Executive summary
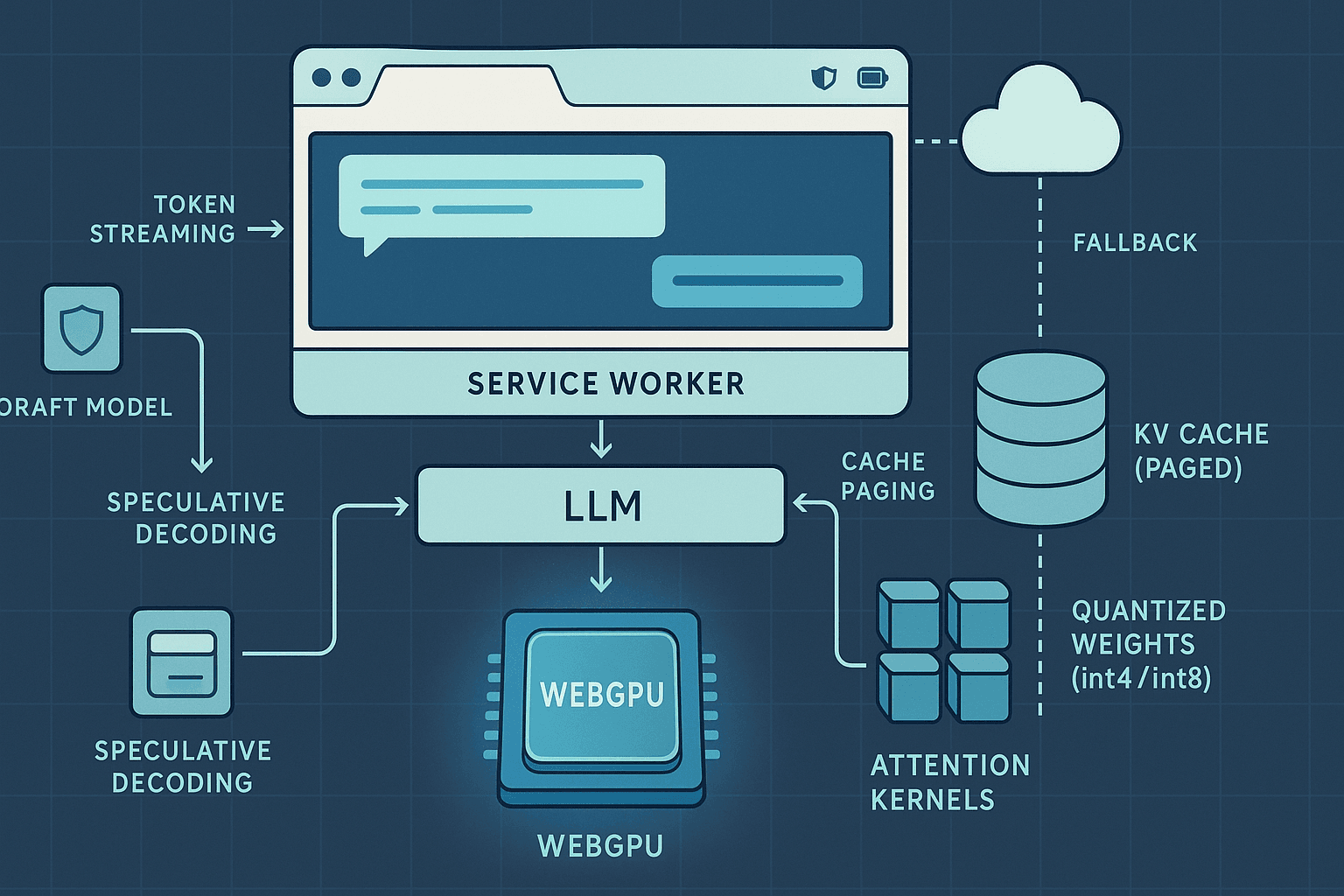
The browser has quietly become a serious AI runtime. With WebGPU now shipping in stable Chrome, Edge, and Firefox (behind flags or in Nightly), it is practical to run quantized large language models (LLMs) entirely on-device, inside a tab, without native drivers or extensions. Combined with Service Workers, IndexedDB/OPFS, and a carefully configured security model (COOP/COEP for SharedArrayBuffer), we can build an offline-first agent stack that streams tokens, pages KV cache to disk, and dynamically routes to the cloud when local latency or energy budgets are exceeded.
