Label, train, and deploy
AI browser agents
Training LLMs is solved. Training BROWSER AGENTS? That's the frontier. The only platform providing training data, validation, and deployment for browser, desktop, and GUI agents.
Browser agents fail. You have no idea why.
Building browser agents without visibility, training data, or benchmarks means shipping blind and improving by luck.
Failures are opaque
Are your browser agents getting stuck on captchas or silently failing on page loads? Without action-level tracing across browser sessions you're debugging blind, guessing at prompts, and hoping the next run works.
No training data
No way to capture what your agent actually did, label which actions were correct, or build datasets from real sessions. You're improving by instinct, not evidence.
Improvement is unmeasurable
You change the prompt. Is the agent better? Worse? There's no baseline. No version history. No way to A/B test GPT-4 against Claude on the same browser workflow. "V2 feels worse" is not a metric.
Built by the team behind Debugg.ai — 800+ users, 10,000+ agent tests/week
The complete lifecycle for action-based agents
Label action sequences. Train on real interactions. Validate multi-step flows. Deploy with confidence.
Label
Record and annotate agent actions automatically. Capture every action in the flow. Label success/failure at action-level. Build datasets of action sequences.
Train
Training data for action sequences (not just text). Clean, labeled datasets ready for fine-tuning. RLHF workflows for agent behavior. We're creating CommonCrawl for actions.
Deploy
Sandbox → Staging → Production with safety. Test in isolated environments. CI/CD for agent updates. Canary rollouts for behavior changes.
Eval
Validate 49/50 vs 50/50 correct actions. Action-level validation (not just outcomes). Behavioral testing (did it take the right path?). Version control for agent behavior.
The complete lifecycle in code
