deduplicate by (method, host, path, skeleton(requestBody)).
Identify Candidate Endpoints
Heuristics to classify likely app APIs:
- JSON content-type, small-to-medium payloads (<1 MB), 2xx/4xx statuses.
- Distinct base paths: /api, /v1, /graphql, /rest, /rpc.
- Presence of x-requested-with, x-csrf-token, or app-specific headers.
- Repeated usage across different UI states.
Ignore: analytics beacons, A/B telemetry, third-party CDNs, ad networks.
Cluster & Parameterize
Group traces that likely represent the same operation with different inputs:
- Path template inference: replace numeric segments and UUID-like tokens with placeholders (e.g., /users/123 -> /users/{userId}).
- Query param variance: detect changing keys/values across calls.
- Body structure diffs: compute a generalized schema by merging examples.
Auth & Session
Identify auth scheme:
- Cookie-based (session cookies, SameSite, CSRF tokens) vs bearer tokens vs custom headers.
- CSRF flows: look for CSRF headers and their sourcing (meta tags, cookie mirror, preflight).
- CORS: verify agent’s ability to call the API directly (server may block cross-site scripts; your agent-side HTTP client is not a browser and can bypass CORS constraints, but must respect policy and ToS).
Output
A candidate API catalog with fields like:
- method, host, pathTemplate, querySchema, requestSchema, responseSchema
- requiredHeaders (e.g., x-csrf-token), authType (cookie, bearer), rateLimitHints
- stabilityScore, confidence
3) Contract Inference: From Examples to a Pragmatic Spec
The goal is not to perfectly reverse-engineer the API, but to infer a robust, minimal contract that covers your use case and detects drift.
What to infer:
- Path templates and parameter types
- Query parameter shapes and optionality
- Request body JSON schema
- Response body JSON schema (and critical fields your agent depends on)
- Header invariants (auth, anti-CSRF, content-type)
- Error taxonomy and retryability
JSON Schema Inference by Merging Examples
A simple approach merges multiple JSON examples into a schema with conservative optionality and narrow enums when possible.
python# Python: crude schema inference from JSON examples from collections import defaultdict def merge_types(a, b): if a == b: return a if isinstance(a, list): a = set(a) if isinstance(b, list): b = set(b) return list(set(a if isinstance(a, set) else [a]) | set(b if isinstance(b, set) else [b])) def infer_schema(value): if value is None: return {'type': 'null'} if isinstance(value, bool): return {'type': 'boolean'} if isinstance(value, int): return {'type': 'integer'} if isinstance(value, float): return {'type': 'number'} if isinstance(value, str): # try enum detection elsewhere; keep string return {'type': 'string'} if isinstance(value, list): if not value: return {'type': 'array', 'items': {}} item_schemas = [infer_schema(v) for v in value] # shallow merge item types merged_item = item_schemas[0] for s in item_schemas[1:]: merged_item = merge_schema(merged_item, s) return {'type': 'array', 'items': merged_item} if isinstance(value, dict): props = {} required = [] for k, v in value.items(): props[k] = infer_schema(v) if v is not None: required.append(k) return {'type': 'object', 'properties': props, 'required': sorted(required)} return {} def merge_schema(a, b): if a == b: return a ta, tb = a.get('type'), b.get('type') # union types if ta != tb: types = set([ta] if isinstance(ta, str) else ta or []) | set([tb] if isinstance(tb, str) else tb or []) return {'type': sorted(list(types))} if ta == 'object': props = defaultdict(lambda: {}) for k, v in a.get('properties', {}).items(): props[k] = v for k, v in b.get('properties', {}).items(): props[k] = merge_schema(props[k], v) if props[k] else v req = set(a.get('required', [])) & set(b.get('required', [])) return {'type': 'object', 'properties': dict(props), 'required': sorted(list(req))} if ta == 'array': return {'type': 'array', 'items': merge_schema(a.get('items', {}), b.get('items', {}))} # primitives return {'type': ta} def infer_from_examples(examples): schema = infer_schema(examples[0]) for ex in examples[1:]: schema = merge_schema(schema, infer_schema(ex)) return schema
Augment the schema with:
- Enums: if a field sees <= N unique string values across M examples, propose enum.