This article details a production-minded blueprint for an AI browser agent that:
- Packages and serves quantized LLMs optimized for WebGPU
- Enables SharedArrayBuffer via cross-origin isolation (COOP/COEP)
- Streams tokens to the UI through a Service Worker, not the main thread
- Pages the KV cache to IndexedDB/OPFS to support long contexts
- Adds speculative decoding (draft+target models) and a cloud fallback
- Profiles latency, throughput, GPU memory, and approximates energy use
- Preserves privacy by keeping prompts local and encrypting persisted state
The audience is expected to be comfortable with JS/TS, Web Workers, GPU concepts, and LLM inference. Code snippets are illustrative and omit full error handling to focus on architecture.
- Architecture blueprint
A minimal, robust browser agent architecture separates concerns:
-
Main thread (UI)
- Renders chat; never blocks on heavy work
- Subscribes to token streams via MessageChannel or BroadcastChannel
- Provides model selection and settings (context length, quantization, energy profile)
-
Service Worker (orchestrator)
- Caches model shards and tokenizer assets via Cache Storage
- Handles offline-first fetch and streaming responses
- Brokers messages between UI and the Model Worker
- Implements token streaming as a ReadableStream to the page
-
Model Worker (compute)
- Owns WebGPU device and queues; isolates WGSL kernels
- Loads quantized weights from IndexedDB/OPFS
- Maintains the in-memory portion of the KV cache
- Implements speculative decoding with a lightweight draft model
- Exposes control messages (start/stop, temperature, top-p, max tokens)
-
Persistent storage
- IndexedDB or Origin Private File System (OPFS) for model shards and KV cache pages
- Optional encryption-at-rest via WebCrypto AES-GCM
-
Cloud
- Optional fallback endpoint (SSE/WS) for remote decoding or acceptance checks
- Policy-driven: e.g., fall back if TTFB > 500 ms for N consecutive tokens, or battery low
Data flow overview:
- UI sends a 'generate' request to the Service Worker.
- SW ensures assets are cached; it signals the Model Worker to begin decoding.
- Model Worker streams tokens to SW through a MessageChannel.
- SW multiplexes outputs into a ReadableStream response to the UI for immediate rendering.
- KV cache evicts old pages into IndexedDB; pages are rehydrated if the user scrolls context back in.
- If local decoding stalls or policy triggers, SW requests cloud continuation and merges remote tokens.
- Capability detection and progressive enhancement
Before anything else, detect what the browser can do and route accordingly:
html<script> (async () => { const hasWebGPU = !!navigator.gpu; const isIsolated = self.crossOriginIsolated === true; const adapter = hasWebGPU ? await navigator.gpu.requestAdapter({ powerPreference: 'high-performance' }) : null; const features = adapter ? Array.from(adapter.features) : []; // Minimal config gate for on-device path const canRunLocal = !!(hasWebGPU && isIsolated && adapter); // Fallback chain: WebGPU -> WASM (SIMD+Threads) -> Cloud let runtime = 'cloud'; if (canRunLocal) runtime = 'webgpu'; else if (WebAssembly && WebAssembly.validate) runtime = 'wasm'; console.log('Runtime:', runtime, 'Features:', features); })(); </script>
Key takeaways:
- WebGPU is required for practical throughput on 3B–7B models; WASM fallback is educational but slow.
- SharedArrayBuffer enables high-throughput worker messaging and certain WASM runtimes; it requires cross-origin isolation (next section).
- Not all devices have the same WebGPU limits (e.g., maxComputeWorkgroupSize, maxStorageBufferBindingSize). Query and adapt batch size, head_dim tiling, and quantization accordingly.
- Cross-origin isolation (COOP/COEP) for SharedArrayBuffer and performance
SharedArrayBuffer (SAB) is gated behind cross-origin isolation to mitigate Spectre-like risks. Enabling isolation also avoids subtle performance cliffs and enables more aggressive worker parallelism.
