WebGPU‑Powered Hybrid Browser Agents
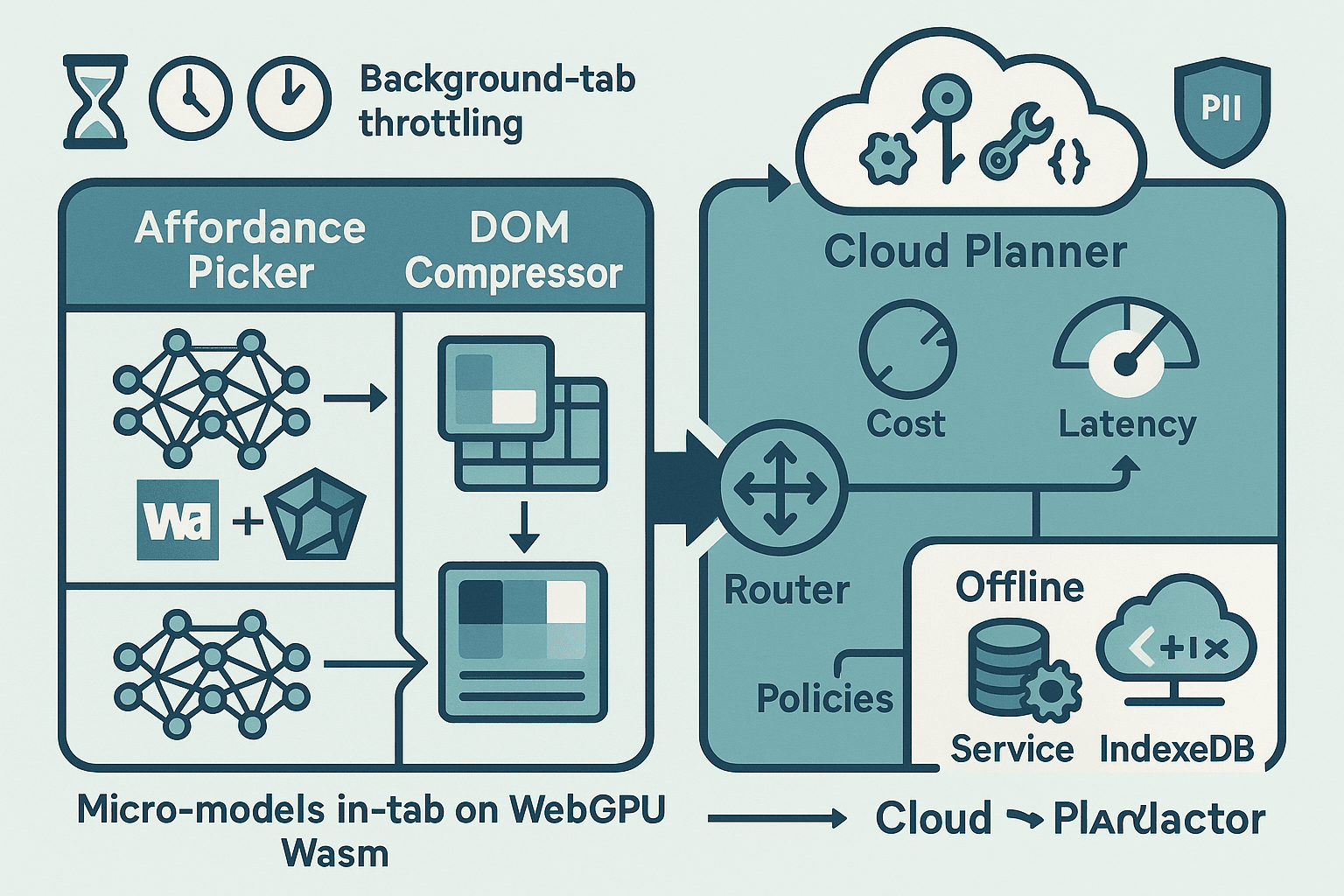
A practical way to build a trustworthy, fast, and privacy‑respecting browser agent today is to split its brain: keep tiny models in‑tab to perceive affordances and compress the DOM; escalate planning, reasoning, and long‑running work to a cloud LLM; and use a latency/cost router that adapts to GPU availability, background‑tab throttling, and offline conditions. This article lays out that architecture in detail, with code and concrete policies you can adopt right now.