Label, train, deploy, and eval—all integrated. From action recording to production deployment in one platform.
import { Surfer, Dataset, Eval } from '@surfs/sdk'
// 1. Label: Record and annotate actions
const session = await Surfer.record({
task: "Add item to cart",
captureActions: true,
labelSuccess: true
})
// 2. Train: Build dataset from labeled actions
const dataset = await Dataset.create({
sessions: [session],
format: "action-sequences"
})
// 3. Deploy: Test in sandbox before production
await Surfer.deploy({
environment: "sandbox",
canary: 0.1 // 10% rollout
})
// 4. Eval: Validate 50/50 actions, not 49/50
const results = await Eval.run({
validateEachAction: true,
compareToBaseline: true
})The complete agent lifecycle: Label → Train → Deploy → Eval, all in one SDK.
See what your agent is thinking
Every action starts with an LLM decision. Track reasoning → execution, not just raw actions. Debug failures at the decision level.
run_a3f9e2b8 · 47.3s · 12 steps
goto("https://shop.example.com")click("#search-button")fill("input[name=q]", "red t-shirt")click(".add-to-cart-btn")Latest Resources
Stay updated with the latest insights, guides, and best practices for AI-powered development and testing.
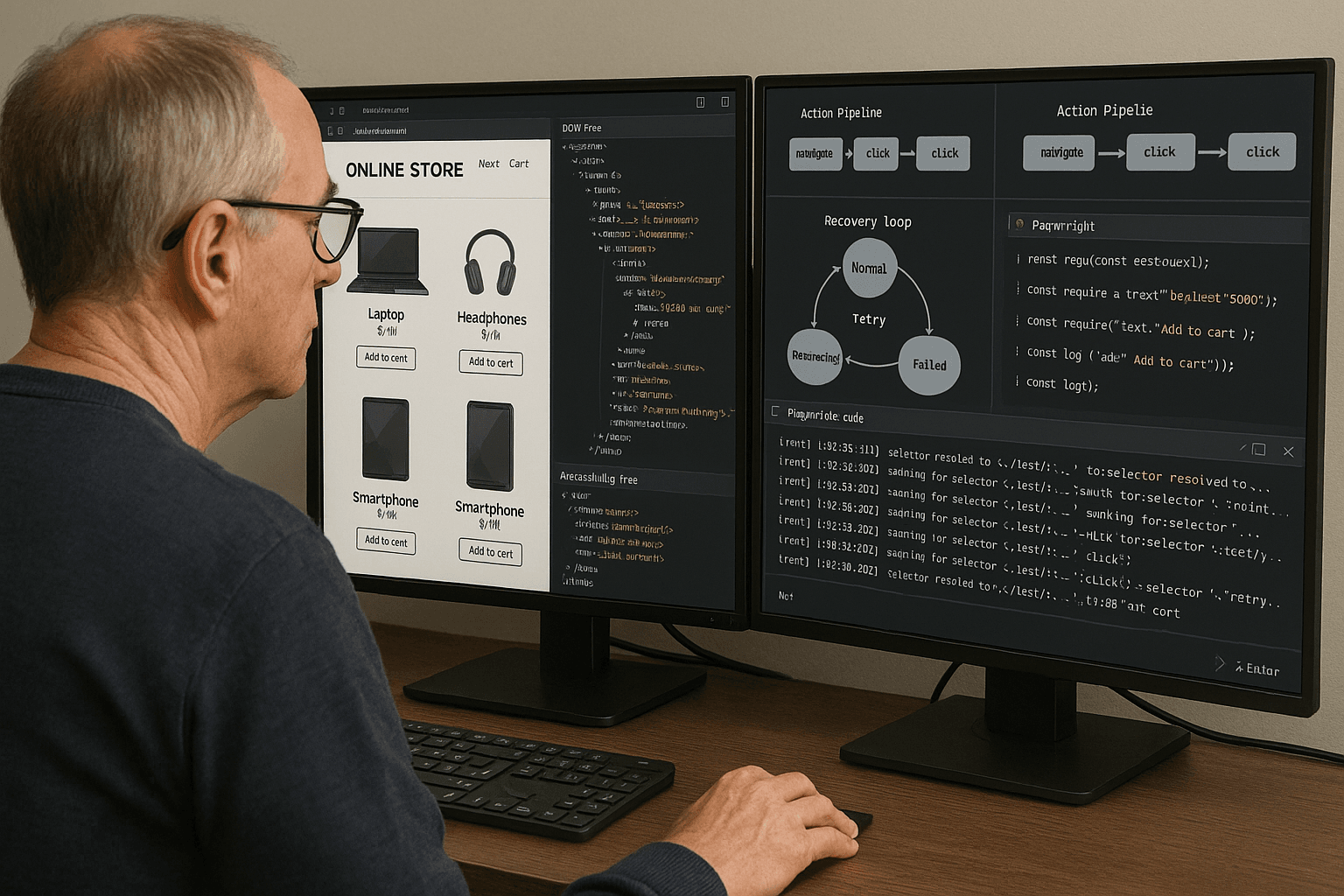
Building Deterministic Browser Agents: DOM-Aware Planning, Action Validation, and Recovery Loops
How to build production browser agents with stable targeting, validated actions, replay data, recovery loops, and headless-safe execution for shopping, booking, and extraction workflows.
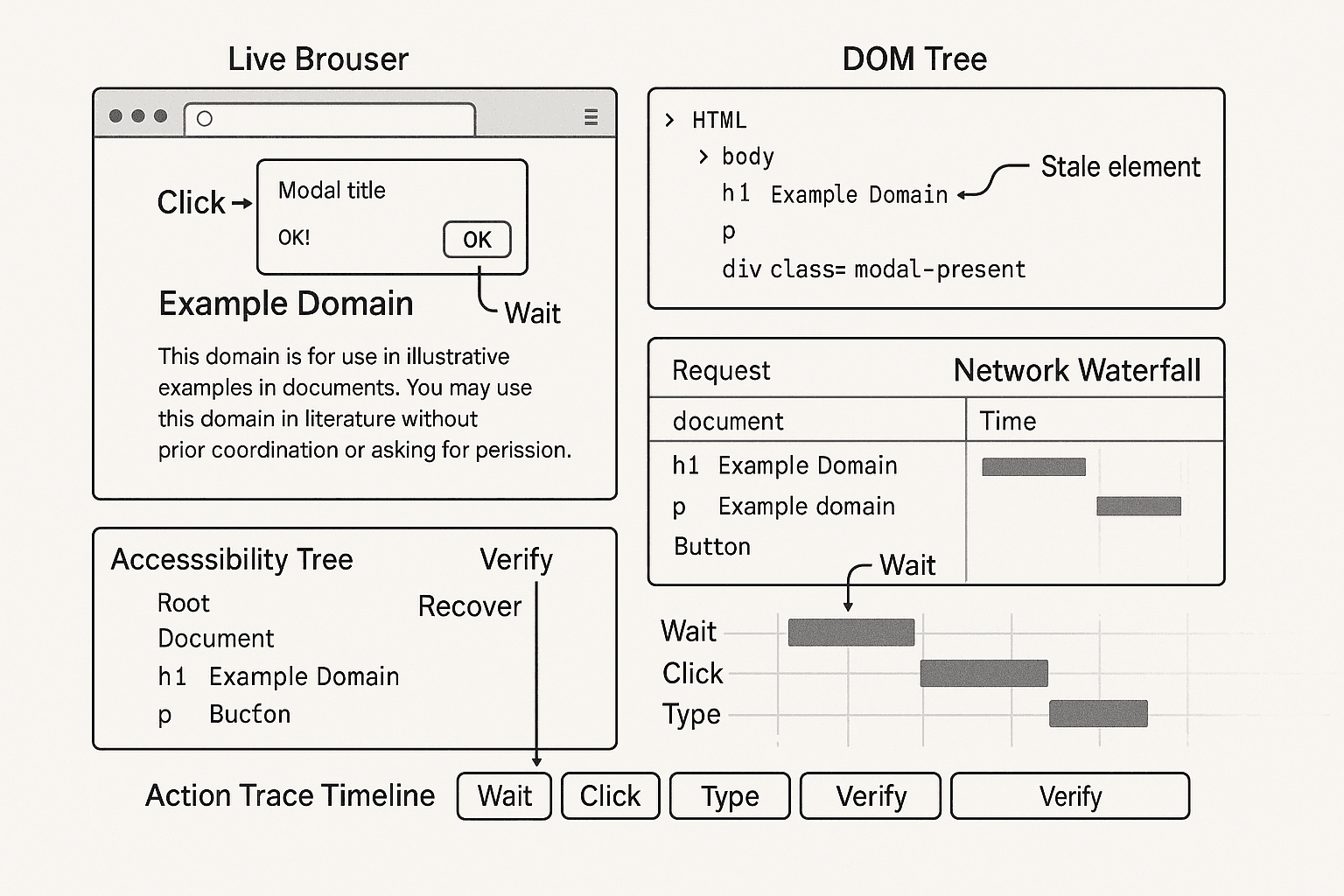
Execution Traces for Browser Agents: Mining Step-Level Recovery Data from Human Browsing to Train Reliable Action Policies
A practical blueprint for collecting execution traces from real browsing, converting them into step-wise training data, and using them to build browser agents that recover from dynamic DOM failures in production.