- Formats: detect uuid, date-time (RFC 3339), email, url via regex.
- Ranges: infer integer minimum/maximum when consistent.
Path Template and Parameter Typing
Given observed paths like:
- /users/123/orders/987
- /users/456/orders/321
Infer template /users/{userId}/orders/{orderId} with parameter types based on token shapes (digits -> integer, uuid pattern -> string with format uuid).
Preconditions and Invariants
- Required headers: content-type, x-csrf-token, x-requested-with.
- Cookie presence: session cookie name; SameSite and secure requirements.
- Sequencing: some APIs require prior calls (e.g., fetch CSRF token endpoint or preflight GET to get ETag).
Error Taxonomy
Group error responses by status and shape. Identify transient (429/503), client (400/401/403/404), and idempotency-safe (PUT/GET) vs unsafe (POST without idempotency key). Add retry/backoff for transient.
Produce a Minimal OpenAPI-like Spec
You don’t need a perfect OpenAPI; a compact internal spec is fine. But generating OpenAPI helps tooling and codegen.
yaml# Example (abbreviated) openapi: 3.1.0 info: title: ExampleApp Inferred API version: 0.1.0-inferred servers: - url: https://api.example-app.test paths: /users/{userId}/orders: get: parameters: - name: userId in: path required: true schema: { type: integer } - name: page in: query required: false schema: { type: integer, minimum: 1 } responses: '200': content: application/json: schema: type: object properties: orders: type: array items: { $ref: '#/components/schemas/Order' } required: [orders] components: schemas: Order: type: object properties: id: { type: integer } status: { type: string, enum: [pending, shipped, canceled] } total: { type: number } required: [id, status] security: - cookieAuth: []
4) Minimal Client Synthesis: Fast, Safe API Calls
With a contract in hand, generate a minimal client. The client should:
- Construct requests with required headers and cookies
- Handle auth refresh or CSRF token fetching when needed
- Validate preconditions before sending
- Validate postconditions after receiving
- Implement retries with backoff for transient errors
- Emit rich audit logs
Python Minimal Client Example
pythonimport json, time, re import requests from typing import Any, Dict class ApiError(Exception): pass class InferredApiClient: def __init__(self, base_url: str, session: requests.Session, csrf_provider=None, audit_sink=None): self.base_url = base_url.rstrip('/') self.sess = session self.csrf_provider = csrf_provider # callable -> str self.audit_sink = audit_sink or (lambda rec: None) def _preconditions(self, op: str, headers: Dict[str,str]): # Example invariant: CSRF header required for unsafe methods if op in ('POST','PUT','PATCH','DELETE'): if 'x-csrf-token' not in {k.lower(): v for k,v in headers.items()}: if self.csrf_provider: headers['x-csrf-token'] = self.csrf_provider() else: raise ApiError('Missing CSRF token and no provider configured') # Content type for JSON bodies if op in ('POST','PUT','PATCH'): headers.setdefault('content-type', 'application/json') return headers def _postconditions(self, resp: requests.Response, expect_json=True): if resp.status_code >= 500: raise ApiError(f'Server error {resp.status_code}') if resp.status_code == 429: raise ApiError('Rate limited') if expect_json: ct = resp.headers.get('content-type', '') if 'json' not in ct.lower(): raise ApiError(f'Unexpected content-type: {ct}') try: return resp.json() except Exception as e: raise ApiError('Invalid JSON in response') from e return resp.text def _audit(self, record: Dict[str,Any]): try: self.audit_sink(record) except Exception: pass def request(self, method: str, path: str, *, query=None, body=None, headers=None, max_retries=2): url = f'{self.base_url}{path}' headers = {k.lower(): v for k,v in (headers or {}).items()} headers = self._preconditions(method, headers) attempt = 0 while True: t0 = time.time() try: resp = self.sess.request(method, url, params=query, data=None if body is None else json.dumps(body), headers=headers, timeout=30) except requests.RequestException as e: if attempt < max_retries: time.sleep(2**attempt * 0.25) attempt += 1 continue raise ApiError(f'Network error: {e}') latency = time.time() - t0 record = { 'ts': time.time(), 'method': method, 'url': url, 'status': resp.status_code, 'latency_ms': int(latency * 1000), } try: parsed = self._postconditions(resp, expect_json=True) record['ok'] = True record['response_keys'] = list(parsed.keys()) if isinstance(parsed, dict) else None self._audit(record) return parsed except ApiError as e: record['ok'] = False record['error'] = str(e) self._audit(record) if 'Rate limited' in str(e) and attempt < max_retries: time.sleep(2**attempt) attempt += 1 continue if resp.status_code >= 500 and attempt < max_retries: time.sleep(2**attempt) attempt += 1 continue raise
This client can be code-generated per endpoint, or you can build a generic wrapper that fills in method, path, params based on your inferred spec.