We will design for the browser as it exists: timers get clamped in the background, pages can be frozen or discarded, GPU resources are limited, and memory pressure is real. We will also avoid shipping PII to the cloud by default, without sacrificing capability. If you care about user trust, total cost of ownership, and performance, this is the way.
Constraints and goals
- Latency: keep common interactions under perceptual thresholds (~100–200 ms for affordance feedback; <1 s for simple plans; <3 s for complex). See research on response time limits (e.g., Nielsen’s heuristics) and modern RAIL guidance.
- Cost: run the cheapest possible computation that achieves acceptable accuracy; escalate infrequently and intentionally.
- Robustness to lifecycle: survive visibility changes, background‑tab throttling, page freeze/discard, and intermittent connectivity.
- Privacy: never ship raw page text or screenshots by default; redact and hash aggressively; only send minimal, purpose‑bound features.
- Reach: work on devices with and without WebGPU; degrade gracefully to WebGL or WASM SIMD; work offline with reduced capability.
Architecture overview (split‑brain pipeline)
- In‑tab perception (micro‑models, WebGPU/WASM/ONNX):
- Affordance picking: score clickable/editable DOM elements for likely intent (e.g., “submit”, “next”, “price filter”).
- DOM compression: build a compact, privacy‑preserving page representation (selectors, roles, bounding boxes, redacted text hashes, structural graph) small enough for cloud planning.
- Latency/cost router:
- Predict hardness and cost; route easy cases to in‑tab heuristics or small models; route hard cases to the cloud LLM planner.
- Detect background throttling and memory pressure; checkpoint and offload long spans to cloud; resume from IndexedDB.
- Provider selection and timeout policies.
- Cloud LLM planner:
- Receives compressed DOM + task; produces tool‑grounded action plans (click, type, navigate, wait‑for, verify), not free‑form text.
- Streaming responses, partial commit, idempotent retries.
- Privacy and safety layer:
- Client‑side PII redaction; allowlist selectors/roles; cryptographic hashing of any residual text; optional end‑to‑end encryption (HPKE/OHTTP) for payloads.
- Lifecycle manager:
- Visibility and page lifecycle events; GPU context lifecycle; eviction/rehydration of models and caches; offline queue.
Think of the browser tab as a perceptual edge device that extracts task‑relevant features; the cloud acts as a high‑IQ planner of last resort.
In‑tab micro‑models: affordance picking and DOM compression
What “micro‑model” means here
- Size: <5–20 MB weights, ideally INT8 quantized.
- Runtime: ONNX Runtime Web (WebGPU or WASM backend), Transformers.js, or TFLite WASM.
- Throughput: run in <50 ms on mid‑range laptops with WebGPU; <150 ms on mobile with WASM SIMD.
Good candidates:
- Textual UI scoring: a distilled classifier (e.g., MiniLM, DistilBERT‑like, 4–12 layers, quantized) over short button/input texts.
- Layout/role features: gradient‑boosted trees or tiny MLP taking DOM structural features (role, tag, depth, clickable, visibility, size).
- Optional vision: iconography or tiny OCR if you really need it (MobileNet‑v2‑ish), but favor textual/structural features for privacy.
DOM feature schema (privacy‑preserving)
- Node key: stable CSS selector or hashed path.
- Role/tag: ARIA role, tagName, input type.
- Text features: length buckets, language code, normalized n‑gram hashes (e.g., SimHash or BLAKE3 of tokenized lowercase text), presence of digits/symbols.
- Geometry: bounding box snapped to a coarse grid (e.g., 32×18), not pixel‑accurate coordinates.
- State: enabled/disabled, visibility, z‑index bucket, fixed/absolute.