Set these HTTP response headers for all pages and JS/wasm assets (include Service Worker script too):
- Cross-Origin-Opener-Policy: same-origin
- Cross-Origin-Embedder-Policy: require-corp
And serve cross-origin subresources with:
- Cross-Origin-Resource-Policy: cross-origin (on the resource origin), or
- Proper CORS headers (Access-Control-Allow-Origin) if embedding remote assets
Example: Cloudflare Workers snippet to set headers globally
jsexport default { async fetch(req, env, ctx) { const res = await env.ASSETS.fetch(req); const newHeaders = new Headers(res.headers); newHeaders.set('Cross-Origin-Opener-Policy', 'same-origin'); newHeaders.set('Cross-Origin-Embedder-Policy', 'require-corp'); // If you serve cross-origin model shards, ensure they send CORP or CORS appropriately. return new Response(res.body, { headers: newHeaders, status: res.status }); } };
Verify at runtime:
jsif (!self.crossOriginIsolated) { alert('Cross-origin isolation is required. Check COOP/COEP headers.'); }
- Packaging quantized models for the web
Model selection
- Practical sweet spot: 3B–7B parameter decoder-only models for consumer laptops; 1–3B for high-end mobile.
- Quantization: int4/int8 group-wise quant with per-channel scales (e.g., AWQ, GPTQ, gGQ). Many community models exist in GGUF or custom shards.
- Tokenizer: BPE/Unigram packaged with fast WASM or JS tokenizer (e.g., Hugging Face tokenizers-wasm, web-compatible SentencePiece).
Sharding and compression
- Split weights into ~4–16 MiB shards to align with HTTP caching and faster resume.
- Pre-compress with Brotli (dictionary tuned if possible) or store uncompressed if you already use compact int4/int8 layouts.
- Store weight metadata (tensor shapes, quantization scales/zero-points) in a small JSON manifest.
Serving and caching
- Use Service Worker Cache Storage for first-level cache; mirror to IndexedDB or OPFS for persistence across SW updates.
- Consider integrity metadata (Subresource Integrity or manual SHA-256) to detect partial/corrupted caches.
Manifest example
json{ "format": "q4_0_groupwise", "d_model": 4096, "n_layers": 32, "n_heads": 32, "n_kv_heads": 8, "vocab_size": 32000, "max_seq_len": 4096, "group_size": 128, "tensors": [ { "name": "wq", "shape": [4096, 4096], "shards": ["wq.000.bin", "wq.001.bin"] }, { "name": "wk", "shape": [4096, 4096], "shards": ["wk.000.bin"] } ], "scales": { "wq": "wq.scales.bin", "wk": "wk.scales.bin" } }
Service Worker: pre-cache during install
jsself.addEventListener('install', (event) => { event.waitUntil((async () => { const cache = await caches.open('model-assets-v1'); await cache.addAll([ '/manifests/llm-q4.json', '/tokenizer.model', '/shards/wq.000.bin', '/shards/wq.001.bin', '/shards/wk.000.bin', '/scales/wq.scales.bin', '/scales/wk.scales.bin' ]); self.skipWaiting(); })()); });
Loading shards into the Model Worker
- Fetch via SW to enable offline.
- Stream decode into GPU buffers (queue.writeBuffer) or staging ArrayBuffers.
- Defer certain tensors (e.g., final projection) until first use to reduce TTFB.
- WebGPU inference pipeline essentials
A minimal on-device decoder step involves:
- Tokenize input; embed via table lookup
- For each layer:
- Compute Q, K, V projections (quantized GEMM)
- Update KV cache
- Attention: softmax(QK^T / sqrt(d_k)) V
- MLP feed-forward (quantized GEMM + activation)
- Final logits projection and sampling
Device setup and limits
jsconst adapter = await navigator.gpu.requestAdapter({ powerPreference: 'high-performance' }); const device = await adapter.requestDevice({ requiredFeatures: ['timestamp-query'].filter(f => adapter.features.has(f)), }); const limits = device.limits; // inspect maxStorageBufferBindingSize, etc.