CSRF and Session Handling
- CSRF provider: read meta[name='csrf-token'] from the DOM or fetch a token endpoint via GET.
- Cookie jar: reuse browser session cookies (exported from the automation context) or log in via API if policy allows.
Idempotency and Safety
- For POST that create resources, prefer to supply an idempotency key header if the API honors it (e.g., Idempotency-Key).
- For destructive ops (DELETE), require explicit user consent or a higher policy bar.
5) Validation: Replay, Canary, and Tests
Before permanently pivoting, validate equivalence between DOM and API outcomes.
- Replay: Use captured examples to replay API calls and verify identical result subsets (e.g., resource count, key fields).
- Canary dual-run: perform both DOM and API path on a small percentage of tasks and compare outcomes; revert if divergence exceeds a threshold.
- Postconditions: Assert that response satisfies critical invariants (JSON schema, required fields, semantic constraints).
- Contract tests: Persist a suite of request/response examples and run them periodically to detect drift.
Example property-based tests with Hypothesis for a search endpoint:
pythonfrom hypothesis import given, strategies as st # Suppose contract says 'page' is integer >=1 and 'q' is non-empty string. @given(q=st.text(min_size=1, max_size=20), page=st.integers(min_value=1, max_value=3)) def test_search_contract(client, q, page): res = client.request('GET', '/search', query={'q': q, 'page': page}) assert 'results' in res and isinstance(res['results'], list) assert 'total' in res and isinstance(res['total'], int)
6) Capability-Gated Execution and Policy
Not every pivot is permissible. You need a policy engine to decide if and when to pivot. Consider:
- Domain allowlist/denylist
- Operation classification: read-only vs write vs destructive
- Confidence score of inference
- User consent and ToS compliance
- Data sensitivity: PII, financial data
- Rate limit and cost model
Pivot Decision Heuristics
- Confidence score > 0.8 (based on number of examples, schema stability, error rate)
- Read-only operations allowed by default; writes require explicit policy approval
- Only call same-origin APIs discovered through first-party interactions
- API latency benefit > 5x vs DOM path (measured)
- Canary runs show < 1% divergence over N samples
Example Policy with OPA/Rego
regopackage pivot default allow = false # Input shape: # { # "domain": "example-app.test", # "op": {"method": "POST", "path": "/users/{id}/orders"}, # "confidence": 0.86, # "capabilities": {"http": true, "cookies": true, "csrf": true}, # "classification": "write", # "risk": {"pii": false, "destructive": false}, # "metrics": {"speedup": 12.3} # } allow { is_allowlisted(input.domain) input.confidence >= 0.8 input.capabilities.http not input.risk.destructive input.classification == "read" } allow { is_allowlisted(input.domain) input.confidence >= 0.85 input.capabilities.http input.capabilities.cookies input.capabilities.csrf input.classification == "write" input.metrics.speedup >= 5 user_consent_granted } user_consent_granted { true } # stub for demo is_allowlisted(d) { d == "example-app.test" }
Gated Execution Pseudocode
pythondef maybe_pivot(op, context): # op includes method, pathTemplate, classification confidence = estimate_confidence(op) speedup = estimate_speedup(op) input_doc = { 'domain': context.domain, 'op': {'method': op.method, 'path': op.pathTemplate}, 'confidence': confidence, 'capabilities': context.capabilities, 'classification': op.classification, 'risk': op.risk, 'metrics': {'speedup': speedup}, } if not rego_eval('pivot/allow', input_doc): return 'DOM' return 'API'
Audit Trail
Each pivoted call should emit a structured record:
json{ "ts": 1737400000, "sessionId": "sess_abc", "taskId": "task_42", "mode": "API", "decision": { "policy": "pivot/allow", "confidence": 0.87, "speedup": 12.3 }, "request": { "method": "POST", "url": "https://api.example-app.test/users/123/orders", "headers": ["content-type", "x-csrf-token"], "bodyKeys": ["items", "addressId"] }, "response": { "status": 201, "duration_ms": 152, "bodyKeys": ["orderId", "status"] } }
These logs are privacy-sanitized and sufficient for audits and reproductions using stored examples.