- Context: parent roles, sibling count, nearest label relationship.
Do not send raw text or screenshots by default; when needed, send only hashed n‑grams and coarse geometry. This preserves utility while removing obvious PII channels.
Implementation sketch: collecting features and scoring in‑tab
We’ll use ONNX Runtime Web with WebGPU when available, and automatically fall back to WASM with SIMD and threads when cross‑origin isolation is configured (COOP/COEP). If neither is available, we still run a heuristic scorer.
html<!-- Include ORT Web. Prefer a pinned version in production. --> <script type="module"> import * as ort from 'https://cdn.jsdelivr.net/npm/onnxruntime-web/webgpu/ort.min.js'; // Fallback to WASM backend if WebGPU is not available async function initORT() { if (globalThis.navigator.gpu) { await ort.env.wasm.wasmPaths('/path/to/ort-wasm/'); // still needed internally await ort.env.webgpu.init(); ort.env.wasm.numThreads = navigator.hardwareConcurrency ? Math.min(4, navigator.hardwareConcurrency) : 2; return { backend: 'webgpu' }; } else { await ort.env.wasm.wasmPaths('/path/to/ort-wasm/'); ort.env.wasm.simd = true; ort.env.wasm.numThreads = (crossOriginIsolated && navigator.hardwareConcurrency) ? Math.min(4, navigator.hardwareConcurrency) : 1; return { backend: 'wasm' }; } } const deviceInfo = await initORT(); console.log('ORT backend', deviceInfo.backend); </script>
Feature extraction (simplified):
jsfunction coarseGridBBox(el, gridW = 32, gridH = 18) { const r = el.getBoundingClientRect(); const vw = Math.max(document.documentElement.clientWidth, window.innerWidth || 0); const vh = Math.max(document.documentElement.clientHeight, window.innerHeight || 0); const x0 = Math.max(0, Math.min(gridW - 1, Math.floor((r.left / vw) * gridW))); const y0 = Math.max(0, Math.min(gridH - 1, Math.floor((r.top / vh) * gridH))); const x1 = Math.max(0, Math.min(gridW - 1, Math.ceil(((r.right) / vw) * gridW))); const y1 = Math.max(0, Math.min(gridH - 1, Math.ceil(((r.bottom) / vh) * gridH))); return { x0, y0, x1, y1 }; } function stableSelector(el) { // Prefer role/id/data-attributes; avoid text. const id = el.id && /^[a-zA-Z0-9_-]{1,64}$/.test(el.id) ? `#${el.id}` : ''; if (id) return id; const role = el.getAttribute('role'); const attrs = []; if (role) attrs.push(`[role="${CSS.escape(role)}"]`); const name = el.getAttribute('name'); if (name) attrs.push(`[name="${CSS.escape(name)}"]`); const type = el.getAttribute('type'); if (type) attrs.push(`[type="${CSS.escape(type)}"]`); const base = el.tagName.toLowerCase() + attrs.join(''); // Short path up to 3 ancestors let path = base; let p = el.parentElement; let depth = 0; while (p && depth < 3) { path = p.tagName.toLowerCase() + '>' + path; p = p.parentElement; depth++; } return path; } function hashText64(s) { // Use a fast non-cryptographic hash for feature bucketing, not for security. let h1 = 0xdeadbeef, h2 = 0x41c6ce57; for (let i = 0; i < s.length; i++) { const ch = s.charCodeAt(i); h1 = Math.imul(h1 ^ ch, 2654435761); h2 = Math.imul(h2 ^ ch, 1597334677); } h1 = (h1 ^ (h1 >>> 16)) >>> 0; h2 = (h2 ^ (h2 >>> 13)) >>> 0; return (BigInt(h1) << 32n) | BigInt(h2); } function textNGramHashes(el) { const txt = (el.innerText || el.value || '').trim().toLowerCase().slice(0, 64); if (!txt) return []; const tokens = txt.split(/\s+/).filter(Boolean); const grams = []; for (let i = 0; i < tokens.length; i++) { grams.push(tokens[i]); if (i + 1 < tokens.length) grams.push(tokens[i] + ' ' + tokens[i+1]); } return grams.slice(0, 8).map(t => hashText64(t).toString(16)); } function featureVectorFor(el) { const role = el.getAttribute('role') || ''; const tag = el.tagName.toLowerCase(); const type = (el.getAttribute('type') || '').toLowerCase(); const enabled = !el.disabled; const visible = !!