WGSL: fused dequantize + matmul (int4 -> fp16) sketch
wgsl// Simplified: A (MxK, int4 packed), B (KxN, int4 packed), C (MxN, fp16) // Group-wise scales per 128 elements; real kernels tile MxN and vectorize loads. struct Params { M: u32, N: u32, K: u32, group_size: u32, }; @group(0) @binding(0) var<uniform> P: Params; @group(0) @binding(1) var<storage, read> A: array<u32>; // two int4 per byte => eight per u32 @group(0) @binding(2) var<storage, read> B: array<u32>; @group(0) @binding(3) var<storage, read> S_A: array<f32>; // scales @group(0) @binding(4) var<storage, read> S_B: array<f32>; @group(0) @binding(5) var<storage, read_write> C: array<f16>; fn unpack_nibble(x: u32, idx: u32) -> u32 { // idx in [0..7] let shift = (idx & 7u) * 4u; return (x >> shift) & 0xFu; // 0..15, map to signed later if symmetric } @compute @workgroup_size(8, 8, 1) fn main(@builtin(global_invocation_id) gid: vec3<u32>) { let m = gid.x; let n = gid.y; if (m >= P.M || n >= P.N) { return; } var acc: f32 = 0.0; for (var k: u32 = 0u; k < P.K; k += 8u) { // Load 8 values from A and B (packed into one u32 each) let a_pack = A[(m * (P.K / 8u)) + (k / 8u)]; let b_pack = B[(n * (P.K / 8u)) + (k / 8u)]; for (var i: u32 = 0u; i < 8u; i++) { let a4 = f32(unpack_nibble(a_pack, i)); let b4 = f32(unpack_nibble(b_pack, i)); // Apply per-group scales let ga = (m * P.K + (k + i)) / P.group_size; let gb = (n * P.K + (k + i)) / P.group_size; let a = (a4 - 8.0) * S_A[ga]; // symmetric int4 centered at 0 let b = (b4 - 8.0) * S_B[gb]; acc += a * b; } } let idx = m * P.N + n; C[idx] = f16(acc); }
Production kernels use shared memory tiling, vectorized loads, and fuse bias/activation for the MLP to reduce memory traffic. If you are not building kernels from scratch, consider:
- MLC LLM (web-llm): End-to-end WebGPU LLM runtime with models packaged for the browser.
- onnxruntime-web with WebGPU: ONNX graph execution in-browser; supports attention ops and IO binding.
- llama.cpp WebGPU builds compiled to WASM + WebGPU (some community ports).
Sampling and streaming
- Run one token at a time to enable streaming; micro-batch if your device supports it (batch=2–4) to amortize overhead.
- Compute time-to-first-token (TTFT) and tokens-per-second (TPS) live.
tsfunction sample_logits(logits: Float32Array, temperature = 0.8, top_p = 0.9) { // Implement nucleus sampling; keep deterministic path for temp=0 // Omitted for brevity }
- KV-cache memory math and paging with IndexedDB/OPFS
Why paging?
The KV cache quickly becomes the dominant memory consumer. For a 7B model, 32 layers, d_model 4096, n_kv_heads 8, head_dim 128, float16 KV:
- Per token per layer: K and V each ~ n_kv_heads * head_dim * 2 bytes = 8 * 128 * 2 = 2 KiB; doubled for K+V = 4 KiB
- Across 32 layers: ~128 KiB per token
- For 4096 tokens: ~512 MiB just for KV (fp16). Quantizing KV to int8 halves this (~256 MiB). On laptops this is workable; on mobile, not.
Strategy
- Keep a hot window (e.g., last 512–1024 tokens) in GPU buffers for speed.
- Page older KV entries to disk (IndexedDB or OPFS) as compressed int8/int4 blocks.
- Rehydrate when attention score indicates need (e.g., retrieval augmented prompts) or when user scrolls context back in.
- Combine with a sliding context window (e.g., 4k) and compressive summarization of much older text.
Storage choice
- IndexedDB is ubiquitous and supports binary Blobs and ArrayBuffers.
- OPFS (Origin Private File System) offers near-native filesystem semantics and better write throughput, especially with the SyncAccessHandle in workers.