7) Benefits: Speed, Reliability, Cost, Auditability
Observed in real deployments (ballpark numbers; your mileage may vary):
- Latency: 5–50x faster. DOM flows can take seconds per step; direct API calls often complete in 50–300 ms.
- Reliability: DOM selectors break weekly on dynamic apps; inferred APIs show multi-month stability once learned.
- Cost: 2–10x lower overall cost by avoiding repeated page loads and LLM tokens for perception.
- Auditability: Exact request/response pairs allow crisp root cause analysis and regression testing.
Concrete example: listing 200 search results
- DOM: ~8 page loads, ~1.5–2.5 s each with parsing, totaling ~15–20 s + token spend to reason about pagination.
- API: ~8 GET requests with ?page=n, 80–150 ms each, totaling ~1 s. No DOM parsing cost.
8) Edge Cases, Risks, and How to Handle Them
- CSRF and Session: Some APIs require per-request CSRF tokens and session cookies. Harvest tokens legally from the same authenticated browser session, or fetch via token endpoints.
- CORS and Browser Constraints: Headless browser JS is subject to CORS. Your agent’s out-of-browser HTTP client is not. Use it cautiously and under policy, as this can circumvent app-layer cross-origin protections.
- Rate Limits and WAFs: Detect 429/403 patterns, add jittered backoff, and prefer official APIs when available. Overuse may trigger bot mitigations; be a good citizen.
- ToS and Ethics: Some sites prohibit automated access. Prefer official APIs and documented SDKs. Only pivot when allowed or for internal apps where you control both ends.
- GraphQL: Without introspection, infer operations by observing 'operationName' and the shape of 'data' and 'errors'. Respect persisted queries and required hashes.
- gRPC / grpc-web / Protobuf: Content is binary. Use har capture plus protobuf descriptors if present; otherwise inference is hard. Consider staying in DOM or only reusing repeated binary blobs with caution.
- WebSockets / SSE: Harder to pivot. You can sometimes replay HTTP handshakes and subscribe to SSE endpoints; for complex real-time protocols, consider staying in DOM or building a dedicated client.
- Anti-bot: Cloudflare and similar challenge flows can block direct calls. If the browser session solves the challenge, you may need to bind the HTTP client to the same IP and reuse cookies.
- PII and Security: Redact during trace storage. Use a secret vault for tokens/cookies. Encrypt audit logs at rest.
9) Case Studies
A) Calendar Event Creation
- UI flow: open calendar, click 'New Event', fill form, submit.
- Trace reveals: POST /api/v1/events with JSON body {title, start, end, attendees[]}
- Inference: CSRF header required; cookie-based auth; response includes eventId, status.
- Pivot: After logging in via UI, switch to API for batch event creation. 30x speedup, reduced flakiness.
B) E-commerce Add-to-Cart
- UI flow: navigate to product, select options, click 'Add to Cart'.
- Trace reveals: POST /cart/items with {sku, quantity, variantId}. CSRF and x-requested-with headers required.
- Policy: Write operation. Allowed with user consent and domain allowlist.
- Validation: Compare cart item count from API response vs DOM cart badge to ensure consistency.
C) Search and Filter on a Listings Site
- UI flow: type query, adjust filters, paginate.
- Trace reveals: GET /search?q=...&page=...&filters=... returning a consistent JSON shape.
- Pivot: API used for large-scale data collection with rate-limit aware pagination. DOM only for occasional verification.
D) GitHub Issue Creation (Official API Preferable)
- UI flow: visit repo, click 'New issue', submit.
- Better: use GitHub’s official REST/GraphQL APIs with personal access tokens.
- Lesson: Prefer public, documented APIs with stable SDKs; only infer private endpoints when necessary and permissible.