(el.offsetWidth || el.offsetHeight || el.getClientRects().length); const bbox = coarseGridBBox(el); const ngrams = textNGramHashes(el); const fv = { key: stableSelector(el), role, tag, type, enabled: enabled ? 1 : 0, visible: visible ? 1 : 0, bbox, text_hashes: ngrams, // hashed features only siblings: el.parentElement ? el.parentElement.children.length : 0, depth: (() => { let d=0, p=el.parentElement; while (p) { d++; p=p.parentElement; } return d; })(), }; return fv; } function collectCandidates(root=document) { const nodes = Array.from(root.querySelectorAll('a, button, input, [role="button"], [role="link"], [tabindex]')); return nodes.map(el => ({ el, fv: featureVectorFor(el) })); }
Scoring via ONNX (assuming you’ve trained a small MLP/Transformer over the feature schema and exported to ONNX):
jsimport * as ort from 'onnxruntime-web'; // or via CDN as shown earlier let affordanceSession; async function loadAffordanceModel(url) { const sessOpts = { executionProviders: ['webgpu', 'wasm'] }; affordanceSession = await ort.InferenceSession.create(url, sessOpts); } function fvToTensor(fv) { // Example: fixed-length float/int inputs derived from fv // Map categorical to indices; bucketize bbox and sizes; embed text_hashes as Bloom filter bits. const v = new Float32Array(128); // ... populate v deterministically from fv ... return new ort.Tensor('float32', v, [1, 128]); } async function scoreCandidates(cands) { if (!affordanceSession) throw new Error('Model not loaded'); const inputs = cands.map(c => fvToTensor(c.fv)); // Batch if model supports it; for brevity, score sequentially const scores = []; for (const t of inputs) { const out = await affordanceSession.run({ 'input': t }); scores.push(out['score'].data[0]); } return cands.map((c, i) => ({ ...c, score: scores[i] })); }
With this in place, the in‑tab agent can rapidly highlight likely targets, guide keyboard navigation, and prepare a compact DOM snapshot when a task needs cloud planning.
DOM compression for the cloud planner
The goal is to reduce the page to a few kilobytes of structured data: enough for the planner to reason about actions without needing pixels or raw text. A practical format:
json{ "url": "https://example.com/search?q=webgpu", "viewport": { "grid": [32, 18] }, "nodes": [ { "key": "div>form>input[name=search][type=text]", "role": "textbox", "tag": "input", "type": "text", "bbox": { "x0": 2, "y0": 2, "x1": 12, "y1": 3 }, "visible": 1, "enabled": 1, "text_hashes": ["a1b2...", "c3d4..."], "score": 0.78 }, { "key": "button#submit", "role": "button", "tag": "button", "bbox": { "x0": 13, "y0": 2, "x1": 15, "y1": 3 }, "text_hashes": ["..."], "score": 0.66 } ], "relationships": [ ["div>form", "contains", "div>form>input[name=search][type=text]"] ], "redaction_salts": { "text": "slt-2024-10" } }
This is small, schema‑stable, and safe to log server‑side. If you truly need semantics from text, use on‑device NER and send only redacted spans and hash commitments.
The latency/cost router
The router decides, at each step, where to run what. It sits between the UI and the planner.
Key signals:
- Hardware: navigator.gpu, crossOriginIsolated, deviceMemory, hardwareConcurrency.
- State: document.visibilityState, document.wasDiscarded, pageshow/pagehide, online/offline.
- Load: approximate token count from compressed DOM, model confidence of affordance picks.