Schema example (IndexedDB)
ts// Create DB stores: 'weights', 'kv_pages' const req = indexedDB.open('agent-db', 1); req.onupgradeneeded = () => { const db = req.result; db.createObjectStore('weights'); const kv = db.createObjectStore('kv_pages', { keyPath: 'id' }); kv.createIndex('by_layer', 'layer'); }; function putKVPage(db: IDBDatabase, page: { id: string; layer: number; start: number; end: number; data: ArrayBuffer }) { return new Promise<void>((resolve, reject) => { const tx = db.transaction('kv_pages', 'readwrite'); tx.objectStore('kv_pages').put(page); tx.oncomplete = () => resolve(); tx.onerror = () => reject(tx.error); }); }
KV page format
- Key:
${sessionId}:${layer}:${startToken}-${endToken} - Data: int8 buffer (K then V) with per-channel scales; compress with Brotli or leave raw if already 8-bit
- Metadata: shape, scale offsets for quick rehydrate
GPU rehydrate sketch
ts// Map page from IDB -> ArrayBuffer -> queue.writeBuffer to GPU buffer slice async function hydrateKV(device: GPUDevice, buf: GPUBuffer, offset: number, pageData: ArrayBuffer) { device.queue.writeBuffer(buf, offset, pageData); }
Policy
- Evict to disk when KV > threshold (e.g., 70% of allowed GPU memory)
- Pin the newest N tokens per layer
- If a token depends on evicted KV range, either:
- Rehydrate before the next attention matmul; or
- Use a summarization cache to avoid random rehydration on every step
Note: Full paged attention (a la vLLM) requires kernels designed for sparse KV. In-browser, a pragmatic approach is hybrid: fixed hot window + cold summarization. Experimental implementations can tile attention over hot+rehydrated blocks with additional synchronization cost.
- Service Worker orchestration and token streaming
Route all IO through the SW to unify offline caching, token streaming, and cloud fallback.
Bidirectional messaging
ts// UI -> SW navigator.serviceWorker.controller.postMessage({ type: 'generate', prompt, settings }); // SW -> UI via MessageChannel const channel = new MessageChannel(); navigator.serviceWorker.controller.postMessage({ type: 'streamRequest' }, [channel.port2]); channel.port1.onmessage = (ev) => { const { type, token } = ev.data; if (type === 'token') appendToUI(token); };
SW <-> Model Worker
ts// In SW: spawn a dedicated Model Worker let modelWorker; self.addEventListener('activate', () => { modelWorker = new Worker('/workers/model.js', { type: 'module' }); }); // Relay generation requests self.addEventListener('message', (ev) => { const msg = ev.data; if (msg.type === 'generate') { modelWorker.postMessage(msg); } else if (msg.type === 'streamRequest') { // Keep msg.port as sink for tokens const port = ev.ports[0]; modelWorker.postMessage({ type: 'attachStream' }, [port]); } });
In the Model Worker
tslet streamPort: MessagePort | null = null; self.onmessage = async (ev) => { const msg = ev.data; if (msg.type === 'attachStream') { streamPort = ev.ports[0]; } else if (msg.type === 'generate') { const { prompt, settings } = msg; for await (const token of generateTokens(prompt, settings)) { streamPort?.postMessage({ type: 'token', token }); } streamPort?.postMessage({ type: 'eos' }); } };
ReadableStream to the page
You can also expose a fetchable stream path (e.g., /stream) to let the UI consume tokens with the Fetch Streams API.
tsself.addEventListener('fetch', (event) => { const url = new URL(event.request.url); if (url.pathname === '/stream') { event.respondWith(new Response(new ReadableStream({ start(controller) { const port = new MessageChannel(); port.port1.onmessage = (ev) => { const { type, token } = ev.data; if (type === 'token') controller.enqueue(new TextEncoder().encode(token)); if (type === 'eos') controller.close(); }; modelWorker.postMessage({ type: 'attachStream' }, [port.port2]); } }), { headers: { 'Content-Type': 'text/plain; charset=utf-8' } })); } });
- Speculative decoding in the browser
Speculative decoding uses a small draft model to propose k tokens; the larger target model verifies them in parallel. If the target model agrees on the next token(s), you accept multiple tokens at once; otherwise, you roll back to the earliest mismatch.
Why it matters
- In browsers, kernel launch overhead and JS<->GPU synchronization are non-trivial. Accepting multiple tokens amortizes these costs.
- The draft model can be 4–10× smaller, running very fast on-device.
Algorithm outline
- Run draft model for k steps to produce candidate sequence c1..ck.
- Run target model conditioned on original context to compute p1..pk logits.