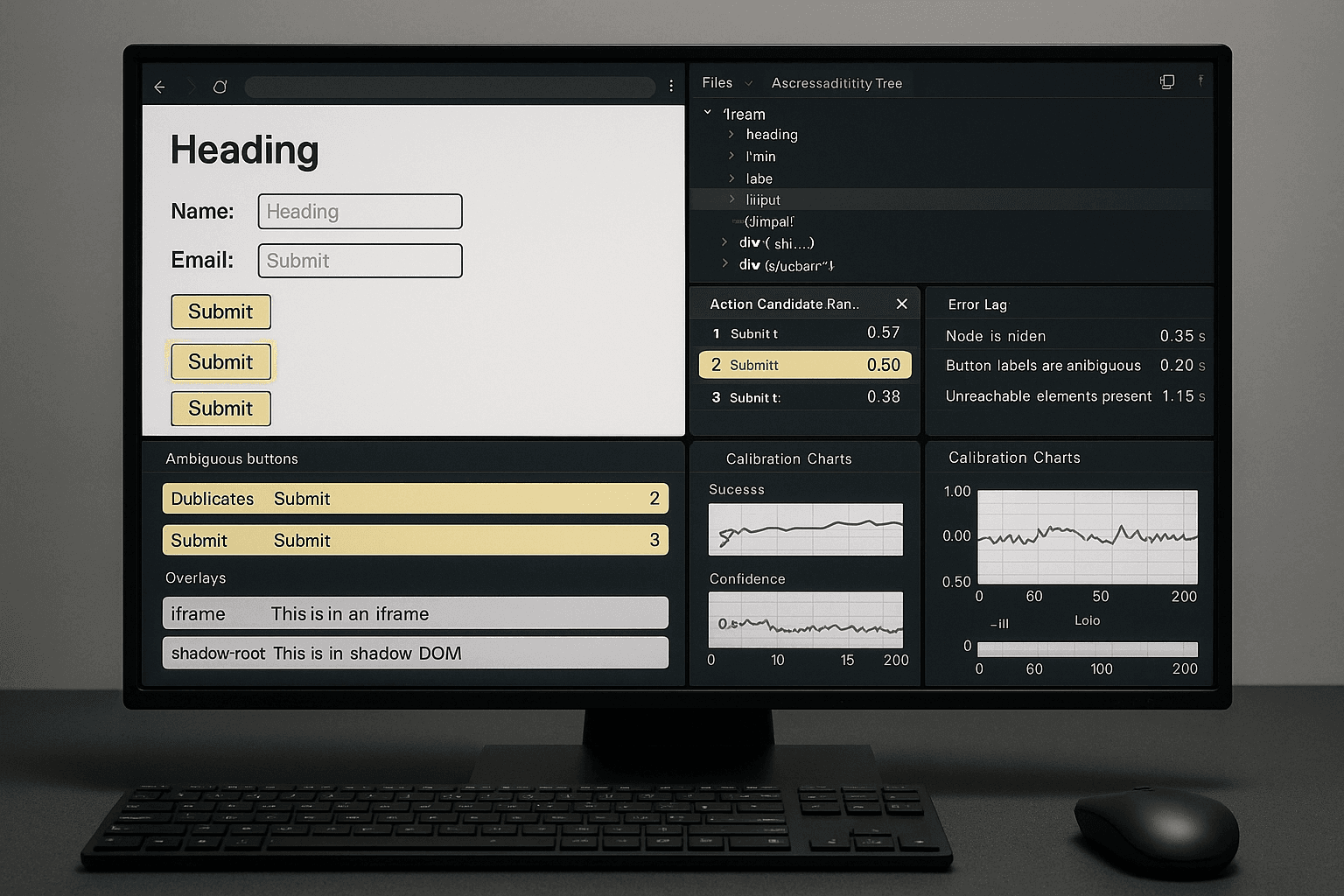
Hard-Negative Mining for Browser Agents: Training on Ambiguous DOMs, Near-Miss Actions, and Recovery-Critical Failures
A practical blueprint for mining hard negatives from browser sessions to train safer action selectors, rerankers, and recovery loops on ambiguous DOMs and near-miss failures.
Looking for PR-focused browser testing?
Try DebuggAI PR Copilot