- SLO: user action type (urgent interaction vs background crawl), budgeted latency and max $/task.
Policies that work well in practice:
- Fast path: If a top‑1 affordance score > τ_high and task is a simple click/type within last context, execute locally; verify post‑condition with another micro‑model pass.
- Compress‑then‑plan: If confidence is medium or task is multi‑step, compress DOM and call a small cloud LLM with tool schema.
- Progressive enhancement: Start with a cheap model (e.g., 1–3B LLM) and escalate to a larger model only if validation fails or uncertainty remains high.
- Background survival: On visibility change to hidden, stop long in‑tab compute; checkpoint to IndexedDB; delegate long reasoning or scraping loops to the cloud; poll results opportunistically or on resume.
- Offline: Queue intent and run only in‑tab models; show a banner; auto‑retry cloud steps when online.
Pseudocode for the router:
jsconst Router = { cfg: { tauHigh: 0.82, tauLow: 0.55, slo: { interactMs: 200, planMs: 1500 }, maxCostCents: 2.0, // per task providers: [ { name: 'cheap', tps: 20, rpm: 1200, costTok: 0.05, timeoutMs: 800 }, { name: 'smart', tps: 5, rpm: 300, costTok: 0.2, timeoutMs: 2000 }, ], }, async decide(task, context) { const { visible } = context.lifecycle; const cands = collectCandidates(); const scored = await scoreCandidates(cands); const top = scored.sort((a,b)=>b.score-a.score)[0]; if (top && top.score >= this.cfg.tauHigh && task.kind === 'click_or_type') { return await this.localAct(task, top); } const domPack = compressDOM(scored); const approxTokens = estimateTokens(domPack); const provider = this.pickProvider(approxTokens, context); if (!navigator.onLine || !provider) { return this.offlineFallback(task, scored); } const plan = await this.cloudPlan(task, domPack, provider); if (!plan.ok) { // escalate once if within budget if (!provider.escalated) return this.cloudPlan(task, domPack, this.escalate(provider)); return { ok: false, error: 'planning_failed' }; } return await this.executePlan(plan, { scored }); }, pickProvider(tokens, ctx) { // Simple heuristic: try cheap if fits timeout/cost; else smart const cheap = this.cfg.providers[0]; const cheapLatency = predictLatency(cheap, tokens); const cheapCost = tokens * cheap.costTok / 1000; // per 1K tok if (cheapLatency < this.cfg.slo.planMs && cheapCost < this.cfg.maxCostCents) return cheap; return this.cfg.providers[1]; }, escalate(p) { return { ...this.cfg.providers[1], escalated: true }; }, // ... cloudPlan/localAct/executePlan implementations ... };
This pattern pushes the high‑variance work to the cloud only when necessary, keeps common interactions snappy, and makes cost explicit.
Cloud LLM planner: tool grounding over compressed DOM
Use a tool schema that is executable and idempotent. The planner’s job is not to “guess the page,” but to sequence constrained actions.
- Tools: click(selector), type(selector, text), select(selector, option), waitFor(selector or condition), navigate(url), verify(assertion).
- Inputs: compressed DOM, task text, recent history (redacted), optional previous failures.
- Output: JSON plan with steps and stop conditions; optional “uncertainty” annotations to drive escalation.
Example prompt sketch:
json{ "system": "You are a deterministic planner for web UI automation. You only emit tool calls defined in the schema. Never hallucinate selectors; select from provided nodes by key.", "tools": [ { "name": "click", "args": ["key"] }, { "name": "type", "args": ["key", "text"] }, { "name": "waitFor", "args": ["predicate"], "predicates": ["exists(key)", "navigated(urlPrefix)"] }, { "name": "verify", "args": ["assertion"], "assertions": ["exists(key)", "notExists(key)"] } ], "user": { "task": "Search for 'webgpu onnx' and open the first result.", "dom": { /* compressed DOM as above */ } } }
On the server, strictly validate tool calls against the provided keys. Never allow arbitrary CSS selectors or raw XPath from the model; require it to reference keys from the compressed DOM to prevent data exfiltration.