- Find the longest prefix where argmax(p_i) = c_i (or accept under top-k probability threshold).
- Accept that prefix; append to output; continue with remaining.
Sketch
tsasync function* speculativeDecode(draft, target, ctx, k = 4) { while (true) { const candidates = await draft.propose(ctx, k); // returns tokens c1..ck const verdicts = await target.verify(ctx, candidates); // logits or top1 per step let accept = 0; for (let i = 0; i < candidates.length; i++) { if (verdicts[i].top1 === candidates[i]) accept++; else break; } if (accept === 0) { // Fallback: generate one token with target const t = await target.next(ctx); ctx.push(t); yield t; } else { for (let i = 0; i < accept; i++) { ctx.push(candidates[i]); yield candidates[i]; } } if (ctx.length >= ctx.maxLen) return; } }
Local choices
- Draft: a 700M–1.1B LLM with aggressive int4 quantization; target: 3B–7B.
- For very constrained devices, draft-only decoding plus cloud validation can be effective.
Acceptance policy
- Argmax equality is the simplest; you can also accept if the candidate token probability under the target is above a threshold or in top-k.
- Dynamically adjust k based on observed acceptance ratio and device TPS.
- Hybrid edge-cloud continuation and merging
Even with WebGPU, some tasks or devices will struggle. A hybrid pipeline keeps UX smooth and respects privacy budgets.
Fallback triggers
- TTFT exceeds threshold (e.g., > 800 ms) or TPS below target for N tokens
- Device power constraints (user opted into energy saver profile)
- Model features unavailable (e.g., long context > local limit)
Continuation API (server-side)
- Provide an endpoint that accepts current prompt + partial output, returns an SSE/WS stream of tokens.
- To protect privacy, send only the minimal prefix necessary (e.g., hashed embeddings, or a redacted summary). For true privacy, only route when the user consents.
Merging streams in SW
tsasync function hybridStream(ctx, localStream, remoteUrl) { const controller = new AbortController(); const remote = fetch(remoteUrl, { method: 'POST', body: JSON.stringify({ prompt: ctx }), signal: controller.signal }); const enc = new TextEncoder(); const rs = new ReadableStream({ async start(c) { const reader = (await remote).body.getReader(); let localDone = false, remoteDone = false; const localPump = (async () => { for await (const t of localStream) { if (remoteDone) break; c.enqueue(enc.encode(t)); } localDone = true; })(); const remotePump = (async () => { while (true) { const { value, done } = await reader.read(); if (done) break; c.enqueue(value); } remoteDone = true; })(); await Promise.race([localPump, remotePump]); // Policy: prefer the faster stream; cancel the slower one controller.abort(); c.close(); } }); return rs; }
Other hybrid patterns
- Acceptance-as-a-service: run draft locally, send candidates to cloud target for verification; server returns accept prefix length.
- Layer-splitting is theoretically possible (early offload), but round-trips per token often dominate.
- Latency, throughput, memory, and energy profiling
Metrics to capture on every session
- TTFT (ms): from user press to first token displayed
- TPS (tokens/sec): rolling average and p50/p90
- GPU memory allocated: from device.limits and your buffers; track hot KV size
- CPU/GPU time per kernel: via WebGPU timestamp queries where available
- Cache hit rates: weight shard cache, KV page rehydrate rates
- Cloud fallback rate
WebGPU timestamps (if supported)
tsfunction withGpuTiming(device, encoder, fn) { const qs = device.createQuerySet({ type: 'timestamp', count: 2 }); const pass = encoder.beginComputePass(); pass.writeTimestamp(qs, 0); fn(pass); pass.writeTimestamp(qs, 1); pass.end(); const buf = device.createBuffer({ size: 16, usage: GPUBufferUsage.COPY_DST | GPUBufferUsage.MAP_READ }); encoder.resolveQuerySet(qs, 0, 2, buf, 0); return buf.mapAsync(GPUMapMode.READ).then(() => new BigUint64Array(buf.getMappedRange()).slice()); }
Energy approximation
- The Battery Status API is largely deprecated, but navigator.getBattery may exist in some Chromium builds. Treat it as best-effort and optional.
- Approximate energy by correlating TPS and GPU busy time; on laptops, OS task managers can display per-process GPU usage, which you can sample manually during testing.