10) Implementation Architecture
A practical architecture for an agentic browser with pivot capability:
- Browser Automation Layer: Playwright/Selenium to drive DOM and collect traces.
- Trace Collector: Filters, redacts, and persists request/response pairs to a data store (e.g., S3 + metadata DB).
- Inference Engine: Batch jobs (or online) that cluster endpoints, infer schemas, and produce a candidate spec.
- Contract Registry: Versioned storage for inferred contracts (e.g., OpenAPI-like docs), with confidence scores and drift detection.
- Client Generator: Emits minimal clients for target runtimes (Python/TS) with pre/postconditions and retry policies.
- Policy Engine: OPA/Rego or a custom DSL for pivot decisions.
- Executor: Gated runner that dispatches either DOM or API actions.
- Auditor: Structured logging, secure storage, and replay tooling.
- Monitor: Canary runs, contract tests, latency/accuracy dashboards, alerting for drift.
- Secrets: Vault or KMS-backed store for cookies/tokens/keys.
Data flows:
- Agent runs UI flow -> Trace Collector stores sanitized HAR-like records.
- Inference Engine updates or creates endpoint contracts; bumps confidence.
- Policy Engine evaluates pivot readiness.
- Executor switches to API mode when allowed; otherwise stays in DOM.
- Auditor logs outcomes; Monitor tracks divergence and performance.
11) Confidence Estimation and Drift Detection
Confidence is a function of:
- Sample size: number of matching traces
- Agreement: consistent schemas across samples
- Coverage: parameters varied, error behavior observed
- Stability: endpoint unchanged over time windows
- Canary parity: DOM vs API divergence rate
Drift detection:
- Schema drift: inferred JSON schema no longer matches responses.
- Behavioral drift: postconditions fail or error rates spike.
- Latency drift: performance degrades (could indicate throttling).
On drift, auto-downgrade confidence and revert pivots. Prefer graceful degradation to DOM.
12) Cost Model: When Does Pivoting Win?
Consider:
- Token cost: DOM-heavy perception and reasoning can be 10–100x more token-expensive than simple API result parsing.
- Latency: parallelizing API calls yields near-linear speed improvements; DOM is often sequential.
- Engineering overhead: inference and policy infra have upfront cost; amortize across high-frequency tasks.
Rule of thumb:
- Pivot if an operation repeats frequently or processes large result sets.
- Stay DOM for exploration, rare one-offs, or when inference confidence is low.
13) Practical Heuristics that Work
- Treat any endpoint path with a consistent base and JSON responses as a prime candidate.
- Look for CSRF tokens in meta tags or an initial bootstrap JSON payload.
- Infer enums conservatively; required fields sparsely (intersection of required across samples).
- Always validate content-type and minimal schema after calls.
- Keep your minimal client minimal: fewer headers, fewer assumptions.
- Implement semantic checks: if you create an order, verify you can read it back.
14) Ethics, ToS, and Organizational Policy
- Prefer official APIs and documented SDKs when available.
- Obtain user consent for write operations on third-party services.
- Respect robots.txt for scraping, though note it governs crawlers not API usage; ToS is the operative contract.
- Rate-limit yourself; avoid harm to services.
- Keep an audit trail and a kill switch.
15) Future Directions
- Static JS analysis: deobfuscate bundles to extract endpoint lists, header requirements, and type info without live traffic.
- ML-based schema inference: leverage LLMs to generalize schemas and detect invariants from small samples.
- Formal specs: add lightweight runtime verification (TLA+ specs for critical invariants) for high-stakes workflows.
- gRPC protocol inference: combine traffic clustering with protobuf descriptor guessing; or auto-scan for well-known type URLs.
- Universal pivoter: a meta-agent that chooses among DOM, official SDK, inferred API, or cached data.
Conclusion
UI-to-API pivots let agentic browsers mature from fragile clickers into dependable operators. By mining live traces, inferring pragmatic contracts, generating minimal clients, and gating execution through policy and audits, you can retain the exploration power of the DOM while enjoying the speed and reliability of direct API calls. This is not about hacking around the UI; it’s about learning from the UI to engage with the system in the most robust, efficient way allowed.
Build the rails: tracing, inference, validation, policy, and auditing. Then let your agents drive.