Surviving background‑tab throttling
Reality check (Chromium/WebKit/Gecko as of 2024):
- Hidden tabs have timers clamped (e.g., to 1 per minute in Chromium), requestAnimationFrame is paused, certain network and CPU usage is aggressively throttled.
- After minutes idle, a tab can be frozen; after longer or under pressure, it can be discarded entirely. See the Page Lifecycle API documentation (web.dev/page-lifecycle) and document.wasDiscarded.
- WebGPU/WebGL contexts can be lost. Workers are throttled too.
Patterns that work:
- Short bursts only in background: do quick micro‑model passes (<50 ms), then yield. No long loops.
- Checkpoint aggressively: write plan state and partial results to IndexedDB; write before awaiting long ops.
- Delegate: move long reasoning/scraping to the cloud; poll results on visibilitychange back to visible or with infrequent background pings (respect clamping).
- Use pagehide/pageshow and visibilitychange; subscribe to freeze/resume where available on Chromium.
- Be idempotent: every action and network call must be retryable.
Lifecycle glue:
jsconst lifecycle = { visible: document.visibilityState === 'visible', discarded: Boolean(document.wasDiscarded), }; window.addEventListener('visibilitychange', () => { lifecycle.visible = document.visibilityState === 'visible'; if (!lifecycle.visible) { saveCheckpoint().catch(console.warn); // Cancel long local compute, delegate to cloud if needed } else { // On resume, refresh DOM features and reconcile with any cloud plan reconcileFromCheckpoint().catch(console.warn); } }); window.addEventListener('pagehide', () => saveCheckpoint()); window.addEventListener('pageshow', (e) => { if (e.persisted) { // bfcache restore reconcileFromCheckpoint(); } }); // Chrome-only experimental // document.addEventListener('freeze', saveCheckpoint); // document.addEventListener('resume', reconcileFromCheckpoint);
For networking during unload, use fetch keepalive sparingly for telemetry or plan cancellation; it’s not a compute primitive.
Memory pressure and GPU lifecycle
- Model caching strategy: LRU cache of small models in memory; store quantized weights in Cache Storage and/or IndexedDB; lazy‑load on use; prefetch only top‑N.
- GPU resources: WebGPU buffers and textures should be explicitly destroyed when no longer needed; recreate a device on context loss.
- Measurement: performance.measureUserAgentSpecificMemory() (Chromium) gives a coarse idea of memory footprint; navigator.deviceMemory hints device class.
- Backoff: if memory use jumps (or GPU context lost), fall back to smaller models or WASM backend.
Example cache and cleanup pattern:
jsclass ModelCache { constructor(limitMB = 64) { this.limitMB = limitMB; this.map = new Map(); this.total = 0; } async get(key, loader) { if (this.map.has(key)) { const entry = this.map.get(key); entry.at = performance.now(); return entry.model; } const model = await loader(); const size = model.byteSizeMB || 10; // attach to session after load this.map.set(key, { model, size, at: performance.now() }); this.total += size; await this.evictIfNeeded(); return model; } async evictIfNeeded() { while (this.total > this.limitMB) { // remove oldest let oldestKey, oldestAt = Infinity; for (const [k, v] of this.map.entries()) if (v.at < oldestAt) { oldestAt = v.at; oldestKey = k; } const v = this.map.get(oldestKey); await this.dispose(v.model); this.map.delete(oldestKey); this.total -= v.size; } } async dispose(model) { // For ORT/transformers.js, release GPU/WebGL contexts if exposed if (model.release) await model.release(); if (model.detach) model.detach(); } } // GPU context loss handling if (navigator.gpu) { const adapter = await navigator.gpu.requestAdapter(); const device = await adapter.requestDevice(); device.lost.then(info => { console.warn('WebGPU device lost', info); // Trigger model/session recreation on next use }); }
Offline modes and eventual consistency
Agents should not stop being useful offline.