- Implement user-selectable profiles: performance (max TPS), balanced, battery saver (lower powerPreference, smaller k for speculative decode, cap context length).
Example best-effort battery read
tsif (navigator.getBattery) { const battery = await navigator.getBattery(); console.log('Battery level', battery.level, 'charging', battery.charging); }
PerformanceObserver for long tasks and memory
tsnew PerformanceObserver((list) => { for (const e of list.getEntries()) { if (e.entryType === 'longtask') console.warn('Long task', e); } }).observe({ entryTypes: ['longtask'] }); if (performance.measureUserAgentSpecificMemory) { const mem = await performance.measureUserAgentSpecificMemory(); console.log('UA memory breakdown', mem); }
Report block
- Persist anonymized metrics to IndexedDB for local charts; ask user consent for remote telemetry.
- Compare local vs cloud TPS to guide fallback tuning.
- Privacy, security, and encryption-at-rest
On-device inference already confers strong privacy benefits, but you must still treat caches as sensitive.
- Do not store raw prompts or chat logs unencrypted in IndexedDB.
- Encrypt KV pages and model shards at rest if the threat model includes local disk adversaries (e.g., shared machines).
- Pin Service Worker version to avoid cache poisoning; verify model shard integrity with checksums.
- Use crossOriginIsolated; avoid leaky side channels by using fixed-size message chunks when feasible.
Encrypting a KV page with WebCrypto AES-GCM
tsasync function getOrCreateKey() { // Store a wrapKey in IndexedDB; avoid exporting raw keys when possible let key = await crypto.subtle.generateKey({ name: 'AES-GCM', length: 256 }, true, ['encrypt', 'decrypt']); return key; } async function encrypt(buf, key) { const iv = crypto.getRandomValues(new Uint8Array(12)); const ct = await crypto.subtle.encrypt({ name: 'AES-GCM', iv }, key, buf); return { iv, ct }; } async function decrypt(ct, iv, key) { return await crypto.subtle.decrypt({ name: 'AES-GCM', iv }, key, ct); }
If you need maximum privacy, avoid cloud fallback or add explicit consent gates and clear visual indicators.
- Building blocks you can reuse
- Tokenizer: tokenizers-wasm (WASM SIMD) or @xenova/transformers (web-friendly pipelines)
- Runtime frameworks: MLC LLM (web-llm), onnxruntime-web (webgpu), llama.cpp ports
- Storage helpers: idb-keyval, OPFS APIs (File System Access in workers)
- Scheduling: Worklets are not needed; Dedicated Workers suffice; use BroadcastChannel for multi-tab coordination
- Testing matrix and expected performance ranges
Devices vary wildly. A pragmatic testing grid:
- High-end laptop (discrete GPU): 7B int4 with TTFT ~200–500 ms, TPS 20–60
- Integrated GPU (e.g., recent Apple/M-series, Intel Xe): 3B–7B int4, TTFT ~300–900 ms, TPS 10–30
- High-end mobile (Android w/ Chrome 121+): 1–3B int4, TTFT ~500–1500 ms, TPS 3–10
These are directional only; real numbers depend on kernels, memory bandwidth, and quantization scheme.
Test scenarios
- Cold start (no caches) vs warm start (weights + KV hot)
- Long prompt (2–4k tokens) with paged KV and hot window
- Speculative decoding on/off; measure acceptance ratios and end-to-end speedup
- Cloud fallback trigger validation (induce slowness and verify merge correctness)
Correctness tests
- Logits parity against a reference CPU/torch run on short sequences
- Temperature=0 greedy decoding reproducibility across runs and devices
- Pitfalls and debugging advice
- Feature mismatches: Not all WebGPU backends support the same limits; query device.limits and plan tensor tiling appropriately.
- WGSL precision: Prefer f16 storage but accumulate in f32 where numerically sensitive (softmax). Verify underflow/overflow.
- Cross-origin isolation: Missing COOP/COEP is the #1 cause of SAB and WASM threads not working. Validate early.
- IndexedDB quotas: Large model caches may hit quota prompts; prefer OPFS where available; allow users to manage caches.
- Streaming UX: Render tokens incrementally with stable layout; debounce autoscroll; handle bidi scripts properly.