- What still works: affordance highlighting, simple click/type macros, DOM compression into local queue, on‑device redaction and validation.
- Queue: store tasks and compressed DOM in IndexedDB with a retry policy when navigator.onLine flips true.
- UI: show offline banner; allow user to explicitly trigger retries.
Example offline queue:
jsimport { openDB } from 'https://cdn.jsdelivr.net/npm/idb@7/+esm'; const db = await openDB('agent', 1, { upgrade(db) { db.createObjectStore('queue', { keyPath: 'id', autoIncrement: true }); } }); async function enqueueCloudPlan(task, domPack) { await db.put('queue', { task, domPack, ts: Date.now(), status: 'pending' }); } async function drainQueue(sendPlan) { if (!navigator.onLine) return; const tx = db.transaction('queue', 'readwrite'); const store = tx.store; for await (const cursor of store) { const item = cursor.value; try { await sendPlan(item.task, item.domPack); await cursor.delete(); } catch (e) { console.warn('retry later', e); } } await tx.done; } window.addEventListener('online', () => drainQueue(sendPlanToCloud));
GPU‑less fallbacks that still feel good
- Priority 1: ORT Web WASM backend with SIMD + threads (requires cross‑origin isolation: COOP+COEP headers) for 2–4× speedup.
- Priority 2: WebGL backend (for certain libraries) when WebGPU isn’t there but GPU is accessible; be mindful of context limits.
- Priority 3: Heuristics only (no model): rule‑based affordance scores from roles/tags/words like “submit”, “next”, “add to cart”.
Feature detection and selection:
jsasync function pickBackend() { const hasWebGPU = !!navigator.gpu; const hasCOI = globalThis.crossOriginIsolated === true; if (hasWebGPU) return 'webgpu'; if (hasCOI) return 'wasm-simd-threads'; return 'wasm-singlethread'; } const BACKEND = await pickBackend(); console.log('Compute backend:', BACKEND);
Make sure you set COOP/COEP headers to unlock SharedArrayBuffer and threads:
- Cross‑Origin‑Opener‑Policy: same‑origin
- Cross‑Origin‑Embedder‑Policy: require‑corp
See web.dev/coop-coep for details.
PII‑safe by construction
Avoid accidental data exfiltration. Simple, fast measures go a long way.
- Redact in‑tab:
- Run regexes for emails, phone numbers, SSNs, credit cards; replace with [PII:TYPE] tokens before any cloud call.
- Use on‑device NER (distilled) only if you truly must catch more; otherwise rely on allowlists and hashing.
- Hash aggressively: only ship BLAKE3/SHA‑256 hashes of tokenized texts (plus a rotating salt); never ship the salt in the same request if you plan to verify server‑side.
- Minimize visual data: don’t send screenshots unless the user opts in; if necessary, send low‑res binary masks of affordances rather than pixels.
- Pin egress: send only to your own endpoint; block all third‑party beacons in agent code.
- Encrypt payloads: TLS is default; if you require additional unlinkability at the edge, consider OHTTP (Oblivious HTTP) or HPKE‑wrapped payloads.
Example redactor:
jsfunction redactPII(s) { if (!s) return s; return s .replace(/\b[\w.%+-]+@[\w.-]+\.[A-Za-z]{2,}\b/g, '[PII:EMAIL]') .replace(/\b\+?\d[\d\s().-]{7,}\b/g, '[PII:PHONE]') .replace(/\b\d{3}-?\d{2}-?\d{4}\b/g, '[PII:SSN]') .replace(/\b(?:\d[ -]*?){13,19}\b/g, '[PII:CARD]'); } function hashedTokens(s, salt) { if (!s) return []; const clean = redactPII(s.toLowerCase()); const toks = clean.split(/\s+/).filter(Boolean).slice(0,16); return toks.map(t => crypto.subtle.digest('SHA-256', new TextEncoder().encode(salt + t))) .map(async p => Buffer.from(await p).toString('hex').slice(0,16)); }
Also adopt a negative control: run a local check that blocks sending if the compressed DOM contains suspect attributes (e.g., input[type=password], credit card patterns) or if the page origin is in a policy‑blocked list (banking, healthcare unless user‑approved).