- GPU watchdogs: Very long-running compute passes may trigger driver resets; keep per-pass work bounded and incremental.
- Mobile thermal throttling: Monitor TPS drift; dynamically reduce k or switch to battery saver mode.
- Putting it all together: a minimal boot sequence
ts// main.ts await ensureSWRegistered(); await ensureIsolated(); const runtime = await chooseRuntime(); postMessageToSW({ type: 'prepare', model: 'llm-3b-q4' }); document.querySelector('#go').addEventListener('click', async () => { const prompt = (document.querySelector('#prompt') as HTMLTextAreaElement).value; const channel = new MessageChannel(); channel.port1.onmessage = (e) => renderToken(e.data.token); navigator.serviceWorker.controller.postMessage({ type: 'streamRequest' }, [channel.port2]); navigator.serviceWorker.controller.postMessage({ type: 'generate', prompt, settings: { temp: 0.8, top_p: 0.9 } }); });
ts// service-worker.ts self.addEventListener('install', (e) => self.skipWaiting()); self.addEventListener('activate', (e) => self.clients.claim()); let modelWorker: Worker | null = null; self.addEventListener('message', (ev) => { const msg = ev.data; if (msg.type === 'prepare') { if (!modelWorker) modelWorker = new Worker('/workers/model.js', { type: 'module' }); modelWorker.postMessage(msg); } else if (msg.type === 'generate') { modelWorker?.postMessage(msg); } else if (msg.type === 'streamRequest') { modelWorker?.postMessage({ type: 'attachStream' }, [ev.ports[0]]); } });
ts// workers/model.ts let port: MessagePort | null = null; let device: GPUDevice; self.onmessage = async (ev) => { const msg = ev.data; if (msg.type === 'attachStream') { port = ev.ports[0]; } if (msg.type === 'prepare') { const adapter = await navigator.gpu.requestAdapter({ powerPreference: 'high-performance' }); device = await adapter.requestDevice({}); await loadWeightsAndTokenizer(); } if (msg.type === 'generate') { const { prompt, settings } = msg; for await (const t of decodeWithSpeculation(prompt, settings)) { port?.postMessage({ type: 'token', token: t }); } port?.postMessage({ type: 'eos' }); } };
- Opinionated guidance
- Do not ship a single monolithic 7B model to every device. Gate model size by capability detection and let the user opt into heavier downloads.
- Always enable cross-origin isolation in production. The friction of COOP/COEP is worth the stability and performance wins.
- Treat paged KV as a tool of last resort. A fast sliding window (512–1024) plus summarization covers many use cases without constant disk churn.
- Speculative decoding pays off faster in the browser than on server GPUs due to higher relative overhead per token. Start with k=2–4 and adapt.
- Make cloud fallback explicit and respectful. Default to local-only for privacy; expose a single toggle that changes behavior immediately.
- Invest in measurement infrastructure early. Without TPS/TTFT/acceptance ratio dashboards, you will be tuning blind.
- References and further reading
- WebGPU specification and MDN docs
- MLC LLM (web-llm): https://github.com/mlc-ai/web-llm
- ONNX Runtime Web (WebGPU): https://github.com/microsoft/onnxruntime/tree/main/js/web
- vLLM and paged attention concepts: https://github.com/vllm-project/vllm (server-side reference)
- llama.cpp: https://github.com/ggerganov/llama.cpp
- IndexedDB: MDN IndexedDB API
- OPFS: MDN File System Access API (Origin Private File System)
- Cross-origin isolation: MDN COOP/COEP guides
Conclusion
With WebGPU, the browser is no longer a toy runtime for LLMs. By packaging quantized models, enabling cross-origin isolation for SharedArrayBuffer, and orchestrating decoding via Service Workers and dedicated Workers, you can deliver responsive, private, and offline-capable AI agents entirely on-device. Paged KV caching stretches context length without exhausting memory; speculative decoding amortizes per-token costs; and a well-engineered cloud fallback ensures that users on weaker devices are never left behind.
You do not need to build every kernel yourself. Start with a mature web LLM runtime, layer on your Service Worker orchestration, implement capability-based model selection, and wire in measurement from day one. The result is a credible, production-ready experience: low TTFT, steady TPS, strong privacy guarantees, and a clear path to scale via hybrid edge-cloud execution.