Putting it all together: an end‑to‑end flow
- User triggers an intent (“apply min price $50 and sort by rating”).
- In‑tab: run affordance picker on buttons/inputs; if confidence is high, attempt local act+verify with a 150 ms SLO.
- If not confident: compress DOM with hashed text features and coarse geometry; apply PII redaction.
- Router estimates token count and picks the cheap cloud model; sends a tool‑bounded prompt.
- Cloud planner returns a 3‑step plan; client executes each step with local verification between steps.
- If the tab goes backgrounded mid‑execution: checkpoint to IndexedDB; if a step would take long, hand off to cloud to continue reasoning; resume on visibilitychange or on user return.
- Success or failure is logged locally and, if permitted, to your telemetry endpoint without raw page data.
This hybrid approach yields predictable latency, lower spend, and a smaller privacy attack surface.
Training notes for the affordance micro‑model
- Labels: collect interaction logs (clicks, successful form submissions) and weak supervision from HTML semantics (role=button, input[type=submit]) to generate positive examples; negative sampling from other nodes.
- Features: use the schema above; avoid raw text. For token semantics, rely on hashed n‑grams; the model learns correlations without seeing plaintext.
- Size/quantization: aim for INT8; ONNX Runtime Web supports quantized ops; test accuracy loss carefully.
- Evaluation: top‑1 precision/recall at k; latency on mid‑tier hardware; memory footprint; robustness across sites.
Validation and safety checks
- Post‑conditions: every local action must be validated (e.g., element exists and is visible after click; URL changed if navigation expected). If validation fails, roll back (navigate back) or escalate.
- Sandboxing: don’t allow the planner to type arbitrary secrets; prevent typing into password fields by policy.
- Rate limits: respect site norms; add waits with exponential backoff on 429/503; never hammer.
Opinionated guidance
- Don’t try to run full LLMs in‑tab for general planning unless your audience is niche and you’re okay with multi‑second latencies and heavy VRAM; micro‑models for perception are the sweet spot.
- WebGPU is fantastic when available, but design first for WASM SIMD+threads; you’ll thank yourself on enterprise laptops and iOS.
- Compression over screenshots: textual/structural signals win for both privacy and transfer size; only add pixels as an opt‑in last resort.
- Make cost and latency budgets first‑class config; observe and adapt automatically; fail fast to cheaper models and escalate only when validation says so.
- Treat backgrounding as the default case: checkpoint early, often, and idempotently.
References and further reading
- WebGPU spec and explainer: https://gpuweb.github.io/gpuweb/
- ONNX Runtime Web backends: https://onnxruntime.ai/docs/execution-providers/Web.html
- Transformers.js (browser inference): https://xenova.github.io/transformers.js/
- WebLLM (MLC AI): https://github.com/mlc-ai/web-llm
- Page Lifecycle API: https://web.dev/page-lifecycle-api/
- document.wasDiscarded: https://web.dev/was-discarded/
- Cross‑origin isolation (COOP/COEP): https://web.dev/coop-coep/
- Background Sync: https://developer.mozilla.org/en-US/docs/Web/API/Background_Synchronization_API
- Memory measurement in Chromium: https://web.dev/monitor-total-page-memory-usage/
- OHTTP (IETF OHAI): https://datatracker.ietf.org/wg/ohai/about/
- HPKE (RFC 9180): https://www.rfc-editor.org/rfc/rfc9180
Closing
Split‑brain browser agents are not just a research curiosity—they are a practical, deployable pattern. Small, privacy‑preserving perception in the tab; disciplined compression; a cost‑aware router; and a cloud planner with tight tool grounding deliver the best of both worlds. Build for throttling, for offline, and for failure; your users will experience speed and reliability, and your infra bill and risk surface will thank you.